The major high energy physics
experiments now underway, and especially the Large Hadronic Collider (LHC)
experiments now in preparation, present new challenges in Petabyte-scale data
processing, storage and access, as well as multi-Gigabit/sec networking.
The Compact Muon Solenoid (CMS)
experiment is taking a leading role among the LHC experiments in helping to
define the Grid architecture, building Grid software components, integrating
the Grid software with the experiment's software framework, and beginning to
apply Grid tools and services to meet the experiment's key milestones in
software and computing, through the GriPhyN [[1]], PPDG [[2]] and European Data Grid
projects [[3],4].� Within the past year, prototype Tier 2
centers have been installed at Caltech, San Diego and Florida [5], and have
entered production status, in concert with the Tier 1 prototype center at
Fermilab, so providing a substantial portion of the simulated and reconstructed
events used by the worldwide CMS collaboration.
Until now, the Grid architecture
being developed [6,7,8,10,11] has focused on sets of files and on the
relatively well-ordered large-scale production environment. Considerable effort
is already being devoted to preparation of Grid middleware and services (this
work being done largely in the context of the PPDG, GriPhyN, EU DataGrid and
LHC Computing Grid projects). The problem of how processed object collections,
processing and data handling resources, and ultimately physics results may be obtained
efficiently by global physics collaborations has yet to be tackled head on.
Developing Grid-based tools to aid in solving this problem within the next two
to three years, and hence beginning now to understand the new concepts and
foundations of the (future) solution, is essential if the LHC experiments are
to be ready for the start of LHC running.
The current view of CMS�s
computing and software model is well developed, and is based on use of the Grid
to leverage and exploit a set of computing resources that are distributed
around the globe at the collaborating institutes. CMS has developed analysis
environment prototypes based on modern software tools, chosen from both inside
and outside High Energy Physics. These are aimed at providing an excellent
capability to perform all the standard data analysis tasks, but assume full
access to the data, very significant local computing resources, and a full
local installation of the CMS software. With these prototypes, a large number
of physicists are already engaged in detailed physics simulations of the
detector, and are attempting to analyze large quantities of simulated data.
The advent of Grid computing,
the size of the US-based collaboration, and the expected scarcity of resources
lead to a pressing need for software systems that manage resources, reduce
duplication of effort, and aid physicists who need data, computing resources,
and software installations, but who cannot have all they require locally
installed.
We thus propose to develop an
interactive Grid-enabled analysis environment for physicists
working on the CMS experiment. The environment will be lightweight yet highly
functional, and make use of existing and future CMS analysis tools as plug-in
components. It will consist of tools and utilities that expose the Grid system
functions, parameters and behavior at selectable levels of detail and
complexity. The Grid will be exposed in this way by making use of Web Services,
which will be accessed using standard Web protocols. A physicist will be able
to interact with the Grid to request a collection of analysis objects[*], to monitor the process of
preparation and production of the collection and to provide "hints"
or control parameters for the individual processes. The Grid enabled analysis
environment will provide various types of feedback to the physicist, such as
time to completion of a task, evaluation of the task complexity, diagnostics
generated at the different stages of processing, real-time maps of the global
system, and so on. We believe that only by exposing this complexity can an
intelligent user learn what is reasonable in the highly constrained global
system we expect to have. We expect the analysis environment we create to have
immediate and long term benefit to the CMS collaboration.
C.1.b. Problem Statement: The Development of Grid Technology for Analysis
C.2.a. The Grid-Enabled Physics Analysis Desktop
C.3.����� Existing
Activities Synergistic with this Proposal
C.4.����� Relationship
to Other Projects
C.5.����� Complementary
Proposals
C.6.����� Schedules
and Milestones
C.7.����� Outreach
and Education
C.7.a. Advancing Knowledge in Computer Science and Computational Science Disciplines
C.7.b. Educational Merit:� Advancing Discovery and Access for Minority Students
C.8.����� Results
from Prior NSF Support
G.�� Current
and Pending Support
H.�� Facilities.
Equipment and Other Resources
I.���� Special
Information and Supplementary Resources
I.1. List of
Institutions and Personnel
Enabling end user physicists to analyze physics data from the
CMS experiment in a timely and efficient manner is an essential component to
the success of the experiment as a whole. The scale of the computing and
networking challenge posed by the LHC experiments is well known and documented
elsewhere, but in summary it involves an accumulation of many PetaBytes of
"raw", reconstructed and simulated event data per experiment, per
year. CMS has addressed the computing challenge by adopting a distributed
�Tiered� computing model, in which one-third of the total computing resources
are located at the CERN Tier 0 center; one-third are located at five Tier 1
facilities (one of which is situated at Fermilab), and the final third is
spread over approximately twenty-five Tier 2 facilities. The US Tier2
prototypes are located in California and Florida[5].� Figure
1 shows the locations of our institutes and their
connections to the CalREN2 and Internet2 networks.
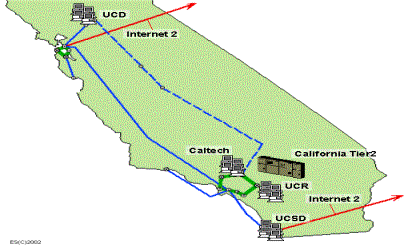
Figure 1:
Showing the WAN links between the US-CMS Computing Facilities at Caltech, UCD,
UCR and UCSD. The rings in the Los Angeles and San Francisco areas operate at
OC12. The regional connections operate at OC48. The dashed line denotes a
planned OC12 connection.
Developing the infrastructure for the distribution and
management of these large scale distributed productions is an area covered by
projects in which we are playing key roles. These include the DoE-funded
"Particle Physics Data Grid�[2], the NSF-funded "Grid Physics
Network"[1], the NSF-funded "international Virtual Data Grid
Laboratory"[17], and the NSF-funded "TeraGrid"[20].
CMS relies heavily on the regional centers to meet the
growing need for high quality event simulation, crossing digitization, and
reconstruction.� Currently, the US
centers are making a significant contribution to the overall CMS production
effort and have begun to make use of Grid developed prototype tools to improve
efficiency.�
By the start of the experiment the Tier 1 and Tier 2
facilities are expected to be the primary location for physics analysis,
providing physics users with responsive computing resources.� The storage planned at the Tier 2 facilities
will not allow the complete data set to be stored, so tools to automate data
access and remote submission will be required.�
Moreover, physicists who are not situated near Tier 1 or Tier 2 centers
will also need a responsive and efficient analysis system.
While considerable progress has been made in developing Grid
prototypes for the CMS production system, tools to support and facilitate
remote analysis are still in their infancy. In particular, tools and guidelines
for obtaining transparent access to the data and for enabling interaction
between the user and the Grid are essential, but do not exist. CMS has made and
will continue to make strong progress on local analysis tools: the Grid-based
interactive analysis system we propose will enhance and build upon these tools.
C.1.a.
Current Status in CMS
CMS has successfully developed
prototype Object Oriented simulation and reconstruction programs, complete with
object databases. This �functional prototype� software phase has now finished.
The design for the next phase of fully functional software is in progress. The
collaboration has developed and is using a software tool called COBRA[7], which
is a framework in which all developed code can be coherently used. The
supported codes include simulation, reconstruction, analysis and visualization
software.
CMS has successfully integrated Grid tools
to form a rudimentary worldwide distributed production environment. Simulated
events have been reliably generated in a distributed manner at 12 production
centers worldwide. File replication between production centers uses the tools
from the Grid Data Mirroring Project ("GDMP") [4]. Production
requests are currently being implemented with the virtual data specification
language developed by GriPhyN. CMS has been able to strike a balance between
the general need of serving a testbed for distributed computing development and
the more specific need of running the experiment production.
The CMS Collaboration has an ambitious
program of work to prepare for the start of running in 2006[6]. Between now
and the start of the experiment, tens to hundreds of millions of fully
reconstructed simulated events are needed.�
In the first six months of 2002 the available simulated dataset will
approximately double in preparation for the completion of the Data Acquisition
System Technical Design Report (TDR) in late 2002.� Simulation and analysis validation is
required to complete the Computing TDR in 2003. In late 2003 the data
challenges begin with the 5% data challenge. For these challenges, the entire
data chain from raw data, through triggering, to output and finally analysis
will be tested. In 2004 the Physics TDR will be submitted. To complete the
Physics TDR, a detailed analysis of most of the interesting physics channels
will be performed. Finally, in 2004, the 20% data challenge will be completed,
in which a 20Hz trigger rate will be simulated and analyzed for a month. In
order for any of these TDR�s to be useful the system used for production and
analysis must closely resemble the final deployed system. To complete the
Physics TDR in 2004 the analysis must start no later than 2003, so useful
prototype analysis tools need to be delivered to physics groups in the next 12
to 18 months.
As part of its Grid requirements [10], CMS has defined a
baseline for the interaction between analysis tools and the data Grid system.
According to this baseline, the tools can call on the Grid via specialized
plug-ins.� The baseline services available
to the tools will be Grid batch job execution and Grid file staging.� This baseline model determines the scope of
the Grid projects PPDG, GriPhyN, and the EU DataGrid until the end of 2003 --
the projects focus mainly on middleware and (batch) production jobs: they do
not have the resources to go much beyond the minimal analysis baseline.
C.1.b.
The
Development of Grid Technology for Analysis
This proposal focuses on driving the analysis support beyond
the baseline of what is expected of the current Grid projects, by developing services
for object collection level data selection and staging for the Grid, by
adding web-based portals to browse information in the Grid, and by enhancing
the job submission model to allow for more short-running jobs with interactive
response times. We have already demonstrated prototype versions of Grid
services beyond the baseline at the SC2000 and SC2001 conferences [19]. To
achieve the goal of deploying Grid based analysis in CMS over the next few
years, a further development effort is needed to create services which are
powerful and complete enough to be used for the real-life analysis tasks in
CMS.� The first of such services should
start a cyclic effort in which the Grid analysis tools can be refined according
to user feedback.
Scheduling of analysis activities, to make the most
efficient use of resources, is of particular concern. Currently, resource
management and allocation is ad-hoc. A lack of Grid-integrated tools
prevents scheduling from advancing beyond the most basic scenarios (involving
local resources or resources at one remote site).� As part of this proposal we intend to develop
a set of tools that will support the creation of more complex and
efficient schedules and resource allocation plans.� In the long term, the Grid projects intend to
deliver advanced schedulers which can efficiently map many jobs to distributed
resources. Currently this work is in the early research phase, and the first
tools will focus on the comparatively simpler scheduling of large batch
production jobs.� Experience with using
new scheduling tools should also help the ongoing development efforts for
automatic schedulers.
CMS has been successfully using heterogeneous tools to
analyze data. These tools take advantage of code developed within the
collaboration, in the wider high energy physics community, and
commercially.� The physicist performing
analysis in CMS is primarily concerned with collections of objects, the
boundaries of which may not fall on file boundaries.� Although considerable progress has been made
on using Grid technology in production tasks, analysis is almost entirely
accomplished using local resources, requiring that all the data be resident
locally.� Technology to deliver
data to physicists for analysis in the form of physics objects, without
moving large files, needs to be deployed.
The CMS core framework COBRA[7] is designed around the principle of "reconstruction on demand" allowing individual objects to be instantiated if they do not exist or recreated if they are obsolete. So far, a convenient end user interface to this powerful facility does not exist, and it is not possible for non-specialists to run COBRA codes on the Grid. The creation of an interactive, Grid-enabled analysis environment allowing the easy creation of selections and datasets is required for efficient analysis.
We are thus convinced that an Interactive Grid-Enabled
Environment ("IGEE") needs to be developed. This
environment should consist of tools and utilities that expose the Grid system
functions, parameters and behavior at selectable levels of detail and
complexity. At the request submission level, an end-user could interact with
the Grid to request a collection of analysis objects. At the progress
monitoring level, an end-user could monitor the process of preparing and
producing this collection. Finally at the control level, an end-user could
provide "hints" or control parameters to the Grid for the production
process itself. Within this interaction framework, the Grid could provide a
feedback on whether the request is "reasonable", for example by
estimating the time to complete a given task, showing the ongoing progress
towards completion, and displaying key diagnostic information as required. Only
by exposing this complexity can an intelligent user learn what is reasonable in
the highly constrained global system we expect to have.
We propose to implement IGEE using "Web
Services" which will ensure that it is trivially deployed regardless of
the platform used by the end-user (we are especially keen to preserve full
functionality regardless of the platform so that we remain/become OS-neutral
and allow access from as full a range of devices, from desktop PC to handheld
PC, as possible). The IGEE Web Services will be deployed on our
Tier 2 servers. The services will integrate with other services such as the
iVDGL [17] "iGOC"[�], the
agent-based monitoring service being developed by the Caltech group [16], and
the Virtual Data Catalog Service being built by CMS. They will also serve up
data on local conditions to neighboring servers.
Development effort leading to IGEE may result
in new requirements for the Grid projects. IGEE's implementation
may place constraints on existing Grid interfaces and may require functionality
that is currently not supported by the Grid. Through our collaborators' active
participation in numerous Grid projects, we will be able to feed these new
requirements and suggestions back to the Grid community.
The purpose of the project is to design and develop analysis
services for the CMS experiment, however, it is expected that many of the
components will be sufficiently generic to be useful for other related
experiments and scientific endeavors utilizing Grid computing technology.
In order to complete an analysis a
physicist needs access to data collections. Data structures and collections not
available locally need to be identified. Those collections identified as remote
or non-existent need to be produced and transferred to an accessible location.
Collections that already exist need to be obtained using an optimized
strategy.�� Identified computing and
storage resources need to be matched with the desired data collections using
available network resources.
The goal is to design a set of tools to optimize this
process, providing servers that interface with CMS and Grid developed
components, and OS neutral user-friendly client components that interface with
physicists.� The components should
provide the ability to specify parameters for an analysis job, determine the
resources required and give an estimate of time to completion, monitor the
progress, allow modification of requirements, return the results, and make an
archive of what was done.
The
architecture we propose to use is based on a traditional client-server scheme,
with one or more inter-communicating servers. A small set of clients is
logically associated with each server, the association being based primarily on
geographic location. The architecture is �tiered�, in the sense that a server
can delegate the execution of one or more of its advertised services to another
server in the Grid, which logically would be at the same or a higher level in
the CMS Tier N hierarchy. In this way, a client request can be brokered to a
server that is better equipped to deal with it than the client�s local server,
if necessary. In practice we intend to deploy Web Services running on Tier2s at
Caltech and UCSD. Each of these two servers will be the first point of
interaction with the �Front End� clients (local physicist end users) at those
sites and UCR and UCD.
The servers
will offer a set of Web-based services. This architecture will allow us to
dynamically add or improve services, and software clients will always be able
to correctly use the services they are configured for. This is a very important
feature of our proposal as it relates to usability. It can be contrasted with
static protocols between partner software clients, which would make any update
or improvement in a large distributed system hard or impossible.
Grid-based data
analysis requires information and coordination of hundreds to thousands of
computers at each of several Grid locations.�
Any of these computers may be offline for maintenance or repairs.� There may also be differences in the
computational, storage and memory capabilities of each computer in the
Grid.� At any point in time, the Grid may
be performing analysis activities for dozens of users while simultaneously
doing production runs, all with differing priorities.� If a production run is proceeding at high
priority, there may not be enough CPUs available the user�s data analysis
activities at a certain location.�
Due to these
complexities, we will develop facilities that allow the user to pose �what if�
scenerios which will guide the user is her/his use of the Grid.� One example might be an estimate of the time
to complete the user�s analysis task at each Grid location.� We will also develop monitoring widgets, with
selectable levels of detail, that give the user a �bird�s eye view� of potential
scheduling conflicts with their choices.�
C.2.a.
The Grid-Enabled Physics Analysis Desktop
We
describe below the various software tools and components that make up the
desktop environment which a physicist uses to carry out an analysis task.
Data
Processing Tools
These
interactive tools allow the manipulation and processing of collections of
objects. Typically, a physicist might incorporate an event selection algorithm
that he or she has written, using the algorithm to select a collection of event
objects from a database. The tools support a range of data processing tasks
which include fitting, plotting, and other types of analysis. Commonly, results
can be fed directly into software modules which produce publication quality
histograms or plots, and which allow the annotation of these graphics. The
tools usually will incorporate or link to large mathematical and statistical
libraries so allowing arbitrarily complex data processing tasks to be performed
on the physics data. Run-time compilation and linking of functions is also a
common feature which is widely used. Scripting support is typically offered so
that the physicist may apply an algorithm iteratively over many events, or as
an unattended batch-style activity. Good examples of data processing tools in
wide use in the HEP community are PAW (�Physicas Analysis Workstation�,
developed in the early 1980s at CERN) and ROOT (�Object Oriented Data Analysis
Framework�, developed in the early 1990s at CERN, and based largely on the
functionality of PAW, but employing a modern Object-Oriented data paradigm).
Data catalog browser
In addition to
various object collection search features provided by the analysis programs, a
generalized data browsing window allows a physicist to determine if an object
collection needed for his / her analysis has been created, and to find the location
of those collections. The collections may be available in several places as
replicas. The data catalog browser will allow the selection of a suitable
replica. Support for the merging of several object collections into a super
collection should also be provided.
Data
mover
A data mover window, which may be embedded in the data
catalog browser window, allows the physicist to include a customized data
movement plan as part of the job execution strategy. Allowing the physicist to
move existing data to a closer location could lead to a more optimized analysis
process.
Network
performance monitor
At any given time, data movement performance is highly
dependent on network performance. Allowing the physicist to monitor network
conditions dynamically will allow him / her to make intelligent decision on how
the data movement should be executed, where the data should be staged, and how
long is considered a �reasonable� amount of time to complete a data movement
process. Having this information allows the physicist to find the best route
and resource for data movement.
Computation
resource browser, selector and monitor
It is normally assumed that Grid execution services will
always present the end-user physicists with the optimal execution scheme for a
given Grid infrastructure. In the development stage of the CMS Grid, however,
it is beneficial to allow the physicist to get a full picture of what
computational resources are available and where these resources are, and to be
able to query the computation load at various clusters / regional centers.
Storage
resource browser
Before finalizing a data production request that involves
remote sites, a physicist should be able to query available disk space and
other storage classes at those sites to ensure successful completion. A storage
resource browser can also provide information on the storage performance, so as
to allow the physicist to estimate the amount of time needed to write or read a
particular data collection.
Log
browser
Various output logs produced by remote computation processes
will be viewed using a log browser window. This simple text window allows a
physicist to get direct feedback from the remote jobs indicating success,
failure, or job status.
The Grid-Enabled Desktop will enable the
utilities described above to be loosely coupled together as a suite of
applications that together form the physicist�s analysis �Front End� to the
Global Grid System. One of the main tasks implied by this proposal is to
develop a thin coating of glue and a thin layer of middleware that enables the
utilities to inter-operate to the extent desired (e.g. by providing uniform
resource names and locations for object collections), and which communicates
requests, queries, answers and result sets between the Grid Enabled PC and the
Server.
C.2.b.
The Web Services
To enable the use of a web client as a lightweight front-end
of Grid services, a web server infrastructure will be set up interfacing to
Grid information conduits, displaying information in a clear and concise way,
in the form of web pages sent to the browser. This infrastructure is shown in
Figure 2.
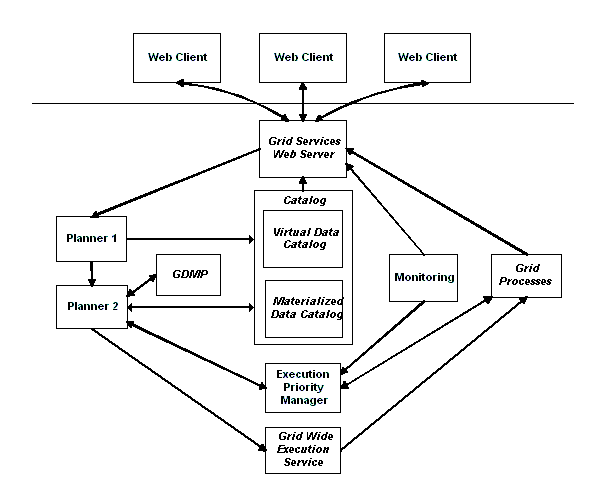
Figure 2:Web Services Design
Grid services are provided by specialized Grid-enabled
packages, some of which already exist and some that are still in the planning
stage. This shows an envisioned server configuration which allows
the user to access a set of data objects.�
One example of such data objects may be energies of particles detected
for a certain event.� A web client
accesses the Grid Services web server requesting this data.� The Grid Services Web Server contacts a
module which is responsible to supply information needed to either assemble
existing copies, create new from basic event data, or recreate the data.�
The
first step in this process occurs in Planner 1 which supplies general abstract
rules about how to generate data of a certain type.� For example, intermediate processed results
may only exist in a non-realized virtual form and have to be generated for the
selected events.� Later processing steps
may actually calculate the desired particle energies.� This data created in this step is called a
DAG (Directed Acyclic Graph) because operations must be performed in a
pre-determined order.
Once the
rules for generating the data have been constructed, a later step (Planner 2)
seeks to discover through interaction with the GDMP (Grid Data Mirroring
Package) whether the data of interest has already been calculated somewhere on
the Grid.� If it has, and it is not too
expensive to move the data, pre-existing data may be staged to the chosen run
location.� If the data must be calculated
from scratch, the DAG processor substitutes actual file names into its more
abstract input and passes the DAG to the next step.
The
Execution Priority Manager coordinates the job submissions of many users to
achieve performance constraints, such as completing production jobs by a
certain time.� It pushes tasks on a job
queue through the GRAM (Grid Resource and Monitoring), contained within the
Grid Wide Execution Service module, which in turn creates executables on the
members of the Grid.�
Finally,
the results are returned to the Web Server for formatting and return to the
requesting client.� Monitoring
information may be simultaneously supplied to the submitting user and also
provides data to the Execution Priority manager.
The Grid Services Web Server will authenticate browser
clients using Grid certificates and passwords as identity checks, coupled with
security policy and user rights on a particular Grid component. It is a special
component in the sense that it acts as a client for Grid services, but is
itself implemented on the server, sending Web pages to client browsers. In this
sense it acts as a proxy for the Web clients shown in Figure 2.
Information conduits
Grid services are provided by a variety of back-end processes, and these services will be made available to the front-end applications via remote data access and procedure calling mechanisms, possibly including SOAP, LDAP, XML-RPC, or CORBA.
For each service or data source a conduit will be
constructed to interface to the remote data access method to provide a
consistent remote interface that can be made available to front-end
applications.
C.2.b.1. Proposed
Grid Monitoring and Control Services
These services can be low- or high-level, with the high-level services making use of lower levels to provide more intelligent use of CPU, bandwidth and storage resources.
C.2.b.1.i.
Low-level services
1.
Cluster
hardware monitoring
Cluster node and head systems can provide a wealth of
information that can aid the smooth running of the cluster itself as well as
aid in scheduling decisions: useful parameters include CPU utilization, storage
space, IO rates, and local area network connectivity. This service is provided
by software already developed at Caltech.
2.
Wide
Area Network Monitoring
To aid in efficient data movement planning, network
connectivity between different sites, as well as historical data transfer rates
might be made available. Candidate software is already developed at Caltech.
3.
Queue
management
Submitting CPU intensive jobs for processing in clusters,
and monitor job progress. This may include stopping restarting and rescheduling
jobs. The service is provided by various sceduling tools, including RES,
Condor, and PBS.
4.
Data
access services
This includes data catalog browsing of files and possibly
abstract data objects, as well as metadata catalogs. This service will be
provided, at least in part, by the Virtual Data Catalogs being constructed as
part of the GriPhyN project.
5.
Data
mover services
Provided by GridFTP, and GDMP as part of
the Globus project. A reliable, Grid-enabled service to move data in the Grid.
C.2.b.1.ii.
High-level services
1. ��� Data transfer prediction
Based on historical data transfer rates, a projected
transfer rate to different Grid centers can be provided, enabling the user to
make informed decisions about how and where data can be processed most
efficiently. A prototype based on GridFTP exists.
2. ���� CPU
runtime prediction
Similarly speculative as the previous
service, provide runtime predictions for repetitive jobs scheduled in a
cluster. This provides some further vital information to make data movement and
scheduling decisions.
This proposal describes a Grid-based desktop analysis system
for CMS physicists. Such a system is a necessary part of the computing
infrastructure of the CMS experiment, as already explained. Accordingly,
existing activities with which we are involved and in which are taking lead
roles, are of direct relevance and are complementary to the proposed work. In
particular, we would like to mention:
�
We
have taken responsibility for developing and documenting a deep understanding
of the existing and future computing architecture of the CMS experiment,
especially as to how it relates with Grid services.
�
We
are actively engaged in large-scale production work involving the generation,
simulation and reconstruction of sizeable numbers of events using the CMS
simulation and reconstruction programs CMSIM and ORCA.
�
We
play significant roles in the coordination of US physics analysis and in
management of the US CMS software project.
�
Networking in the wide area is a key
component to any Grid-based project: we are also taking a lead role in the
provision of high speed networking between CERN and the USA, and between the
US-CMS institutes. We are also deeply involved in new network initiatives such
as Internet2 and other high speed research networks in the US, and (latterly)
links between these and Latin America.�
We are in the strong position of having a large, well-provisioned
research and development effort in the context of Grid-based, network
intensive, compute power intensive, storage intensive and management intensive
production of simulated and reconstructed CMS event data.
�
The
development and prototyping of distributed system services, the simulation of
the distributed systems, and their optimization, has been a research topic of
ours for some years, and has resulted in several publications [16].
�
We
have developed and demonstrated prototype analysis and visualization codes at
various conferences and meetings; in order to maintain up-to-date ideas on what
aspects of these systems is useful and practical. In particular, we have
demonstrated recently at SuperComputing 2001 a prototype physics analysis
environment and tool that allowed collections of physics objects to be
retrieved across the WAN from the remote Tier 2 facilities at Caltech and San
Diego, and analyzed locally.
�
The
first prototype Tier 2 centers in the world were commissioned, installed,
developed and managed at Caltech and San Diego. Our expertise and leadership in
this area is widely acknowledged and valued.
�
Expertise
in Fault Tolerant Distributed Systems is another feature of our collaboration.
We have been developing a system that allows the robust (fault tolerant)
execution of CMS codes in a WAN distributed system, and this system has been
successfully prototyped and demonstrated on the Tier 2 systems at Caltech and
San Diego [14,15].
�
We
have started work on integrating Grid tools with COBRA, the CMS object-oriented
software framework that encompasses ORCA (the OO reconstruction software).
Thus, we are able to support some of the virtual data concepts over local area
networks, at a single site. This support is directly related to the virtual
data foundation of the iVDGL[17] and GriPhyN projects [1].
�
We
already have a client-server prototype analysis system called� �Clarens� [18] which will easily integrate
into the system we are proposing to build. Prototypical users of Clarens have
already been identified, and are starting to work with the system and provide us
with valuable feedback.
As
already described, the proposed activity is closely related to work ongoing in
the existing projects we are participating in, namely iVDGL, GriPhyN, PPDG and
SciDAC. These projects do not address the specific and important area of
Grid-based analysis tools for physicists, which is the theme of the CAIGEE
proposal presented here.
Another crucial
aspect of the CAIGEE proposal is the ubiquity of good wide area network
connectivity implied by the emphasis on Grid services and their use at
our institutes. Caltech, UC Davis, UC Riverside and UC San Diego are all connected
to the CalREN2 network, which will facilitate the exchange of data and services
between the institutes. We are also active and taking lead roles in initiatives
such as the Internet HENP Working Group, the ICFA SCIC and the DataTAG, and we
expect there to be synergistic benefits from the relationships with these
groups. Eventually, we would like to extend the scope of our work to other Californian
universities, notably UC Los Angeles and UC Santa Barbara, who are
collaborators with us on CMS. In the longer term, we expect that the whole
US-CMS physicist community can profit from the systems and services that we are
proposing to develop here.
One particularly
promising collaboration we intend to pursue arises from Caltech and San Diego�s
involvement in the TeraGrid, which will deploy 10Gbit links in the Wide Area to
NCSA and Argonne as well as between our sites. The end points of the four links
will be capable of sourcing and sinking huge volumes of data at high rates into
large and powerful computing and storage systems. We see an opportunity to
leverage these capabilities by integrating the systems and services we are
proposing, so enabling end users to accomplish highly data and compute analysis
tasks that would otherwise be out of reach.
Princeton
University has proposed [#6116294, �Distributed Analysis of Large Distributed
Datasets with Java (BlueOx)�] building a distributed analysis service based on
Java analysis jobs and agents. The proposal is in a direction compatible with
previous work on distributed systems at Caltech[16]. MIT has proposed
[#6117630, �Collaborative Research on Multi Cluster Parallel Analysis Tool
based on ROOT�] a Grid enabled analysis tool based on ROOT. Overall, our
proposal is complementary to the MIT and Princeton proposals. If those two
proposals are also approved, a greater overall scope of work could be accomplished.
Collectively, we would ensure that the work programs of the three proposals
were carefully coordinated in order to maximize their output.

Figure 3 Breakdown of the proposed
Milestones
Figure 3 shows a Gantt chart describing
the milestones we propose to complete the work described in this proposal. The preliminary work on the client and
server components is expected to be completed as CMS is releasing the first
version of software based on the new persistency baseline.� This is expected at the end of this calendar
year (2002).� This will allow the
Grid-enabled analysis tools being developed based on our components to remain
synchronized with the CMS software.� It
should also provide sufficient time for CMS physicists to become proficient
with the new tools before the start of the analysis for the Physics TDR.
C.7.a.
Advancing Knowledge in Computer
Science and Computational Science Disciplines
The
knowledge and technology to be developed in this project will be distributed to
the general community via publicly available one or several CVS
repositories.� Where available, we will
contribute and enhance existing code repositories.� These repositories will include online tutorials
and manuals necessary to describe and implement the software.
C.7.b.
Educational Merit:� Advancing Discovery and Access for Minority
Students
This project provides an outstanding opportunity to train
the students who are interested in working in Grid environments.� We intend to sponsor one or two minority
students in the University of Brownsville program for minority students.� We also propose participating
in a ThinkQwest project at a secondary school in California.
C.7.c.
Geographical Access
Coupling
the power of the Grid with web services allowing browser based access will
enable data analysis and scientific discovery at any location with an internet
connection.
Harvey Newman:
KDI proposal, GriPhyN (Ongoing KDI- and GriPhyN-related
developments to be applied in the iVDGL. Work at Caltech in collaboration with
Bunn, Messina, Samar, Litvin, Holtman Wilkinson, et al., as well as� the PPDG and DataGrid projects): development
of ODBMS-based scalable reconstruction and analysis prototypes working
seamlessly over WANs; Grid Data Management Pilot distributed file service used
by CMS in production (together with EU DataGrid); Grid-optimized client-server
data analysis prototype development (Steenberg et al.), MONARC simulation systems
and application to optimized inter-site load balancing using Self Organizing
Neural Nets (Legrand et al.); development of a scalable execution service
(Hickey et al.); modeling CMS Grid workloads (Holtman, Bunn et al.); optimized
bit-sliced TAGs for rapid object access (Stockinger et al.); development of a
DTF prototype for seamless data production between Caltech, Wisconsin and NCSA
(Litvin et al.; with Livny at Wisconsin and Koranda at NCSA).
1. GriPhyN Homepage. http://www.griphyn.org
2. Particle Physics Data Grid Homepage.� http://www.ppdg.org
3. European DataGrid Homepage, http://www.eu-datagrid.org
4. GDMP Homepage. http://cmsdoc.cern.ch/cms/grid
5. The California US Tier2 Prototype https://julianbunn.org/Tier2/Tier2_Overall_JJB.htm
6. CMS Task and Deliverables Document, http://cmsdoc.cern.ch/cms/cpt/deliverables.
7. Coherent Object-Oriented Base for Reconstruction Analysis and Simulation, COBRA,������������� The CMS central framework, http://cobra.web.cern.ch/cobra.
8. K. Holtman. Views of CMS Event Data: Objects, Files, Collections, Virtual Data Products. CMS NOTE-2001/047.� October 17, 2001.
9. V. Lefebure, V. Litvine, et al. "Distributed CMS Production: Data Schema for Bookkeeping", CMS Internal Note (in preparation). http://www.cacr.caltech.edu/~litvin/dataModel.ps
10. K. Holtman, on behalf of the CMS collaboration. CMS Data Grid System Overview and Requirements. CMS Note 2001/037.� July 16,2001.
11. K. Holtman et al, for the CMS collaboration. CMS Requirements for the Grid. Proc. of CHEP 2001 (Beijing, September 3 - 7, 2001)p. 754-757. Science Press. ISBN 1-880132-77-X
12. H.Stockinger, A.Samar, W.Allcock, I.Foster, K.Holtman, B.Tierney. File and Object Replication in Data Grids. To appear in10th IEEE Symposium on High Performance and Distributed Computing (HPDC-10) , San Francisco, California, August 7-9, 2001.
13. K. Holtman. HEPGRID2001: A Model of a Virtual Data Grid Application. Proc. of HPCN Europe 2001, Amsterdam, p. 711-720,Springer LNCS 2110. Postscript version. (c) Springer-VerlagLNCS. Also available as CMS Conference Report2001/006.
14. T. M. Hickey and R. van Renesse, An Execution Service for a Partitionable Low Bandwidth Network, Proceedings of IEEE Fault-Tolerant Computing Symposium (June 1999)
15. B. A. Coan and T. M. Hickey Resource Recovery in a Distributed Processing Environment, Proceedings of the 1992 IEEE Global Telecommunications Conference (December 1992).
17. International Virtual Data Grid Laboratory homepage, http://www.ivdgl.org
18. C.D. Steenberg, J.J. Bunn, T.M Hickey, K. Holtman, I. Legrand, V. Litvin, H.B. Newman, A. Samar, S. Singh, R. Wilkinson Prototype for a generic thin-client remote analysis environment for CMS. Proc. of CHEP 2001 (Beijing, September 3 - 7, 2001). Science Press. ISBN 1-880132-77-X
19. J.J.Bunn and K.Holtman �Bandwidth Greedy Grid-Enabled Object Collection Analysis for Particle Physics�, Demonstration at the SC2001 Conference, Denver, Colorado.
20. TeraGrid Homepage. http://www.teragrid.org
The California prototype Tier 2 is split between
Caltech�s Center for Advanced Computing Research, and the San Diego
Supercomputer Center. Each half of the Tier 2 will be equipped with around 50
dual processor rack mounting PCs running Linux, each with 512MB of RAM and
about 50GB internal disk. Dual processor servers at each of the Tier 2 sites
provide a front-end for job submission, hosting to RAID disk arrays of combined
capacity approaching 5 TB, and Gbit links to the WAN. Further details may be
found at https://julianbunn.org/Tier2/Tier2_Overall_JJB.htm. The
California Tier 2 equipment will be augmented by funds from this project to
provide a small cluster of interactive machines that are closely coupled with
the existing compute farm and which can make use of the storage resources there.
PI
Harvey
Newman��������������������� California
Institute of Technology
Collaborators
(Those
in bold italics are proposed to receive funding)
Eric Aslakson ����������������������� California
Institute of Technology
James
Branson������������ University of
California, San Diego
Julian
Bunn������������������������������ California
Institute of Technology
Robert
Clare��������������������������� University
of California, Riverside
Ian
Fisk����������������������������������� University
of California, San Diego
Takako
Hickey������������ California Institute of
Technology
Winston
Ko����������������������������� University
of California, Davis
Iosif
Legrand��������������������������� California
Institute of Technology
James Letts���������������������������� University of
California, San Diego
Edwin Soedarmadji�������������� California
Institute of Technology
Conrad
Steenberg������������������� California
Institute of Technology



