Intellectual
Merit
We propose to
develop and deploy Global Information Systems and Network Efficient Toolsets
(GISNET) to enable a new generation of highly scalable networks, to meet the
needs of frontier science, and empower research and education networks
worldwide in the coming decade. The design, operation, and optimization of
large-scale hybrid networks to serve data intensive applications presents
several key research challenges. We
intend to overcome these challenges by (1) developing a theoretical and
experimental framework in which to understand and control the interactions of
various technologies and protocols in a hybrid optical packet- and circuit-
switched IP network, (2) developing efficient algorithms to manage the
infrastructure and optimize services for a broad range of large-scale
applications starting with physics and astronomy, and (3) using WAN-In-Lab and
then field-testing and deploying these algorithms in our UltraLight testbeds,
and then major research and education networks.
A critical part of GISNET is a global Monitoring And
Control System (MACS) that manages the heterogeneity of hybrid networks at the
levels of the application, protocol and architecture. We will (1) investigate
the application-service mapping and resource allocation problems in hybrid
networks serving heterogeneous applications; (2) examine heterogeneous
protocols’ equilibria and their characteristics including stability, efficiency
and fairness; (3) process real-time measurements of the network state; and (4)
use advanced stability analytical tools and heuristic learning algorithms to
decide when control actions are needed, and which actions. GISNET will capitalize on the recent
progress in the theory of heterogeneous protocol equilibrium and computational
stability analysis, to develop a toolset to effectively control the network
operation in quasi-real time, and progressively determine the optimal
distribution of flows among traditional IP routed, MPLS-managed, and
dynamically constructed optical paths.
The first
round of field-tests will confront MACS simultaneously with the “data
challenges” of the LHC experiments (many multi-Terabyte loss-intolerant data
transfers), e-VLBI (multiple loss-tolerant streams up to 10 Gbps coordinated
and analyzed in real-time), followed by
BIRN (multi-GByte images delivered in the minimum feasible time). These
projects, with bandwidths rising from the 10 Gbps to the Terabit/sec (Tbps)
range over the next 10 years, will serve as persistent application-drivers.
Substantial network-aware sectors in these communities, including the
UltraLight team, are eager to engage in the GISNET program, to realize the
discovery potential of their projects.
The GISNET
Collaboration includes the principal developers and implementers of high speed
long-distance data flows using FAST and the standard protocols, the developers
of the MonALISA[MON03] and IEPM[IEPM] worldwide monitoring infrastructures, the
leaders of the global UltraLight optical network and WAN-In-Lab, and the
leadership of the GriPhyN[GriPhyN], iVDGL[IVDGL], PPDG[PPDG] projects and the
emerging Open Science Grid [OSG05]. We are therefore in a unique position to
utilize these developments and address several of the most pressing fundamental
challenges in network research, distributed systems, and data intensive
applications; challenges that stand between the leading projects in
data-intensive science and their next round of discoveries.
Specifically,
we will leverage and build on several of our unique developments: (1) advanced
TCP stacks (such as FAST), and end-system configurations capable of reliable high throughput data transfers up to
the 10 Gbps range over continental and transoceanic distances, (2) WAN-In-Lab
and its extension across NLR[NLR03], (3) the UltraLight hybrid circuit- and
packet-switched testbeds, (4) our development of end-to-end monitoring and
tracking systems for R&E networks and Grids, based on the MonALISA real-time
services fabric, OC192MON, and the IEPM
lightweight monitoring system, along with the secure Web-services based
CLARENS[STE03] fabric, and (5) the development of production-ready high
performance distributed storage services (LambdaStation) that we are integrating
with the Grid systems of major physics experiments, to meet their needs for a
highly capable network-aware Grid Analysis Environment (GAE) [GAE].
Education,
Outreach and Broad Impact:
GISNET’s groundbreaking scope offers exciting and unusual educational outreach
opportunities for students. It provides
direct and significant support for E&O activities including: application
development, experiment participation, infrastructure deployment, and research
experiences at participating institutions through a one-week tutorial workshop
followed by summer research projects. We will exploit existing outreach
programs within the GriPhyN, iVDGL, and e-VLBI Grid projects as well as
The revolutionary impact of this proposal is driven by the convergence of the
recent breakthroughs in the theory and practice of network science, the central
roles the GISNET team and its partners in many of these developments, and our
team’s management and operation of WAN-In-Lab and UltraLight, which together
with our international partners (e.g., SURFnet), comprises an unprecedented set of laboratory-based, R&D and
production-oriented networks with continental and transoceanic reach. We will leverage
our exceptional access to research-oriented and production-oriented network and
Grid infrastructures, as well as the large and broad complement of expert
personnel at our disposal and the
exceptional support of major networking vendors (notably donations from Cisco
Systems), to ensure GISNET’s success and to further broaden our
impact. We will work closely with GLIF to enhance our partnerships with
projects not directly involved in GISNET.
GISNET and MACS will be key factors in ushering in a new era of global
real-time information systems where all three sets of resources - computational, storage and network - are monitored and tracked to provide
efficient, policy-based usage. By
consolidating with other data-intensive Grid systems, we will drive the next
generation of network and distributed information system developments, and new
modes of collaborative work in many disciplines, bringing great benefit to
science and society.
The design, operation, and optimization of large-scale hybrid networks, which is essential to serve a wide range of data intensive science applications, presents several research challenges related to the heterogeneity of the protocols and stack parameter settings used, as well as the new element of diverting some of the largest flows and mapping them onto a set of dynamically constructed optical paths. We propose to (1) develop a theoretical and experimental framework in which to understand and control the interactions of protocols, switching criteria and various technologies in a hybrid optical packet- and circuit- switched network, (2) develop efficient algorithms to manage the infrastructure and optimize services for various large-scale applications starting with physics and astronomy, followed by extension to other disciplines, and (3) test these algorithms and methods in the laboratory (in WAN-In-Lab) and in the field (in UltraLight), and deploy these algorithms in global research and education networks. A critical part of the infrastructure is a global MACS that takes real-time measurements of network state, and uses a combination of advanced stability and robustness analysis and heuristic learning algorithms to decide when control actions are needed, and which action. MACS requires the solution of several open problems in network science, and the development of a practical solution requires us to bring together a broad range of technologies for the first time.
A.2.1 Network Research Program: Managing Heterogeneity
Specifically, our research program to develop MACS will consist of four major components, with an overarching theme of managing heterogeneity.
First, GISNET is heterogeneous both in network services and driving applications. The applications have diverse traffic characteristics and quality requirements: some require extremely high bandwidth, and are non-real time but loss intolerant, while others are complementary – real-time but loss-tolerant. The infrastructure can provide different types of services: statically or quasi-dynamically partitioned lightpaths, dynamically configured MPLS LSPs, or best-effort packet switched service. Given a physical network with a fixed total resource capacity, and options for different service-level guarantees along various paths, what is an optimal way to allocate these resources to different services and map applications with different throughput and delivery-time requirements to these services? We will formulate automatic ways for optimal resource allocation and application mapping to services, design distributed algorithms to implement them, and test our implementation in GISNET, taking into account that multi-Gigabit/sec and smaller flows can now fairly-share long distance network paths using advanced TCP protocols such as FAST.
Second, we will address a critical problem that will arise in the incremental deployment of advanced protocols such as FAST [JWL04, JWL+05, PWDL05]. It turns out that when heterogeneous protocols that react to different congestion signals share the same network, the current theoretical model breaks down. Using Kakutani’s generalized fixed point theorem, we have proved analytically that, unlike in a single-protocol case, a network with heterogeneous protocols can exhibit multiple equilibrium states [TWLC05]. The set of networks that have infinitely many equilibria has a Lebesgue measure zero. Using the Poincare-Hopf Index Theorem in differential topology, we have characterized them and derived several sufficient conditions under which equilibrium is globally unique. We have demonstrated this experimentally using TCP Reno and FAST in simulations. We have also shown that any desired inter-protocol fairness between TCP Reno and FAST is in principle achievable by an appropriate choice of FAST parameter, and that intra-protocol fairness among flows within each protocol is unaffected by the presence of the other protocol, except for a reduction in effective link capacities. This is a very preliminary work and we are proposing to study this further. As GISNET will be heterogeneous, with multiple devices and protocols that use a variety of feedback signals for real-time control, we need a mathematically rigorous framework to understand its behavior, and use it to develop practical methods to design, optimize, and control it.
Third,
we will integrate the recent breakthrough in robust control theory and convex
optimization, with measurement-based heuristic learning algorithms into our
MACS to guide the operation of the large-scale network we build. The recently developed techniques at Caltech
of sum of squares optimization provide convex polynomial time relaxations for
many NP-hard problems involving positive polynomials. The observation that sum
of squares decompositions of multivariate polynomials can be computed
efficiently using semidefinite programming has initiated the development of
software tools, such as SOSTOOLS[PPP02,PPSP04], that facilitate the formulation
of the semidefinite programs from their sum of squares equivalents. We will develop methods to incorporate these
mathematical problem solvers into our software system MACS that can be used for
real-time control. The basic idea is to
develop a methodological framework to represent network dynamics in terms of
certain delay-differential equations and use SOSTOOLS to calculate the
stability regions of network operation regime. This expands on the scope of
current congestion control using TCP/AQM, and use SOSTools to calculate
stability regions of a given network operation regime. This provides important
clues as to how well the network is performing as a whole and more importantly
what aspects of the network configuration, i.e., bandwidth provisioning,
switching and routing, protocol selection, end-system and network interface parameter
settings, etc., need to be adjusted in order for the network to stay within a
performance regime.
Finally, a critical part of our MACS is real-time monitoring. We will leverage the MonALISA system developed at Caltech and integrate it into our MACS. In particular all the above the components (resource allocation and application mapping, heterogeneous protocols, and network control) rely on real-time measurements of various network states, and filtering of these measurements. A straightforward implementation will likely be overwhelmed by the dimensionality of the state space. We will apply advanced statistics techniques and model reduction theory to rigorously derive efficient real-time monitoring and filtering algorithms. As we continuously monitor a network and dynamically optimize its operating point, the online “feed” of network configurations information will be made available to the other modules. The extensive deployment of our experimental network setup will also enable a verification of the practicality of the control system theory embodied by SOSTOOLS, and provides invaluable insights into the various assumptions made when deriving the theoretical formulation and its solution approaches.
GISNET and MACS present a unique “no-loss” opportunity to confront and synergize the robust system theory and heuristic learning algorithms, where the use of SOS analysis can provide crucial clues to the refinement of the heuristic algorithms, and improvements in the heuristics help verify the modeling assumptions in the SOS formulation. Furthermore, to enable networks to automatically react to the control signals guiding it towards stable operating regime, we will rely on not only packet-level congestion control and routing mechanisms, but also layer-1 optical control plane technologies such as GMPLS[GMP01,GMP03,GMPLS,MDS02] and UCLP[WCS+03] as our target applications areas often requires dedicated optical circuits or “light-path”, and the effective control of these entities as an integral part of our distributed monitoring and feedback framework warrants a focused research. During the recent “robust service challenge” for LHCNet we have observed the following phenomenon. Using 54 streams on 9 small servers with 3 disks each extremely stable performance of 5 Gbps disk-to-disk was achieved continuously for several days and then once a few large TCP RENO flows were added to the mix the network utilization degraded significantly whereas using TCP FAST the same experiments achieved stable performance. Simply relying on simulation or experiments alone it is hard to pinpoint the cause of the problem, and we believe an analytical stability prediction tool supported by robust control theory should provide a better understanding of the cause of these problems by clearly determining the “stability region” (or stability maps) of the system and pin-pointing the chaotic operation regions which the operators should avoid.
In Section C2.2
we present some of our preliminary results on equilibrium of heterogeneous
protocols as an illustration of the theoretical approach we intend to take and
results we expect. Then in Section C2.3, we summarize our recent result
on application of SOS theory to network congestion control, and explain how we
will integrate SOSTOOLS with learning mechanisms for network control.
A.2.2
Preliminary
Results on the Equilibrium of heterogeneous Protocols
A key assumption in the current model is
that all traffic sources are homogeneous
in that, even though they may control their rates using different algorithms,
they all adapt to the same type of congestion signals, e.g., all react to loss
probabilities, as in TCP Reno, or all to queueing delay, as in TCP Vegas or
FAST [JWL04]. When sources with heterogeneous
protocols that react to different congestion signals share the same network the
current duality framework is no longer applicable. We propose to develop such a mathematically
rigorous framework and use it to develop practical methods to design, optimize,
and control such networks.
A network consists of a set
of ![]() links, indexed by
links, indexed by![]() , with finite
capacities
, with finite
capacities![]() . Each link has a price
. Each link has a price
![]() as its congestion measure. There are
as its congestion measure. There are![]() different protocols
indexed by superscript
different protocols
indexed by superscript![]() , and
, and ![]() sources using protocol
sources using protocol![]() , indexed by
, indexed by![]() where
where ![]() and
and![]() . The
. The ![]() routing matrix
routing matrix ![]() for type
for type ![]() sources is defined by
sources is defined by ![]() if source
if source ![]() uses link
uses link ![]() , and 0 otherwise. The
overall routing matrix is denoted by
, and 0 otherwise. The
overall routing matrix is denoted by ![]() . All type
. All type![]() sources react to
“effective prices”
sources react to
“effective prices” ![]() at links
at links ![]() in their paths. The effective price
in their paths. The effective price ![]() is determined by the link price
is determined by the link price ![]() through a price mapping function
through a price mapping function![]() , which might depend on
both the link and the protocol type. By specifying function
, which might depend on
both the link and the protocol type. By specifying function![]() , we can let the link
feed back different congestion signals to sources using different protocols.
, we can let the link
feed back different congestion signals to sources using different protocols.
A network is in equilibrium
when each source maximizes its net benefit (utility minus bandwidth cost), and
the demand and supply of bandwidth at each link are balanced. In equilibrium,
the aggregate rate at each link is no more than the link capacity, and they are
equal if the link price is strictly positive. Our preliminary results show that despite of the lack of an
underlying utility maximization problem, existence of equilibrium is still
guaranteed.
Theorem 1 There exists an equilibrium price ![]() for any network.
for any network.
In a single-protocol
network, if the routing matrix has full row rank, then there is a unique active
constraint set and a unique equilibrium price associated with it [MWa00]. On
the contrary, the uniqueness of equilibrium in heterogeneous network is not
guaranteed. In particular, the active constraint set in a multi-protocol
network can be non-unique even if ![]() has full row rank. In [TWLC05], we
provide two numerical examples. The first example has a unique active
constraint set, and yet it exhibits uncountably many equilibria. The second
example has multiple active constraint sets but there is a unique (but
different) equilibrium associated with each active constraint set.
has full row rank. In [TWLC05], we
provide two numerical examples. The first example has a unique active
constraint set, and yet it exhibits uncountably many equilibria. The second
example has multiple active constraint sets but there is a unique (but
different) equilibrium associated with each active constraint set.
However, we have proved the local uniqueness is basically a generic property of the equilibrium set [TWLC05]. We call a network regular if all its equilibrium prices are locally unique. The next results shows that almost all networks are regular, and that regular networks have finitely many equilibrium prices. This justifies restricting our attention to regular networks.
Theorem 2 Under mild assumptions, we have
1.
The set of link capacities ![]() for which not all equilibrium prices are
locally unique has Lebesgue measure zero in
for which not all equilibrium prices are
locally unique has Lebesgue measure zero in![]() ;
;
2. The number of equilibria for a regular network is finite.
3. A regular network has an odd number of equilibria.
The exact condition under which network equilibrium is
globally unique is generally hard to prove. However, we have derived
four sufficient conditions for global uniqueness in [TWLC05]. The first
condition relates local stability of the equilibria to their uniqueness. The
second condition generalizes the full rank condition of ![]() from single-protocol network to multi-protocol
network. The third condition guarantees uniqueness when the price mapping
functions are linear and link-independent. The final condition implies global
uniqueness of linear networks.
from single-protocol network to multi-protocol
network. The third condition guarantees uniqueness when the price mapping
functions are linear and link-independent. The final condition implies global
uniqueness of linear networks.
We have also shown that any target inter-protocol
fairness between
A.2.3
SOSTOOLS for
Stability and Robustness Analysis and Network Management
There has been a great recent interest in sum of
squares polynomials and sum of squares optimization[P00,CLR95], partly due to
the fact that these techniques provide convex polynomial time relaxations for
many NP-hard problems involving positive polynomials, in particular the
stability analysis of complex nonlinear system using Lyapunov functionals
[P03]. The observation that sum of squares decompositions of multivariate
polynomials can be computed efficiently using semi-definite programming has
initiated the development of software tools that facilitate the formulation of
the semi-definite programs from their sum of squares equivalents. One such
software is SOSTOOLS [PPP02, PPSP05]. Sum of squares programs and SOSTOOLS find
applications in various systems and control theory problems. In [PLD04], an
application of SOSTOOLS to network congestion control for the Internet is
presented where a unified framework is introduced to enable comparability and
better understanding of the shortcomings of certain TCP/AQM schemes. Developing
robust models for the modules comprising the system is the first step for
analysis and design. For network congestion control, this process produces
uncertain deterministic nonlinear delay-differential equation models. We can
derive stability conditions of the network by using SOSTOOLS to solve a SOS
optimization problem associated with the Lyapunov stability theorem, and it is
shown in [PLD04] that if we have available the topology and flow routing
information a tighter stability condition can be obtained from SOS
optimization, than the conditions from only assuming arbitrary network
topology.
This motivates
us to propose that a potentially practical application of SOSTOOLS lies in
integrating the robust system theory and a real-time monitoring mechanism. We
envision SOSTOOLS acting as an integral component of the end-to-end network
provisioning and monitoring framework of GISNET. In particular we will study
the feasibility of using SOSTOOLS, with input provided from the real-time
monitoring system, to calculate the stability regions of a given network
operation regime. As we continuously monitor/control networks and dynamically
determine paths for large/critical flows the online “feed” of network
configurations information will be made available to the SOSTOOLS module. The
input to the SOSTOOLS includes network topology, link load, routing matrix,
traffic mix etc.. It is an interesting research problem to study the
effectiveness of the SOS framework as we scale up the size of the network,
reducing complexity by aggregating the representation of the network based on
locality (LAN vs. ), protocol layers (lightpath vs. routing), and/or flow
characteristics (TCP vs. UDP). We believe this solution framework will provide
important clues as to how well the network is performing as a whole, and more
importantly what aspects of the network configuration, i.e., bandwidth
provisioning, routing, protocol selection, end system parameter setting, etc.,
need to be adjusted in order for the network to stay within a stable regime.
Moreover the extensive deployment of our experimental network setup will also
enable a verification of the practicality of the control system theory embodied
by SOSTOOLS, and provides invaluable insights into the various assumptions made
when deriving the theoretical formulation and its solution approaches.
In addition to
SOSTOOLS we will leverage the existing MonALISA system and augment its heuristic
learning capability. Self-Organizing Neural Networks (SONN) [H99, KLM96, MMT00,
BL94,NRP00,Ahma94] have the characteristics that (a) they can be applied to
complex problems with no known optimum, but where improvements can be measured,
(b) they can be used to map scattered data points in an abstract space into
(more) simply connected regions with well-defined edges, which are amenable to
decisions between choices among discrete alternatives and (c) the trajectory of
parameters can be projected forward and convergence accelerated, as
demonstrated by the SONN simulation study of the evolution towards optimal load
balancing among a series of Grid sites [NL01]. In practice this will be part of
a feedback process where we can evaluate and extrapolate the effective
parameter sets and “direct” the evolution of the network to avoid being trapped
in the chaotic operating regime [PPSP05, PLD04].
A.3.1 Distributed Systems Challenges
GISNET will address some of the key “system-level” challenges facing the development of the global information systems required by data-intensive science, that are able to deal effectively with accessing, distributing and/or collaboratively analyzing large (Gbyte-scale) to massive (TByte to multi-Petabyte) datasets or data “objects” (precision images; real-time streams). Specifically we will use the results of our network research program, MACS as it develops, the UltraLight testbed-ensemble of networks, and high performance data servers deployed at several key locations to develop and test:
1. Protocols and parameter settings to allow real-time 1-10 Gbps streams (for eVLBI) and rapid-delivery of clinical GByte images to coexist stably with TByte-scale block-transfers (as in high energy physics)
2. Effective algorithms and parameters for per-flow assignment to diverse paths in a hybrid network, where a limited number of large or time-critical flows will be diverted to available paths geared for high throughput, and a more numerous set of designated flows will have throughput levels managed through protocol settings and other management mechanisms such as MPLS
3. Effective optical control plane provisioning algorithms and services coupled to real-time monitoring and control MonALISA services, with setup times of order 1 second for intercontinental paths, in order to handle a complex task-mix with sufficient agility.
4. Heuristic self-organizing neural-net (SONN) and other evolutionary learning algorithms to optimize workflow through the system, both in isolation (maximum network throughput) and in the context of Grid systems, where the arrival of designated datasets needs to be co-scheduled with the use of computational resources.
5. Agent-based (MonALISA) tools that will probe and characterize the configuration, performance and limitations of end-systems (CPU power, disk I/O speeds, bus limits) and compute end-to-end network performance estimates, checked by active monitoring where appropriate, to guide the provisioning and management services above.
6.
Real-time services that incorporate analytical
(SOSTools-based) computational subsystems to help steer the workflow optimizing algorithms (4. above)
towards regions of greater system stability and performance. The theoretical
calculations can help improve the optimization process, and/or the SONN methods
can be used to characterize and map the edges of the regions of stability.
A.3.2
Monitoring and Operational Steering R&D
for High Performance Networks
Any network needs monitoring to enable effective management
including planning, setting expectations, path selection, application steering,
problem detection and troubleshooting, etc. Both regular and on-demand
measurements are needed. Current active
end-to-end network measurement tools such as pathload, ABwE [ABWE], iperf
[IPERF] do not scale well to high performance networks (1 Gbps and above), so
the need is critical for tomorrow’s high performance networks, where we need to
explore, evaluate and understand the applicability of existing and new measurement
tools, and extending the range of effective measurements to 10 Gbps and beyond
over the next few years.
For example lightweight active end-to-end packet pair
techniques such as ABwE may fail due to insufficient system clock granularity,
or techniques such as interrupt aggregation, TCP offload engines etc. New
techniques are required, that may require offloading the timing to passive
devices watching the network traffic, or collaboration with the Network
Interface Card (NIC) vendors or others to add access to timing information from
devices closer to the physical network, more aggressive active tools such as
iperf or applications such as GridFTP [GridFTP], bbftp [BBFTP], when used on
high-performance long distance networks, have to run for typically for over a
minute to get out of slow start for long enough to make a realistic steady
state measurement. Besides taking an order of magnitude longer to make a
measurement than the lightweight packet-pair techniques, during the measurement
time the more aggressive active tools have a large impact on the network’s
performance. This in turn can require the addition of complex scheduling
algorithms to reduce the effects of measurement “collisions”.
Passive measurement tools such as tcpdump can generate
enormous amounts of data. 10 Gbps passive measurement tools such as OC192MON
[OC05] are still in their early days and hence expensive to deploy widely
today. Router embedded tools such as NetFlow [NETFLOW] and SNMP, also provide
valuable information assuming one has access to the routers.
Our approach in GISNET is to monitor the time-dependent patterns of packet arrival times over a range of timescales (from minutes down to milliseconds, and microseconds in a few cases) as well as per-flow throughputs, while correlating the observed behaviors with protocol profiles among the flows at many points in the network. This is essential for theoretical understanding of the stability of the system, and to provide support for operational decision services that direct and manage flows as well as dynamically construct end-to-end paths using optical switches when needed. These measurements require traffic interception based on existing tools such as NetFlow for traditionally provisioned links, or dedicated systems (based on splitters) for strategically located optical links, coupled to advanced sampling and statistical analysis techniques.
This will be implemented as dynamically deployable filters using the MonALISA real-time services framework, to extract fine-grain details of the total traffic, or to monitor and potentially alter specific parameters for a few selected large- or time-critical flows. The network topology and the performance of each connection segment will be monitored using the same set of distributed MonALISA services. As it does today, each service-instance will keep track of, and evaluate the available bandwidth over each of the network paths between it and the other service instances, constructing and evolving in time a “tomographic” view of the interconnections among networks, or autonomous systems, both for the currently used and the “best” (highest-performing) set of paths. The collected information is available in near real-time to any service or application, based on a discovery mechanism, or it can be analyzed using a distributed network of agents to trigger appropriate actions when necessary. A new element will be agent-based services deployed in a set of end systems, using the MonALISA ApMon client [ApMon], to probe and characterize the system hardware, kernel, and interface configurations, as well as the time-dependent loads on the system, thereby better determining the end-to-end performance limits for a designated set of flows.
The chosen monitoring tools will need to be integrated in some cases with one another, and into measurement infrastructures, as has been done with the IEPM and MonALISA frameworks. This will be supplemented by tools able to probe 10 Gbps flows at packet level, such as OC192MON. This integration will include: analysis, visualization and navigation through the data; providing access to the data based on a subscription/listener mechanism and self describing web services.
The extensive real-time monitoring information, together with historical data will enable us to optimally provision paths for selected flows. This will allow us to contribute to the development of optimized steering methods for distributed applications, Grid systems and the operation and management of the next generation of R&E networks.
A.3.3 Global End-to-End Services R&D
Deploying large scale data-intensive applications results in complex and intensive interactions between the networks and the performance and scheduling of compute and storage resources. We are therefore beginning to develop and deploy the first prototypical network-aware global services in the UltraLight project that support the management of multiple resource types and provide recovery mechanisms from system failures. A key assumption that is driving the development of these services is that overall demand typically fills the capacity of the underlying resources. Thus, mechanisms are needed for users to access and effectively utilize the shared scarce resources based on the administrator defined and managed policies. The global services will consist of:
1. Network and System Resource Monitoring Services, with the role of providing pervasive end-to-end global resource monitoring as the input to higher-level services.
2. Policy Based Job Planning Services, to help make decisions on co-scheduling work (data, computing, network) that (a) has threshold turnaround time (b) requires efficient use of resources and (c) supports prioritization of one class of jobs over another based on the policies of the scientific collaboration
3. Job Execution Services, that provide users insight into the state of their application at any given time.
GISNET’s role with respect to these services is (a) use the emerging analytical and heuristic tools and monitoring measurements to develop effective algorithms and methods for managing the distribution and performance-tuning of individual flows, (b) integrate the evolving performance information on the entire set of flows in a given region of the network to manage and progressively optimize workflow, (c) extend these services to make decisions based on end-to-end capability estimates, including server CPU and I/O capability, local as well as wide area network throughput capability (including packet loss in some situations), and load dependence of all of the above, (d) provide a sound test- and measurement framework, driven by present and future developments in network theory as well as experiment, where fundamental distributed system issues such as the effectiveness of alternative policies on relative resource-usage and turnaround times can be evaluated and (e) make the results of these studies and developments widely available, as an integral part of the MACS toolset.
The MonALISA distributed services architecture will
provide a strong foundation for MACS, and the global services described above.
MonALISA uses dynamically deployable agents to collect and analyze complex
monitoring information in real-time round-the-clock from more than 160 Grid
sites, as well as
Example deployments of MonALISA to manage real-time global systems include the VRVS [VRVS] system of “reflectors” (80 servers used to direct and manage the UDP + RTP-based audio and video streams among 47,000 registered host computers in 105 countries), where MonALISA optimizes the reflector interconnections, with a global Minimum Spanning Tree[MST03]. A recent MonALISA development is a prototype system to create, securely and on demand, an optical path or a tree of optical paths, in less than 1 second across intercontinental distances, for network operators or end-users, by monitoring and controlling a large network of photonic switches. End-user agents are used to report monitoring data from any host to MonALISA, by combining it with all the other measurements, to provide a basis for end-to-end optimization services.
The result of this development program is expected to be highly scalable, robust services allowing data-intensive applications to negotiate with the Global Services for a dedicated or “preferred” network path constructed through optical switching, the use of MPLS tunnels or other management mechanisms, rather than use one of the default paths over production networks. This essential element, currently missing from Grid Computing research, will help make Global VO’s for science a reality.
A.3.4 End-System Development and Integration
An important area of development is the study of optimizing the performance of the network’s end systems. This often proves to be a complex systems engineering problem, involving the interplay between the hardware components (busses, network adapters, memory, disk arrays, CPU, etc.), the Operating System, and the various layers in the network software stacks. Again, this problem can be characterized in maps of the parameters which reveal regions of optimal performance, and occasionally unexpected instability features. Beyond the end-systems, the interplay of the various other hardware components lying along the network path requires careful study before a truly global view of the end to end network flows can be derived.
A critical component of the end-to-end paths we will use is high performance data storage systems capable of supporting flows up to the GByte/sec range. Most of the flows supporting data-intensive science are dataset movements between sites, and thus involve storage. Large scale memory-to-memory-only network transfers are relatively rare in data, but important in application areas such streaming of graphics and the visualization of large scale real-time data. Several of us have been working in collaboration with server and partners at FNAL, CERN[CERN], Microsoft, AMD, Newisys, and HP system configurations of storage that maximize throughput. This work is evolving from a state of the art today that can achieve around 700 MBytes/sec over transatlantic distances, to systems capable of more than a GByte/sec in the near term, and potentially a tenth of a TByte/sec within 5-10 years.
A.3.5 Optical Control Plane R&D: Integrating Intelligent Core and Edge
A major challenge facing the development of a hybrid packet and circuit-switched network is to optimally integrate an “intelligent”
optical core with a set of intelligent optical edges via flexible control-plane
protocols. We distinguish the notion of optical core vs. optical edge in terms
of different functionalities they provide, see Figure 1. Specifically, an
intelligent optical core provides on-demand point-to-point connections with
quality of services attributes, i.e., “lightpaths”, which include (1) TDM
circuits or dedicated wavelength/fiber with guaranteed bandwidth, or (2) MPLS
or point-to-point 802.1 VLAN etc. augmented with QoS mechanism but do not
provide deterministic bandwidth guarantee. An example of an optical core is
Internet 2’s HOPI [HOPI]. An intelligent optical edge, on the other hand,
should be able to switch gigabit Ethernet (GbE) and 10 GbE Layer2 services
directly to a lightpath provisioned through the optical core, and it should
include secure mechanisms to review and characterize the access node
technology, to bypass bottlenecks due to firewalls and to set up secured
connections via appropriate control-plane protocols and/or web services. A
properly sized photonic switch and/or L2/L3 switches/routers situated in between
a set of high-end clusters and a long-haul transport facility is an example of
an intelligent optical edge.
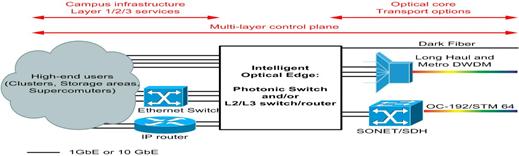
Figure 1: Combining an intelligent optical core with an intelligent optical edge and a flexible control plane
The GISNET project will explore how to better manage
the combination of an intelligent optical core and an intelligent optical edge,
by developing MonALISA-based web services to abstract control-plane protocols such
as GMPLS and provide APIs to the user applications. Our work will provide the
missing components required to effectively interface advanced networking initiatives
such as NLR and HOPI that serve as an intelligent optical core, and end-system
applications that have the potential to fully utilize these high-speed optical
cores and make an impact on various scientific disciplines.
A.3.6
Optical Testbed
Caltech, Starlight[STL01] and CERN have each deployed
a photonic switch in their network infrastructure and formed an optical
testbed. The goal of the testbed described below is to develop and test a
control plane to manage the optical backplane of future networks with multiple
waves between each node. Since the number of transatlantic and transcontinental
waves is limited, connections between the two sites are not deterministic, and
share the bandwidth with production and other experimental traffics. To
overcome this limitation, the concept of a “virtual fiber” has been introduced,
to emulate point-to-point connections between the two switches. A virtual fiber
is a layer 2 channel with Ethernet framing. From the photonic switch, the
virtual fiber appears like a dedicated link but the bandwidth, the path, the
delay and the jitter are not guaranteed and the path is not framing-agnostic.
The control plane being developed is based on MonALISA services, making it easy
to interface with other optical network testbeds such as HOPI, WAN-In-Lab,
GLIF/SURFnet, and UltraNet. Services to monitor and manage both Glimmerglass and
Calient switches via their TL1 interfaces have been written and are in
operation, but the use of GMPLS and UCLP [WCS+03] also is being studied. As the
development of the optical testbed progresses, we will also work on developing
“Optical Exchange Points” (OXP) at L.A. and Geneva, each of these points of
presence not only provides Layer 2 and Layer 3 connectivity, but also on-demand
optical connections at Layer1 as well. This new architecture is a first step
toward a hybrid circuit- and packet- switched network. Diagrams of the virtual
fiber concept and the Caltech OXP are shown below. We will also integrate these
with other optical switches in UltraLight, starting with the UCLP-managed
switches at Starlight and in Netherlight[NET03].
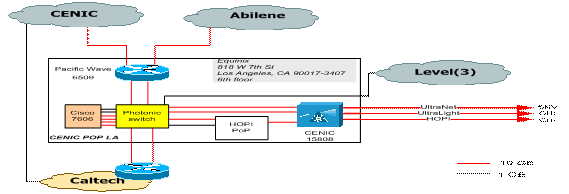
Figure 2: Caltech Optical Exchange point (Los-Angeles)
A.4.1 WAN-In-Lab
We propose to leverage WAN-In-Lab (WIL) by connecting it
across National Lambda Rail (NLR) to the
A.4.2 Extension of WAN-In-Lab Across National Lambda Rail
The WAN-In-Lab
extension will leverage developments at Caltech and the CENIC/NLR PoP in
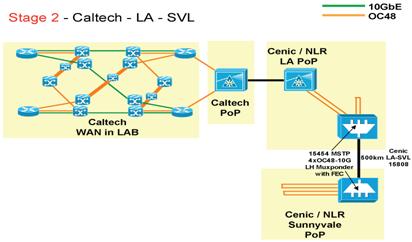
Figure 3 Stage 2: Extension of
WAN-In-Lab to
The connection of WAN-In-Lab to our L.A. PoP also will allow data flows generated in WIL to access external production and R&D networks, to form paths that are partly in the laboratory and partly in the field. Using our Calientphotonic switch (in Figure 3), WIL could be connected with the Cisco NLR research wave between L.A. and Chicago, the TeraGrid, Pacific Wave, the Internet2 Abilene production networks and HOPI sites. This would also allow network research teams, such as those associated with TeraGrid, to carry out similar studies combining some of their high bandwidth links with WIL in order to move some of out GISNET developments towards production-use.
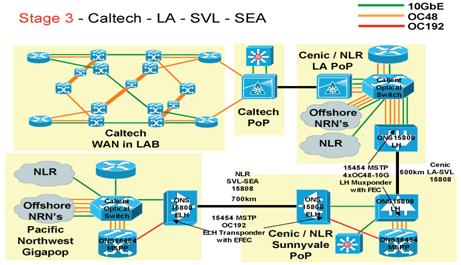
Figure 4 Stage 3:
Extension of WIL to
We have also worked with Cisco to develop a more complete
“Stage 3” future plan, to extend WIL to
LHC: Physics and Computing Challenges: High Energy Physics experiments are breaking new ground in the understanding of the unification of forces, the origin and stability of matter, and structures and symmetries that govern the nature of matter in our universe[BN03]. The Higgs particles, thought to be responsible for mass in the Universe, will typically only be produced in one interaction among 1013. A new generation of particles at the upper end of the LHC’s energy reach may only be produced at the rate of a few events per year, or one event in 1015 to 1016. Experimentation at increasing energy scales and luminosities, and the increasing sensitivity and complexity of measurements, have necessitated a growth in the scale of detectors and particle accelerators, and a corresponding increase in the size and geographic dispersion of scientific collaborations. The largest collaborations today, ATLAS[ATLAS] and CMS[CMS] – each encompass around 2000 physicists from 150 institutions in more than 35 countries.
The key to discovery is the ability to detect a signal with high efficiency, and in many cases (such as in the Higgs searches) to measure the energies and topology of the signal events precisely while suppressing large, and potentially overwhelming, backgrounds. Physicists must scan through the data repeatedly, devising new or improved methods of reconstructing, calibrating and isolating the “new physics” events with increasing selectivity as they progressively learn how to suppress the backgrounds.
HEP data volumes to be processed, analyzed and shared are expected to rise from the multi-Petabyte (1015 Byte) to the Exabyte (1018 Byte) range within the next 10-15 years, and the corresponding network speed requirements on each of the major links used in this field are expected to rise from the 10 Gigabit/sec to the Terabit/sec range during this period, as summarized in the following roadmap of major HENP network links [ICF001, CHEP04].
Table 1: Bandwidth Roadmap (in Gbps) for Major HENP Network Links
|
Year |
Production |
Experimental |
Remarks |
|
2001 |
0.155 |
0.622 – 2.5 |
SONET/SDH |
|
2002 |
0.622 |
2.5 |
SONET/SDH; DWDM; GigE Integration |
|
2003 |
2.5 |
10 |
DWDM; 1 & 10 GigE Integration |
|
2005 |
10 |
2-4 ´ 10 |
l Switch, l Provisioning |
|
2007 |
2–4 ´ 10 |
~10 ´ 10 (and 40) |
1st Gen. l Grids |
|
2009 |
~10 ´ 10 (or 1–2 ´ 40) |
~5 ´ 40 (or 20–50 ´ 10) |
40 Gbps l Switching |
|
2011 |
~5 ´ 40 (or ~20 ´ 10) |
~5 ´ 40 (or 100 ´ 10) |
2nd Gen. l Grids, Terabit networks |
|
2013 |
~Terabit |
~Multi-Terabit |
~Fill one fiber |
LHC Data Grids: The High Energy Physics (HEP) community
leads science in its pioneering efforts to develop globally-connected,
grid-enabled, data-intensive systems. Its efforts have led the LHC experiments
to adopt the Data Grid Hierarchy of 5 “Tiers” of globally distributed computing
and storage resources. Data at the experiment are stored at the rate of
100-1500 Mbytes/sec throughout the year, resulting in Petabytes per year of
stored and processed binary data that are accessed and processed repeatedly by
worldwide collaborators. Following initial processing and storage at the Tier0
facility at CERN, data are distributed over high-speed networks to
approximately 10 national Tier1 centers in the
Physicists developing the Data Grid Hierarchy in projects such as GriPhyN, iVDGL, PPDG and the LHC Grid project have realized that it is an idealization of the actual system that is required. Processing and analyzing the data requires the coordinated use of the entire ensemble of Tier-N facilities. Data flow among the Tiers will therefore be more dynamic and opportunistic, as thousands of physicists vie for shares of more local and more remote facilities of different sizes, for a wide variety of tasks of differing global and local priority, with different requirements in turnaround times (from seconds to hours), computational requirements (from processor-seconds to many processor-decades) and data volumes.
Recent estimates of the data rates and network bandwidth estimates between the Tier-N sites, and production-style “robust service challenges” across the Atlantic indicate that HEP network demands will reach 10 Gbps within the next year, followed by a need for scheduled and dynamic use of multiple 10-Gbps wavelengths by the time the LHC begins operation in 2007. The driving forces behind the network bandwidth requirements are that the “small” requests for data samples will often exceed a Terabyte in the early years of LHC operation, and could easily reach 10-100 Terabytes in the years following, with many requests per day coming from the global HEP community. This leads to the need to support Terabyte-scale transactions, where the data is transferred in minutes rather than many hours, so that many transactions per day can be completed. The likelihood of the transaction failing to complete is much smaller than in the case of many long transactions sharing the available network capacity for many hours. Taking the typical time to complete a transaction as 10-15 minutes, then a 1 Terabyte transaction will use a 10 Gbps link fully, and a 100 Terabyte transaction (e.g. in 2010 or 2015) would fully occupy a link of ~1 Tbps.
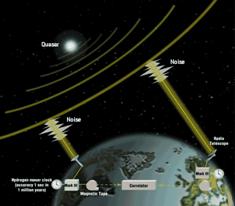
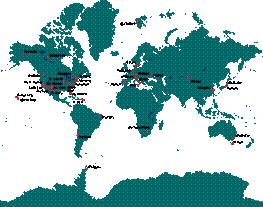
Figure 5: a) Simplified schematic of
traditional VLBI b) Locations of global VLBI stations
Very-Long Baseline Interferometry (VLBI) is a
radio-astronomy technique that simultaneously gathers data from a global array
of radio telescopes (up to about 20) and then processes this data by
cross-correlation between all possible pairs of telescopes to create the
equivalent of a single large radio telescope.
For astronomical studies, VLBI allows images of distant radio sources to
be made with resolutions of tens of microarcseconds,
far better than any optical telescope. For Earth science studies, VLBI provides
direct measurement of the vector between globally-separated telescopes with an
accuracy of ~1 cm and, by measuring the changes in baseline length over time,
yields motions of the tectonic plates with a precision of 0.1 mm/yr. Because VLBI is tied to the reference frame
defined by very distant radio objects, it is the only technique which can
fundamentally measure the orientation of the earth in space. Approximately 50 radio-telescopes,
distributed globally as shown in Fig. 5, participate in VLBI observations on a
regular basis.
Traditionally, VLBI data are collected locally on
magnetic tape or disk at sustained data rates of up to ~1 Gbps/station, which
are then physically shipped to central correlation facilities. 'e-VLBI' seeks to move this data in real-time
or near-real-time from the global array of radio telescopes to either a central
correlator facility or, in the future, distributed correlation facilities. Because the sensitivity of the VLBI
measurements improves as the data bandwidth increases, there are continuous
efforts to push data rates higher and higher; data rates of the order of
10Gbps/station are expected by the end of the decade, which are difficult or
prohibitively expensive to sustain via traditional recording methods.
As a demanding global network application, e-VLBI is
well suited to help evaluate and exploit the advances in understanding of the
performance and stability of heavily loaded networks, and to take advantage of
the tools provided within the GISNET framework.
Additionally, some special characteristics of e-VLBI data flow, such as
requirements for both real-time and near-real-time data flows, along with
data-loss tolerance, can help provide exploration of a broad network
operational space to help evaluate the theoretical underpinnings of GISNET, as
well as test the effectiveness of network control algorithms[WHI03].
S. Low
is the PI on three inter-related NSF grants on ultra-scale protocols for future
networks (the FAST Project): Optimal and
Robust TCP Congestion Control (ANI-0113425, with Doyle, 2001-4), Multi-Gbps TCP: Data Intensive Networks for
Science & Engineering (ANI-0230967, with Bunn, Doyle, Newman, 2002-5),
and WAN-In-Lab (EIA-0303620, with
Doyle, Newman, Psaltis, 2003-8). The first project studies the background
theory, the second proposal extends the theory, develops the FAST TCP
prototype, tests it in real networks, and explores deployment paths, while the
third project builds the critical experimental facility for our effort. Since
2002, Low and collaborators have published 13 journal/book chapter/magazine
articles and 14 conference papers, listed in the Reference Section.
In
addition to being a Co-PI with Low on 2 of the 3 proposals above, H. Newman is
PI of the UltraLight Project (PHY-0427110, 2004-8), which is developing a
trans- and intercontinental network testbed integrating high-speed data caches
and computing clusters, in support of the LHC scientific program. S. McKee, P.
Avery, and J. Ibarra are Co-PIs of UltraLight, and McKee heads the UltraLight
networking group. Newman also is PI of A
Next Generation Integrated Environment for Collaborative Work (ANI-0230937,
2002-5) that has developed the globally scalable VRVS system integrated with
MonALISA agent-based management services, on 47,000 host computers in 105
countries, and CMS Analysis: an
Interactive Grid-Enabled Environment (CAIGEE; PHY-0218937, 2003-4), a
founding project in the development of a Grid Analysis Environment for the LHC
physics community. J. Bunn is a Co-PI of the CAIGEE project. Newman is a Co-PI
of the CHEPREO project in charge of the cyberinfrastructure aspects, working
with Ibarra as PI, on the development of a Grid-Enabled Center for high energy
physics, education and outreach in Florida, in partnership with groups
development CMS Grid centers in Rio de Janeiro and Sao Paulo.
A. Whitney is PI of Development of Shared-Network Protocols and Strategies for e-VLBI
(ANI-0230759, 2003-05). In collaboration
with the MIT Computer Science and Artificial Intelligence Lab (CSAIL), this
project is developing protocols and strategies specially suited to the
characteristics of e-VLBI data streams on shared networks. He is also co-PI of Dynamic Resource Allocation for GMPLS Optical Networks (DRAGON)
(ANI-0335266, 2004-06), led by
S.Ranka:
ACI-0325459: Developing algorithms and framework for Medium ITR: A Data Mining and Exploration Middleware for Grid and
Distributed Computing with
Ibarra
is PI of the AMPATH [AMP01] project (SCI-0231844, 2002-05) and international
exchange an enabling high-performance network infrastructure that has resulted
in the interconnection of Latin American NRENs to the U.S. to foster effective
use of the technology for scientific and scholastic purposes, especially those
of interest to the U.S. science, research and education communities; and of the
WHREN-LILA [WHL01] (SCI-0441095, 2005-09)
project to create an all encompassing distributed exchange for the western
hemisphere, interconnect established international peering exchanges in North
America (Miami, Los Angeles, Seattle, Chicago and New York) with emerging
international peering exchanges in Latin America (Sao Paulo, Santiago and
Tijuana),
McKee was a Co-PI of the Web Lecture Archiving System for Professional Society Meetings, that developed a system to record speakers (audio, video, presentation) and make them available in near real-time, via a web-lecture archive object, achieving expert results without an expert operator. He is also a Co-PI of the NMI Development of GridNFS (SCI-0438298, 2005-7) that is developing a grid-aware high performance version of NFS V4[NFSv4].
A.8.1 Project Team Structure
Leadership: The
PI, Co-PIs and other senior personnel have extensive experience with the
management and successful execution of national-level scientific, networking
and Grid projects, including H. Newman (chair of the Standing Committee on
Inter-Regional Connectivity [SCI03] chair of the International Committee on
Future Accelerators [ICF03], chair of the US-CMS collaboration, PI for the
Particle Physics Data Grid), P. Avery (Director of the multi-disciplinary
GriPhyN and iVDGL Grid projects), J. Ibarra (PI of AMPATH), J. Shank (Executive Project Manager of
Management: The management team will consist of the PI as Director, the Co-PIs, and the Project and Technical Coordinators. The Project and Technical Coordinators will be appointed by the PI from the project personnel. The management team will manage the project, as a Steering Group, with input from the following bodies: (1) Network Research Group, engaged in the research aspects of GISNET, (2) Systems Development Group, engaged in the development of GISNET systems and their infrastructure; (3) Field Test and Deployment Group, tasked with deploying, measuring and testing the GISNET systems,; (4) Applications Group, representing end users and applications served by the GISNET network.
A.8.2 Program of Work
The GISNET collaboration plans to deliver a toolkit to enable the efficient, effective management of multiple flows across multiple possible network paths of varying types. To do this we plan to develop and deploy the software infrastructure of GISNET in 3 phases, matched to the 3 phase planning for UltraLight. GISNET’s networking research agenda on the fundamental understanding of the heterogeneous hybrid network involving heterogeneous resource allocation, protocol design, stability analysis and self-organizing network control will be carried out throughout these phases, interacting with the development work that we detail in the following. Further, these three phases of GISNET work will be marked by milestones synchronized to the needs of the GISNET network research and the driving applications from high energy physics and eVLBI. Throughout our R&D program we will regularly integrate GISNET tools into the production software used by ATLAS and CMS, as well as our eVLBI partners, making the results of GISNET available to our collaborators. See “Budget Justification” for more details.
In the first phase we plan to be able to manually select from three possible types of network paths for a given flow: 1) a best effort path utilizing the FAST protocol, 2) a MPLS tunnel augmented with QoS attributes to provide a variable sized “pipe” suitable to the flow or, 3) a lightpath (as available) connecting the relevant end points. The control plane will be manually configured by our engineering team for each request. Users’ requests will be addressed via phone or email. Reconfiguration will be done by remotely logging into the network equipment. This first step will allow us to clearly define (1) services that can be (or not be) offer to users, (2) interconnecting requirements to access other backbones (HOPI, CANARIE[CAN]) and (3) parameters that need to be specified by users to address a service request (end-to-end delay, loss rate, minimum bandwidth…). In parallel we will evaluate control planes available such as GMPLS or UCLP. Note the manual emphasis and limited deployment planned at this phase. The user will have access to system-wide data collected by the monitoring system and specialized agents and will be responsible for interpreting the data. The emphasis is on enabling user access to various types of paths, not on automating path selection and implementation via agents and self-learning systems. By the end of phase one, GISNET will (1) be able to support rudimentary data transfer between widely dispersed high energy physics data stores, (2) produce initial prototypes of monitoring and filtering algorithms describing a low-dimensional state space, and (3) develop and test initial protocols and parameter settings.
The second phase will augment the manual capabilities developed in phase one by adding self-learning algorithms fed by monitoring data collected by specialized agents as well as the theoretical steering from SOSTOOLS to allow a semi-autonomous capability. The network resources provisioning process is expected to be more sophisticated, automated and distributed. Provisioning software, appropriate protocols and routing/switching architecture will be deployed to locate suitable paths, schedule the resources in an environment of competing priority and detect failures. The system will help the user/application select an appropriate path based upon user input and the knowledge the tools have about the current system status and known, planned usage. By the end of phase two, GISNET will (1) be able to support manually steered data transfer between widely dispersed high energy physics data stores, (2) produce initial prototypes for optimally allocating resources based on rudimentary VO usage policies, (3) test SOSTOOLS in a realtime environment leading to initial protocol and parameter settings, and (4) determined optimal monitoring and filtering algorithms for describing a low-dimensional state space.
The last phase of GISNET will focus on delivering a system capable of automating as much of the path selection and management as possible. Real-time agents combined with planning from the theory predictors will deliver recommendations to a higher level service responsible for path creation in support of user flows. GISNET will attempt to address the issues associated with building lightpaths end-to-end on a global basis and doing so in an operationally sustainable fashion. Authentication, Authorization and Accounting (AAA) (using CLARENS and existing Grid infrastructure developed in GriPhyN and PPDG) will play a crucial role in this phase. We envision a system which, while still supporting user “reservations”, attempts to dynamically optimize the real-time set of flows across the infrastructure by organizing the types of paths assigned to each. By the end of phase three, GISNET will (1) be able to support fully automated data transfer between widely dispersed high energy physics data stores, (2) produce production level services for optimally allocating resources, (3) integrate SOSTOOLS for real-time estimation of protocol parameter stability regions, and (4) provide a specified quality of service for per-user and per-VO data flows.
The Educational Outreach program will be based at FIU, leveraging its CHEPREO [CHE03] and CIARA [CIA03] activities. GISNET will train aspiring computer and discipline science students in state of the art network and distributed system science and technologies, using the GISNET interactive toolset. This should lead them to become part of the revolution in networking and collaborative data-intensive information systems expected over the next decade. These rapid advances in our fundamental understanding and ability to use long distance networks effectively will have innovative implications to science and, ultimately, in everyday life.
Our E&O program has several innovative and unique dimensions: (1) integration of students in the core research and application integration activities at participating universities; (2) utilization of the GISNET testbed to carry out student-defined networking projects; (3) opportunities for FIU students (especially minorities) to participate in project activities; (4) GISNET involvement through the Research Experiences for Undergraduate program, graduate programs, through CIARA, and teacher programs, such as Research Experiences for Teachers; (5) exploitation of GISNET’s international reach to allow US students to participate in research experiences using a global network research and development testbed, from their home institutions. GISNET’s E/O efforts will be coordinated and integrated with other projects including CHEPREO, CIARA, GriPhyN, iVDGL, e-VLBI, and PPDG.
This proposal dedicates 5% of its funding to directly support innovative immersive summer research projects. Students from all GISNET institutions will prepare collaborative research projects utilizing the GISNET toolkit. Their participation will be structured as collaborators in the project, where projects will be defined in terms of outcome with students working as part of the GISNET research community. The goal is to emulate the professional researcher role, thus providing deep insights into the nature of network research, and its key role and impact on leading-edge international projects in the physics and astronomy communities. The dedicated E/O funding will be used to support a one-week hands-on tutorial workshop to prepare students for use of the GISNET toolset. The workshop will be held annually at the beginning of summer. During the workshop, project teams will be organized and assignments detailed. The research projects will begin upon students returning to their home institution. Groups will maintain communication among themselves and with the GISNET collaboration through regular VRVS conferencing. At the end of the summer, results will be presented to the GISNET collaboration and archived. In addition to the clear benefit to students from the opportunity to work with state-of-the-art network research tools, the GISNET toolset will be improved from the rigorous testing by students completing their projects.
GISNET E/O funds will support student travel, supplies, and coordination of the summer workshop as well as evaluation of the impact of the summer research projects. Specifically, travel for 15 students, supplies and limited participant support costs, and coordination is provided. Additional students will be invited to participate and funded through supplemental grants or other sources. Speakers and tutorial leaders will be composed of GISNET PIs and Senior Researchers as well as several invited guests. Travel funds for these personnel are not included. GISNET PIs and Senior Researchers will identify the research projects. Support for the student summer research will be provided through several identified existing REU-like programs as well as dedicated REU proposals to be submitted. In the case that the new REU proposal is not supported, the workshop will still be carried out with the research projects being adjusted to fit the available funding. The GISNET budget includes consultation and education to individual observatories in support of e-VLBI. Separately funded by NSF, Haystack Observatory participates in E&O through continuing sponsorship of international e-VLBI workshops and REU students.