Data Intensive Grids for High Energy Physics
Julian J. Bunn
Center for
Advanced Computing Research
California Institute of Technology
Pasadena, CA 91125, USA
julian@cacr.caltech.edu
�����������������������������
1.
Introduction: Scientific Exploration at the High Energy Frontier
The major high energy
physics experiments of the next twenty years will break new ground in our
understanding of the fundamental interactions, structures and symmetries that govern
the nature of matter and space-time. Among the principal goals are to find the
mechanism responsible for mass in the universe, and the �Higgs� particles
associated with mass generation, as well as the fundamental mechanism that led
to the predominance of matter over antimatter in the observable cosmos.
The largest collaborations today, such as CMS [[1]]
and ATLAS [[2]]
who are building experiments for CERN�s Large Hadron Collider (LHC) program [[3]],
each encompass 2000 physicists from 150 institutions in more than 30 countries.
Each of these collaborations include 300-400 physicists in the
Collaborations on this
global scale would not have been attempted if the physicists could not plan on
excellent networks: to interconnect the physics groups throughout the lifecycle
of the experiment, and to make possible the construction of Data Grids capable
of providing access, processing and analysis of massive datasets. These
datasets will increase in size from Petabytes to Exabytes (1 EB = 1018 Bytes)
within the next decade.
An impression of the
complexity of the LHC data can be gained from Figure 1, which shows simulated
particle trajectories in the inner �tracking� detectors of CMS. The particles
are produced in proton-proton collisions that result from the crossing of two
proton bunches. A rare proton-proton interaction (approximately 1 in 1013)
resulting in the production of a Higgs particle that decays into the
distinctive signature of four muons, is buried in 30 other �background�
interactions produced in the same crossing, as shown in the upper half of the
figure. The CMS software has to filter out the background interactions by
isolating the point of origin of the high momentum tracks in the interaction
containing the Higgs. This filtering produces the clean configuration shown in
the bottom half of the figure. At this point, the (invariant) mass of the Higgs
can be measured from the shapes of the four muons tracks (colored green) which
are its decay products.
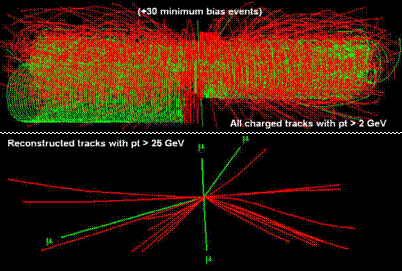
Figure 1 A simulated decay of the
Higgs Boson into four Muons. The lower picture shows the high momentum charged
particles in the Higgs event . The upper picture
shows how the event would actually appear in the detector, submerged beneath
many other �background� interactions.
2.
HEP Challenges: at the Frontiers of Information Technology
Realizing the scientific
wealth of these experiments presents new problems in data access, processing
and distribution, and collaboration across national and international networks,
on a scale unprecedented in the history of science. The information technology
challenges include:
�
Providing rapid
access to data subsets drawn from massive data stores, rising from Petabytes in
2002 to ~100 Petabytes by 2007, and Exabytes (1018 bytes) by
approximately 2012 to 2015.
�
Providing secure,
efficient and transparent managed access to heterogeneous worldwide-distributed
computing and data handling resources, across an ensemble of networks of
varying capability and reliability
�
Tracking the
state and usage patterns of computing and data resources in order to make
possible rapid turnaround as well as efficient utilization of global resources
�
Matching resource
usage to policies set by the management of the experiments� collaborations over
the long term; ensuring that the application of the decisions made to support
resource usage among multiple collaborations that share common (network and
other) resources are internally consistent
�
Providing the
collaborative infrastructure that will make it possible for physicists in all
world regions to contribute effectively to the analysis and the physics
results, particularly while they are at their home institutions
�
Building
regional, national, continental and transoceanic networks, with bandwidths
rising from the Gigabit/sec to the Terabit/sec range over the next decade[1]
All of these challenges need
to be met, so as to provide the first integrated, managed, distributed system
infrastructure that can serve �virtual organizations� on the global scale
3.
Meeting the Challenges: Data Grids as Managed Distributed Systems
��� for Global Virtual Organizations
The LHC experiments have thus adopted the �Data Grid
Hierarchy� model (developed by the MONARC[2] project) shown
schematically in the figure below. This five-tiered model shows data at the
experiment being stored at the rate of 100 � 1500 Mbytes/sec throughout the
year, resulting in many Petabytes per year of stored and processed binary data,
which are accessed and processed repeatedly by the worldwide collaborations
searching for new physics processes. Following initial processing and storage
at the �Tier0� facility at the CERN laboratory site, the processed data is
distributed over high speed networks to ~10-20 national �Tier1� centers in the
The successful use of this global ensemble of systems to
meet the experiments� scientific goals depends on the development of Data Grids
capable of managing and marshalling the �Tier-N�� resources, and supporting collaborative
software development by groups of varying sizes spread around the globe. The
modes of usage and prioritization of tasks need to ensure that the physicists�
requests for data and processed results are handled within a reasonable
turnaround time, while at the same time the collaborations� resources are used
efficiently.
The GriPhyN [[8]],
PPDG [[9]],
iVDGL [[10]],
EU Datagrid [[11]],
DataTAG [[12]],
the LHC Computing Grid [[13]]
and national Grid projects in
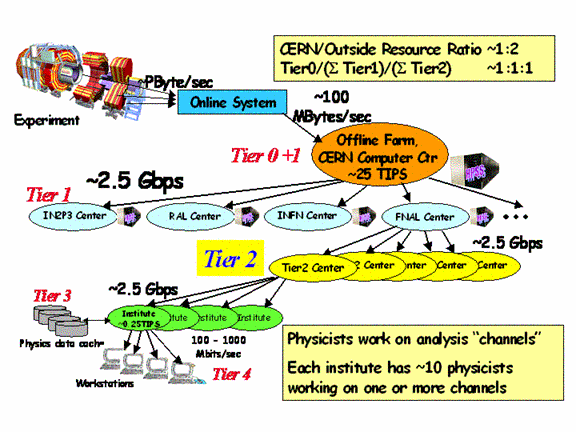
Figure 2 The LHC Data Grid Hierarchy model.
This was first proposed by the MONARC Collaboration in 1999.
The data rates and network
bandwidths shown in Figure 2 are per LHC experiment, for the first year of LHC
operation. The numbers shown correspond to a conservative �baseline�,
formulated using a 1999-2000 evolutionary view of the advance of network
technologies over the next five years [[14]].
The reason for this is that the underlying �Computing Model� used for the LHC
program assumes a very well-ordered, group-oriented and carefully scheduled
approach to data transfers supporting the production processing and analysis of
data samples. More general models supporting more extensive access to data
samples on demand [[15]]
would clearly lead to substantially larger bandwidth requirements.
4. Emergence of HEP Grids: Regional Centers
It was widely
recognized from the outset of planning for the LHC Experiments, that the
computing systems required to collect, analyze and store the physics data would
need to be distributed and global in scope. In the mid-1990s, when planning for
the LHC computing systems began, calculations of the expected data rates, the
accumulated yearly volumes, and the required processing power, led many to
believe that HEP would need a system whose features would not have looked out
of place in a science fiction novel. However, careful extrapolations of
technology trend lines, and detailed studies of the computing industry and its
expected development [[16]] encouraged the Experiments that a suitable system could be
designed and built in time for the first operation of the LHC collider in 2005[5].
In particular, the studies showed that utilizing computing resources external
to CERN, at the collaborating institutes (as had been done on a limited
scale� for the LEP experiments) would
continue to be an essential strategy, and that a global computing system
architecture would need to be developed. (It is worthwhile noting that, at that
time, the Grid was at an embryonic stage of development, and certainly not a
concept the Experiments were aware of.) Accordingly, work began in each of the
LHC Experiments on formulating plans and models for how the computing could be
done. The CMS Experiment�s �Computing Technical Proposal�, written in 1996, is
a good example of the thinking that prevailed at that time. Because the
computing challenges were considered so severe, several projects were
instigated by the Experiments to explore various aspects of the field. These
projects included RD45 [[17]], GIOD, MONARC and ALDAP, as discussed in the following
sections.
4.1
The CMS Computing Model Circa 1996
The CMS computing model as
documented in the CMS �Computing Technical Proposal� was designed to present
the user with a simple logical view of all objects needed to perform physics
analysis or detector studies. The word �objects� was used loosely to refer to
data items in files (in a traditional context) and to transient or persistent
objects (in an OO programming context). The proposal explicitly noted that,
often, choices of particular technologies had been avoided since they depended
too much on guesswork as to what would make sense or be available in 2005. On
the other hand, the model explicitly assumed the use of OO analysis, design and
programming. With these restrictions, the model�s fundamental requirements were
simply summed up as:
- objects which cannot be recomputed must be stored
somewhere;
- physicists at any CMS institute should be able to
query any objects (re-computable or not re-computable) and retrieve those
results of the query which can be interpreted by a human;
- the resources devoted to achieving 1 and 2 should
be used as efficiently as possible.�
Probably the most interesting
aspect of the model was its treatment of how to make the CMS physics data
(objects) persistent. The Proposal states �at
least one currently available ODBMS appears quite capable of handling the data
volumes of typical current experiments and requires no technological
breakthroughs to scale to the data volumes expected during CMS operation. Read
performance and efficiency of the use of storage are very similar to
Fortran/Zebra systems in use today. Large databases can be created as a
federation of moderate (few GB) sized databases, many of which may be on tape
to be recalled automatically in the event of an �access fault�. The current
product supports a geographically distributed federation of databases and
heterogeneous computing platforms. Automatic replication of key parts of the
database at several sites is already available and features for computing
(computable) objects on demand are recognized as strategic developments.�
It is thus evident that the
concept of a globally distributed computing and data-serving system for CMS was
already firmly on the table in 1996. The proponents of the model had already
begun to address the questions of computing �on demand�, replication of data in
the global system, and the implications of distributing computation on behalf
of end user physicists.
Some years later, CMS
undertook a major requirements and consensus building effort to modernize this
vision of a distributed computing model to a Grid-based computing
infrastructure. Accordingly, the current vision sees CMS computing as an
activity that is performed on the �CMS Data Grid System� whose properties have
been described in considerable detail [[18]].
The CMS Data Grid System specifies a division of labor between the Grid
projects (described in this Chapter) and the CMS core computing project.
Indeed, the CMS Data Grid System is recognized as being one of the most
detailed and complete visions of the use of Grid technology among the LHC
experiments.�
4.2 GIOD
In late 1996, Caltech�s High
Energy Physics department, its Center for Advanced Computing Research (CACR),
CERN�s Information Technology Division, and Hewlett Packard Corporation
initiated a joint project called "Globally Interconnected Object
Databases". The GIOD
Project [19] was designed to address the key issues of wide area
network-distributed data access and analysis for the LHC experiments. It was
spurred by the advent of network-distributed Object Database Management
Systems, whose architecture held the promise of being scalable up to the
multi-Petabyte range required by the LHC experiments. GIOD was set up to
leverage the availability of a large (200,000 MIP) HP Exemplar supercomputer,
and other computing and data handling systems at CACR as of mid-1997. It
addressed the fundamental need in the HEP community at that time to prototype
Object Oriented software, databases and mass storage systems, which were at the
heart of the LHC and other (e.g. BaBar) major experiments' data analysis plans.
The project plan specified the use of high speed networks, including ESnet, and
the transatlantic link managed by the Caltech HEP group, as well as next
generation networks (CalREN2 in
The GIOD plan (formulated by
Bunn and Newman in late 1996) was to develop an understanding of the
characteristics, limitations, and strategies for efficient data access using
the new technologies. A central element was the development of a prototype
"
The GIOD project produced
prototype database, reconstruction, analysis and visualization systems. This
allowed the testing, validation and development of strategies and mechanisms
that showed how the implementation of massive distributed systems for data
access and analysis in support of the LHC physics program would be possible.
Deployment and tests of the Terabyte-scale GIOD database were made at a few US
universities and laboratories participating in the LHC program. In addition to
providing a source of simulated events for evaluation of the design and
discovery potential of the CMS experiment, the database system was used to
explore and develop effective strategies for distributed data access and
analysis at the LHC. These tests used local, regional, national and
international backbones, and made initial explorations of how the distributed
system worked, and which strategies were most effective.� The GIOD Project terminated in 2000, its
findings documented [[19]], and was followed by several related
projects described below.
4.3 MONARC
The MONARC[6]
project was set up in 1998 to model and study the worldwide-distributed Computing
Models for the LHC experiments. This project studied and attempted to optimize
the site architectures and distribution of jobs across a number of regional
computing centres of different sizes and capacities, in particular larger
Tier-1 centres, providing a full range of services, and smaller Tier-2 centres.
The architecture developed by MONARC is described in the final report [[20]]
of the project.
MONARC provided key information on the design and
operation of the Computing Models for the experiments, who had envisaged
systems involving many hundreds of physicists engaged in analysis at
laboratories and universities around the world. �The models encompassed a complex set of wide-area,
regional and local-area networks, a heterogeneous set of compute- and
data-servers, and an undetermined set of priorities for group-oriented and
individuals' demands for remote data and compute resources. Distributed systems
of the size and complexity envisaged did not yet exist, although systems of a
similar size were predicted by MONARC to come into operation and be
increasingly prevalent by around 2005.
The project met its major milestones, and fulfilled
its basic goals, including:
�
identifying first-round baseline Computing Models that
could provide viable (and cost-effective) solutions to meet the basic
simulation, reconstruction and analysis needs of the LHC experiments
�
providing a powerful (CPU and time efficient)
simulation toolset [[21]]
that enabled further studies and optimisation of the models,
�
providing guidelines for the configuration and
services of Regional Centres, and
�
providing an effective forum where representatives of
actual and candidate Regional Centres may meet and develop common strategies
for LHC Computing.
In particular, the MONARC
work led to the concept of a Regional Centre hierarchy, as shown in Figure 2, as the best candidate for a cost-effective and
efficient means of facilitating access to the data and processing resources. �The hierarchical
layout was also believed to be well-adapted to meet local needs for support in
developing and running the software, and carrying out the data analysis with an
emphasis on the responsibilities and physics interests of the groups in each
world region.� In the later phases of the
MONARC project, it was realised that computational Grids, extended to the
data-intensive tasks and worldwide scale appropriate to the LHC, could be used
and extended (as discussed in Section 9) to develop the workflow and resource
management tools needed to effectively manage a worldwide-distributed �Data
Grid� system for HEP.
4.4
ALDAP
The NSF funded three-year
ALDAP project (which terminated in 2002) concentrated on the data organization
and architecture issues for efficient data processing and access for major
experiments in HEP and astrophysics. ALDAP was a collaboration between Caltech,
and the Sloan Digital Sky Survey (SDSS[7]) teams at
The Sloan Digital Sky Survey
(SDSS) is digitally mapping about half of the northern sky in five filter bands
from UV to the near IR. SDSS is one of the first large physics experiments to
design an archival system to simplify the process of �data mining� and shield
researchers from the need to interact directly with any underlying complex
architecture.
The need to access these data
in a variety of ways requires it to be organized in a hierarchy and analyzed in
multiple dimensions, tuned to the details of a given discipline. But the
general principles are applicable to all fields. To optimize for speed and
flexibility there needs to be a compromise between fully ordered (sequential)
organization, and totally �anarchic�, random arrangements. To quickly access
information from each of many �pages� of data, the pages must be arranged in a
multidimensional mode in a neighborly fashion, with the information on each
page stored judiciously in local clusters. These clusters themselves form a
hierarchy of further clusters. These were the ideas that underpinned the ALDAP
research work.
Most of the ALDAP project goals were achieved.
Besides them, the collaboration yielded several other indirect benefits. It led
to further large collaborations, most notably when the ALDAP groups teamed up
in three major successful ITR projects: GriPhyN, iVDGL and NVO. In addition,
one of the ALDAP tasks undertaken won a prize in the Microsoft-sponsored
student Web Services contest. The �SkyServer�[[22]],
built in collaboration with Microsoft as an experiment in presenting complex data
to the wide public, continues to be highly successful, with over 4 million web
hits in its first 10 months.
5.
HEP Grid Projects
In this
section we introduce the major HEP Grid projects. Each of them has a different
emphasis: PPDG is investigating short term infrastructure solutions to meet the
mission-critical needs for both running particle physics experiments and those
in active development (such as CMS and ATLAS). GriPhyN is concerned with
longer-term R&D on Grid-based solutions for, collectively, Astronomy,
Particle Physics and Gravity Wave Detectors. The iVDGL �international Virtual
Data Grid Laboratory� will provide global testbeds and computing resources for
those experiments. The EU DataGrid has similar goals to GriPhyN and iVDGL, and
is funded by the European Union. LCG is a CERN-based collaboration focusing on
Grid infrastructure and applications for the LHC experiments. Finally,
CrossGrid is another EU-funded initiative that extends Grid work to eleven
countries not included in the EU DataGrid. There are several other smaller Grid
projects for HEP, which we do not cover here due to space limitations.
5.1
PPDG
The Particle
Physics Data Grid (www.ppdg.net )
collaboration was formed in 1999 to address the need for Data Grid services to
enable the worldwide distributed computing model of current and future
high-energy and nuclear physics experiments. Initially funded from the
Department of Energy�s NGI program and later from the MICS[8]
and HENP[9]
programs, it has provided an opportunity for early development of the Data Grid
architecture as well as for the evaluation of some prototype Grid middleware.
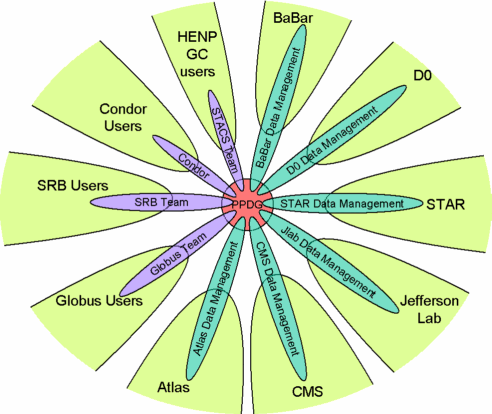
Figure 3 Showing the collaboration links between PPDG and the experiments and user communities
PPDG�s second
round of funding is termed the Particle Physics Data Grid Collaboratory Pilot.
This phase is concerned with developing, acquiring and delivering vitally
needed Grid-enabled tools to satisfy the data-intensive requirements of
particle and nuclear physics. Novel mechanisms and policies are being
vertically integrated with Grid middleware and experiment-specific applications
and computing resources to form effective end-to-end capabilities. As indicated
in the diagram above, PPDG is a collaboration of computer scientists with a
strong record in distributed computing and Grid technology, and physicists with
leading roles in the software and network infrastructures for major high-energy
and nuclear experiments. A three-year program has been outlined for the project
that takes full advantage of the strong driving force provided by currently
operating physics experiments, ongoing Computer Science projects and recent
advances in Grid technology. The PPDG goals and plans are ultimately guided by
the immediate, medium-term and longer-term needs and perspectives of the
physics experiments, and by the research and development agenda of the CS
projects involved in PPDG and other Grid-oriented efforts.
5.2
GriPhyN
The GriPhyN (Grid Physics
Network � http://www.pgriphyn.org� ) project is a collaboration of computer
science and other IT researchers and physicists from the ATLAS, CMS, LIGO and
SDSS experiments. The project is focused on the creation of Petascale Virtual
Data Grids that meet the data-intensive computational needs of a diverse
community of thousands of scientists spread across the globe. The concept of
Virtual Data encompasses the definition and delivery to a large community of a
(potentially unlimited) virtual space of data products derived from
experimental data.� In this virtual data
space, requests can be satisfied via direct access and/or computation, with
local and global resource management, policy, and security constraints
determining the strategy used.�
Overcoming this challenge and realizing the Virtual Data concept
requires advances in three major areas:
- Virtual data technologies.� Advances
are required in information models and in new methods of cataloging, characterizing,
validating, and archiving software components to implement virtual data
manipulations
- Policy-driven request planning and scheduling of
networked data and computational resources.� Mechanisms
are required for representing and enforcing both local and global policy
constraints and new policy-aware resource discovery techniques.
- Management of transactions and task-execution
across national-scale and worldwide virtual organizations.� New
mechanisms are needed to meet user requirements for performance,
reliability, and cost.� Agent
computing will be important to permit the Grid to balance user
requirements and grid throughput, with fault tolerance.
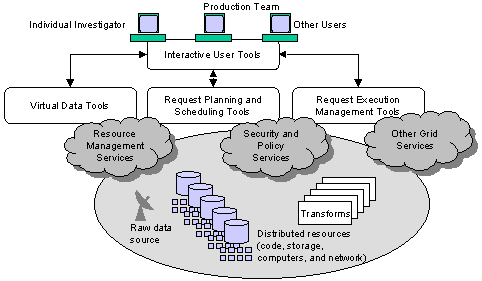
Figure 4 A production Grid, as envisaged by GriPhyN,
showing the strong integration of data generation, storage, computing and
network facilities, together with tools for scheduling, management and
security.
The GriPhyN project is
primarily focused on achieving the fundamental IT advances required to create
Petascale Virtual Data Grids, but is also working on creating software systems
for community use, and applying the technology to enable distributed,
collaborative analysis of data.�
A multi-faceted,
domain-independent Virtual Data Toolkit is being created and used to prototype
the virtual data Grids, and to support the CMS, ATLAS, LIGO, and SDSS analysis
tasks.
5.3
iVDGL
The iVDGL
�international Virtual Data Grid Laboratory� (http://www.ivdgl.org
) has been funded to provide a global computing resource for several leading
international experiments in physics and astronomy. These experiments include
the Laser Interferometer Gravitational-wave Observatory (LIGO), the ATLAS and
CMS experiments, the
Sloan Digital Sky Survey (SDSS),
and the National Virtual Observatory (NVO).
For these projects the powerful global computing resources available through
the iVDGL should enable new classes of data intensive algorithms that will lead
to new scientific results. Other application groups affiliated with the NSF
supercomputer centers and EU projects are also taking advantage of the iVDGL
resources. Sites in
As part of the
iVDGL project, a Grid Operations Center (GOC) has been created. Global services
and centralized monitoring, management, and support functions are being
coordinated by the GOC, which is located at
5.4
DataGrid
The European
DataGrid (eu-datagrid.web.cern.ch) is a project funded by the European Union
with the aim of setting up a computational and data-intensive grid of resources
for the analysis of data coming from scientific exploration. Next generation
science will require co-ordinated resource sharing, collaborative processing
and analysis of huge amounts of data produced and stored by many scientific
laboratories belonging to several institutions.
The main goal
of the DataGrid initiative is to develop and test the technological infrastructure
that will enable the implementation of scientific �collaboratories� where
researchers and scientists will perform their activities regardless of
geographical location. It will also allow interaction with colleagues from
sites all over the world, as well as the sharing of data and instruments on a
scale previously unattempted. The project is devising and developing scalable
software solutions and testbeds in order to handle many PetaBytes of
distributed data, tens of thousand of computing resources (processors, disks,
etc.), and thousands of simultaneous users from multiple research institutions.
The DataGrid
initiative is led by CERN, together with five other main partners and fifteen
associated partners. The project brings together the following European leading
research agencies: the European Space Agency (ESA),
DataGrid is an
ambitious project. Its development benefits from many different kinds of
technology and expertise. The project spans three years, from 2001 to 2003,
with over 200 scientists and researchers involved.
The DataGrid
project is divided into twelve Work Packages distributed over four Working
Groups: Testbed and Infrastructure, Applications, Computational & DataGrid
Middleware, Management and Dissemination. The figure below illustrates the
structure of the project and the interactions between the work packages.
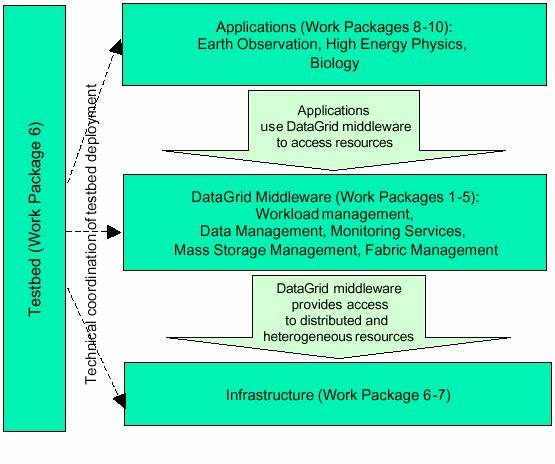
Figure 5 Showing the structure of the EU DataGrid
Project, and its component Work Packages
5.5
LCG
The job of
CERN�s LHC Computing Grid Project (LCG � http://lhcgrid.web.cern.ch
) is to prepare the computing infrastructure for the simulation, processing and
analysis of LHC data for all four of the LHC collaborations. This includes both
the common infrastructure of libraries, tools and frameworks required to
support the physics application software, and the development and deployment of
the computing services needed to store and process the data, providing batch
and interactive facilities for the worldwide community of physicists involved
in the LHC.
The first
phase of the project, from 2002 through 2005, is concerned with the development
of the application support environment and of common application elements, the
development and prototyping of the computing services and the operation of a
series of computing data challenges of increasing size and complexity to
demonstrate the effectiveness of the software and computing models selected by
the experiments. During this period there will be two series of important but
different types of data challenge under way: computing data challenges that
test out the application, system software, hardware and computing model, and
physics data challenges aimed at generating data and analysing it to study the
behaviour of the different elements of the detector and triggers. During this
R&D phase the priority of the project is to support the computing data
challenges, and to identify and resolve problems that may be encountered when
the first LHC data arrives. The physics data challenges require a stable
computing environment, and this requirement may conflict with the needs of the
computing tests, but it is an important goal of the project to arrive rapidly
at the point where stability of the grid prototype service is sufficiently good
to absorb the resources that are available in Regional Centres and CERN for
physics data challenges.
This first
phase will conclude with the production of a Computing System Technical Design
Report, providing a blueprint for the computing services that will be required
when the LHC accelerator begins production. This will include capacity and
performance requirements, technical guidelines, costing models, and a
construction schedule taking account of the anticipated luminosity and
efficiency profile of the accelerator.
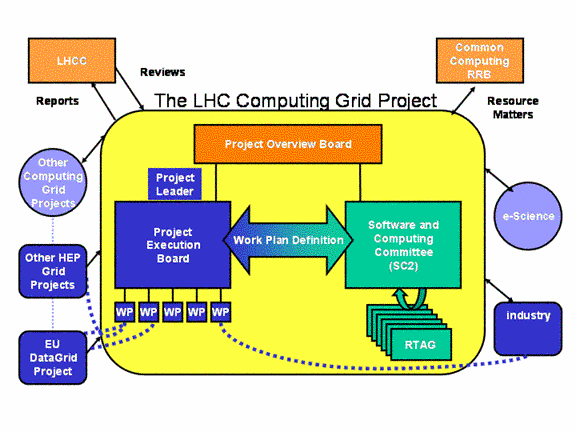
Figure 6 The organizational structure of the LHC
Computing Grid, showing links to external projects and industry.
A second phase
of the project is envisaged, from 2006 through 2008, to oversee the
construction and operation of the initial LHC computing system.
5.6
CrossGrid
CrossGrid (http://www.crossgrid.org) is a European
project developing, implementing and exploiting new Grid components for
interactive compute- and data intensive applications such as simulation and
visualisation for surgical procedures, flooding crisis team decision support
systems, distributed data analysis in high energy physics, and air pollution
combined with weather forecasting. The elaborated methodology, generic
application architecture, programming environment, and new Grid services are
being validated and tested on the CrossGrid testbed, with an emphasis on a user
friendly environment. CrossGrid collaborates closely with the Global Grid Forum
and the DataGrid project in order to profit from their results and experience,
and to ensure full interoperability. The primary objective of CrossGrid is to
further extend the Grid environment to a new category of applications of great
practical importance. Eleven European countries are involved.
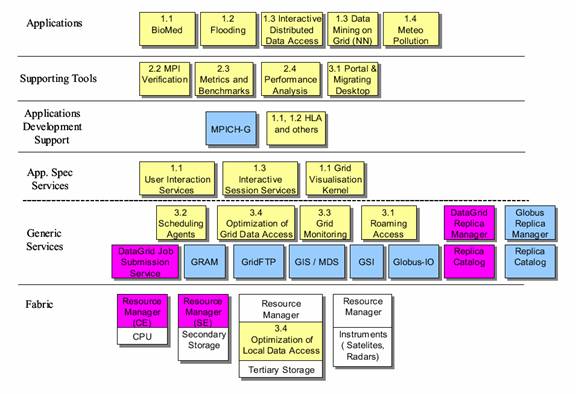
Figure 7 The CrossGrid Architecture
The essential novelty of the
CrossGrid project consists in extending the Grid to a completely new and
socially important category of applications. The characteristic feature of
these applications is the presence of a person in a processing loop, with a
requirement for real-time response from the computer system. The chosen
interactive applications are both compute- and data-intensive.
6.� Example Architectures and Applications
In this section
we take a look at how HEP experiments are currently making use of the Grid, by
introducing a few topical examples of Grid-based architectures and
applications.
6.1
TeraGrid Prototype
The beneficiary of NSF�s Distributed
Terascale Facility (DTF) solicitation was the TeraGrid project
(www.teragrid.org), a collaboration between Caltech, SDSC, NCSA and
TeraGrid is strongly
supported by the physics community participating in the LHC, through the the PPDG,
GriPhyN and iVDGL projects, due to its massive computing capacity, leading edge
network� facilities, and planned
partnerships with distributed systems in Europe.�
As part of the planning work
for the TeraGrid proposal, a successful "preview" of its potential
use was made, in which a highly compute and data intensive Grid task for the
CMS experiment was distributed between facilities at Caltech, Wisconsin and
NCSA. The TeraGrid test runs were initiated at Caltech, by a simple script
invocation. The necessary input files were automatically generated and, using
Condor-G[12],
a significant number of
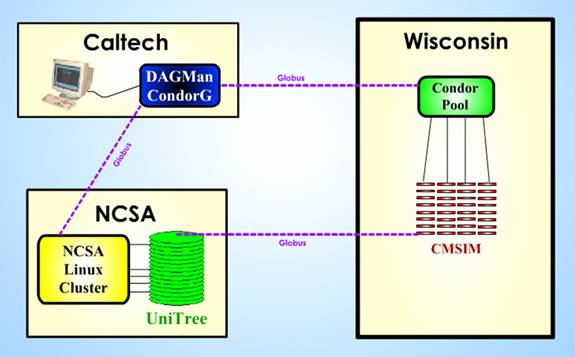
Figure 8 Showing the Grid-based Production of
6.2
MOP for Grid-Enabled Simulation Production
The MOP[13]
(short for �CMS Monte Carlo Production�) system was designed to provide the CMS
experiment with a means for distributing large numbers of simulation tasks
between many of the collaborating institutes. The MOP system comprises task
description, task distribution and file collection software layers. The GDMP
system (a Grid-based file copy and replica management scheme using the Globus
toolkit) is an integral component of MOP, as is the Globus Replica Catalogue.
Globus software is also used for task distribution. The task scheduler is the
�Gridified� version of the Condor scheduler, Condor-G. In addition, MOP
includes a set of powerful task control scripts developed at FermiLab.
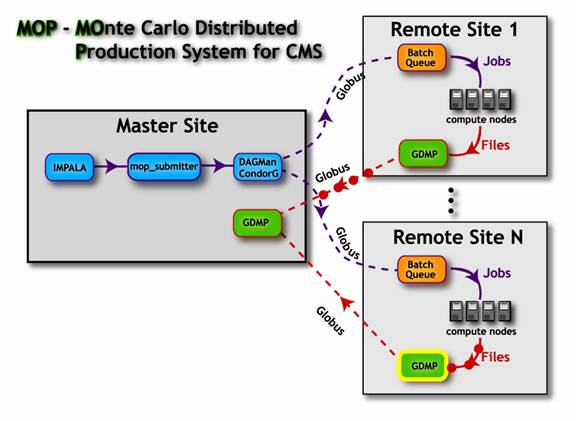
Figure 9 The MOP System, as demonstrated at� SuperComputing 2001. In this schematic are
shown the software components, and the locations at which they execute. Of
particular note is the use of the GDMP Grid tool.
�The MOP development goal was to demonstrate
that coordination of geographically distributed system resources for production
was possible using Grid software. Along the way, the development and refinement
of MOP aided the experiment in evaluating the suitability, advantages and
shortcomings of various Grid tools. MOP developments to support future
productions of simulated events at US institutions in CMS are currently
underway.�
6.3
GRAPPA
GRAPPA is an
acronym for Grid Access Portal for Physics Applications. The preliminary goal
of this project in the ATLAS experiment was to provide a simple point of access
to Grid resources on the U.S. ATLAS Testbed. GRAPPA is based on the use of a
Grid-enabled portal for physics client applications. An initial portal
prototype developed at the Extreme! Computing Laboratory at
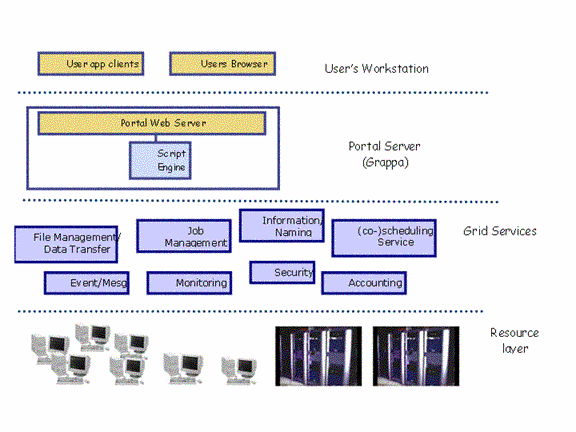
Figure 10 Showing the architecture of
the ATLAS "GRAPPA" system
The GRAPPA[14] user
authenticates to the portal using a GSI credential; a proxy credential is then
stored so that the portal can perform actions on behalf of the user (such as
authenticating jobs to a remote compute resource).� The user can access any number of active notebooks
within their notebook database.� An
active notebook encapsulates a session and consists of HTML pages describing
the application, forms specifying the job's configuration, and Java Python
scripts for controlling and managing the execution of the application.� These scripts interface to Globus services in
the GriPhyN Virtual Data Toolkit and have interfaces following the Common
Component Architecture (CCA) Forum's specifications. This allows them to
interact with and be used in high-performance computation and communications
frameworks such as Athena.
Using the XCAT
Science Portal tools, GRAPPA is able to use Globus credentials to perform
remote task execution, store user's parameters for re-use or later
modification, and run the ATLAS Monte Carlo simulation and reconstruction
programs.� Input file staging and
collection of output files from remote sites is handled by GRAPPA. Produced
files are registered in a replica catalog provided by the Particle Physics Data
Grid product MAGDA[15],
developed at Brookhaven National Laboratory.�
Job monitoring features include summary reports obtained from requests
to the Globus Resource Allocation Manager (GRAM[16]).
Metadata from job sessions are captured to describe dataset attributes using
the MAGDA catalog.
6.4 SAM
The D0 experiment�s data and
job management system software, SAM[17], is an operational
prototype of many of the concepts being developed for Grid computing.
�
The D0 data handling system,
SAM, was built for the �virtual organization�, D0, consisting of 500 physicists
from 72 institutions in 18 countries. Its purpose is to provide a worldwide system of shareable
computing and storage resources
that can be brought to bear on the common
problem of extracting physics results from about a Petabyte of measured
and simulated data. The goal of the system is to provide a large degree of transparency to the user who makes requests for datasets (collections) of relevant data and submits jobs that execute
The data handling and job
control services, typical of a data grid, are provided by a collection of
servers using CORBA communication. The software components are D0-specific
prototypical implementations of some of those identified in Data Grid
Architecture documents.� Some of these
components will be replaced by �standard� Data Grid components emanating from
the various grid research projects, including PPDG. Others will be modified to
conform to Grid protocols and APIs. Additional functional components and
services will be integrated into the SAM system. (This work forms the D0/SAM
component of the Particle Physics Data Grid project.)�
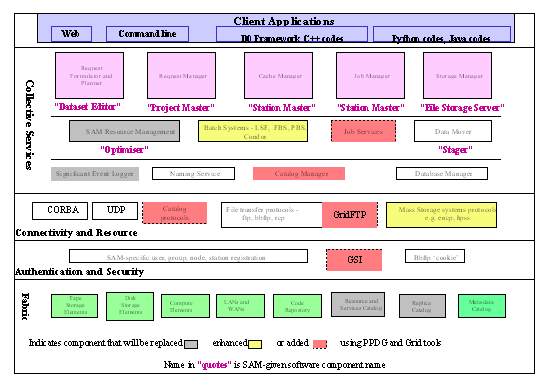
Figure 11 The structure of the D0 experiment's SAM system
7.
Inter-Grid Coordination
The widespread adoption by the HEP community
of Grid technology is a measure of its applicability and suitability for the
computing models adopted and/or planned by HEP experiments. With this adoption
there arose a pressing need for some sort of coordination between all the
parties concerned with developing Grid infrastructure and applications. Without
coordination, there was a real danger that a Grid deployed in one country, or
by one experiment, might not interoperate with its counterpart elsewhere. Hints
of this danger were initially most visible in the area of conflicting
authentication and security certificate granting methods and the emergence of
several incompatible certificate granting authorities. To address and resolve
such issues, to avoid future problems, and to proceed towards a mutual
knowledge of the various Grid efforts underway in the HEP community, several
inter-Grid coordination bodies have been created. These organizations are now
fostering multidisciplinary and global collaboration on Grid research and
development. A few of the coordinating organizations are described below.
7.1
HICB
The DataGrid,
GriPhyN, iVDGL and PPDG, as well as the national European Grid projects in
The consortia
developing Grid systems for current and next generation high energy and nuclear
physics experiments, as well as applications in the earth sciences and biology,
recognized that close collaboration and joint development is necessary in order
to meet their mutual scientific and technical goals. A framework of joint
technical development and coordinated management is therefore required to
ensure that the systems developed will interoperate seamlessly to meet the
needs of the experiments, and that no significant divergences preventing this
interoperation will arise in their architecture or implementation.
To that
effect, it was agreed that their common efforts would be organized in three
major areas:
- An HENP InterGrid Coordination� Board (HICB) for high level coordination
- A Joint Technical Board (JTB)
- Common Projects, and Task Forces to address needs
in specific technical areas
The HICB is
thus concerned with ensuring compatibility and interoperability of Grid tools,
interfaces and APIs, and organizing task forces, reviews and reporting on
specific issues such as networking, architecture, security, and common
projects.
7.2
GLUE
The Grid
Laboratory Uniform Environment� (GLUE[19])
collaboration is sponsored by the HICB, and focuses on interoperability between
the US Physics Grid Projects (iVDGL, GriPhyN and PPDG) and the European physics
grid development projects (EDG, DataTAG etc.). The GLUE management and effort
is provided by the iVDGL and DataTAG projects. The GLUE effort reports to and
obtains guidance and oversight� from the
HICB and Joint Technical Boards described in 7.1. The GLUE collaboration� includes a range of sub-projects to address
various aspects of interoperability:
�
tasks to
define, construct, test and deliver interoperable middleware to and with the
grid projects;
�
tasks to help
experiments with their intercontinental grid deployment and operational issues;
establishment of policies and procedures related to interoperability; etc.
Since the initial proposal for the GLUE
project the LCG Project Execution Board and SC2[20]
have endorsed the effort as bringing benefit to the project goals of deploying
and supporting global production Grids for the LHC experiments.
The GLUE project�s work includes:
a) Definition, assembly and testing of� core common software components of grid
middleware drawn from EU DataGrid, GriPhyN, PPDG, and others, designed to be
part of the base middleware of the grids that will be run by each project. GLUE
will not necessarily assemble a complete system of middleware, but will choose
components to work on that raise particular issues of interoperability. (Other
projects may address some of these issues in parallel before the GLUE effort
does work on them)
b) Ensuring that the EU DataGrid and
GriPhyN/PPDG Grid infrastructure will be able to be configured as a single
interoperable Grid for demonstrations and ultimately application use.
c) Experiments will be invited to join the
collaboration to build and test their applications with the GLUE suite. GLUE
will work with grid projects to encourage experiments to build their grids
using the common grid software components.
7.3
DataTAG
The main objective of the DataTAG (www.datatag.org)
project is to create a large-scale intercontinental Grid testbed involving the
EU DataGrid project, several national projects in
DataTAG aims to
enhance the EU programme of development of Grid enabled technologies through
research and development in the sectors relevant to interoperation of Grid domains
on a global scale. In fact, a main goal is the implementation of an
experimental network infrastructure for a truly high-speed interconnection
between individual Grid domains in
The DataTAG
project is thus creating a large-scale intercontinental Grid testbed that will link the
Grid domains. This testbed is allowing the project to address and solve the
problems encountered in the high performance networking sector, and the
interoperation of middleware services in the context of large scale data
intensive applications.
7.4 Global Grid Forum
The Global
Grid Forum (GGF � http://www.gridforum.org
) is a group of individuals engaged in research, development, deployment, and
support activities related to Grids in general. The GGF is divided into working
groups tasked with investigating a range of research topics related to
distributed systems, best practices for the design and interoperation of
distributed systems, and recommendations regarding the implementation of Grid
software.� Some GGF working groups have
evolved to function as sets of related subgroups, each addressing a particular
topic within the scope of the working group.�
Other GGF working groups have operated with a wider scope, surveying a
broad range of related topics and focusing on long-term research issues.� This situation has resulted in a different
set of objectives, appropriate expectations, and operating styles across the
various GGF working groups.

Figure 12 Global Grid Forum working groups, as defined in 2001.
8. Current
Issues for HEP Grids
This section summarizes a
number of critical issues and approaches that apply to the most data-intensive and/or
extensive Grids, such as those being constructed and used by the major HEP
experiments. While some of these factors appear to be special to HEP now� (in 2002), it is considered likely that the
development of Petabyte-scale managed Grids with high performance for data
access, processing and delivery will have broad application within and beyond
the bounds of scientific research in the next decade.
It should be noted that
several of the Grid projects mentioned above, notably PPDG, iVDGL and DataTAG,
are designed to address the issue of deploying and testing vertically
integrated systems serving the major experiments. These projects are thus
suitable testing grounds for developing the complex, managed Grid systems
described in this section.
8.1 HEP Grids
Versus Classical Grids
The nature of HEP Grids,
involving processing and/or handling of complex Terabyte-to-Petabyte subsamples
drawn from multi-Petabyte data stores, and many thousands of requests per day
posed by individuals, small and large workgroups located around the world,
raises a number of operational issues that do not appear in most of the Grid
systems currently in operation or conceived.
While the ensemble of
computational, data-handling and network resources foreseen is large by present-day
standards, it is going to be limited compared to the potential demands of the
physics user community. Many large tasks will be difficult to service, as they
will require the co-scheduling of storage, computing and networking resources
over hours and possibly days. This raises the prospect of task-redirection,
checkpointing/resumption, and perhaps task re-execution on a substantial scale.
The tradeoff between high levels of utilization and turnaround time for
individual tasks thus will have to be actively pursued, and optimized with new
algorithms adapted to increasingly complex situations, including an expanding
set of failure modes if demands continue to outstrip the resources[21].�
Each physics collaboration,
large as it is, has a well defined management structure with lines of authority
and responsibility[22]. Scheduling of resources
and the relative priority among competing tasks becomes a matter of policy rather than moment-to-moment technical capability alone. The performance
(efficiency of resource use; turnaround time) in completing the assigned range
of tasks, and especially the weekly, monthly and annual partitioning of
resource usage among tasks at different levels of priority must be tracked, and
matched to the policy by steering the
system as a whole. There will also be site-dependent policies on the use of
resources at each facility, negotiated in advance between each site-facility
and the Collaboration and Laboratory managements. These local and regional
policies need to be taken into account in any of the instantaneous decisions
taken as to where a task will run, and in setting its instantaneous priority.
So the net result is that the
system�s assignment of priorities and decisions will be both inherently time-dependent and location-dependent.
The relatively limited
resources (compared to the potential demand) also leads to the potential for
long queues, and to the need for strategic
as well as tactical planning of
resource allocations and task execution. The overall state of the complex system
of site-facilities and networks needs to be monitored in real time, tracked,
and sometimes steered (to some degree). As some tasks or classes of tasks will
take a long time to complete, long decision processes (hours to days) must be
carried out. A strategic view of workload also has to be maintained, in which
even the longest and lowest (initial) priority tasks are completed in a finite
time.
For complex, constrained
distributed systems of this kind, simulation and prototyping has a key role in
the design, trial and development of effective management strategies, and for
constructing and verifying the effectiveness and robustness of the Grid
services themselves (see Section 8.5).
In contrast, most current
Grid implementations and concepts have implicit assumptions of resource-richness. Transactions
(request/handling/delivery of results) are assumed to be relatively short, the
probability of success relatively high, and the failure modes and the remedial
actions required relatively simple. This results in the �classical� Grid (even
if it involves some data) being a relatively simple system with little internal
state, and simple scaling properties. The services to be built to successfully
operate such a system are themselves relatively simple, since difficult
(strategic) decisions in the scheduling and use of resources, and in the
recovery from failure or the redirection of work away from a �hot spot�, rarely
arise.
8.2 Grid
System Architecture: Above (or Within) the Collective Layer
The highest layer below the
Applications layer specified in the current standard Grid architecture[23] is the Collective layer,
that �contains protocols and services (and APIs and SDKs) that are not
associated with any one specific resource but rather are global in nature and
capture interactions across collections of resources. � Collective components �
can implement a wide variety of sharing behaviors without placing new
requirements on the resources being shared�. Examples include workload
management systems and collaboration frameworks, workload management systems,
and so on.�
Although the Collective layer
includes some of the ideas required for effective operation with the
experiments� application software, it is currently only defined at a conceptual
level. Moreover, as discussed in Section 10.2, physicists deal with object collections, rather than with flat files, and the storage, extraction
and delivery of these collections often involves a database management system
(DBMS).� It therefore falls to the
experiments, at least for the short and medium term, to do much of the vertical
integration, and to provide many of the �End-to-end Global Managed Services�
required to meet their needs. It is also important to note that the experiments�
code bases already contain hundreds of thousands to millions of lines of code,
and users� needs are supported by powerful frameworks [[23]]
or �problem solving environments� that assist the user in handling persistency,
in loading libraries and setting loading and application parameters
consistently, in launching jobs for software development and test, etc.
Hence Grid services, to be
effective, must be able to interface effectively to the existing frameworks,
and to generalize their use for work across a heterogeneous ensemble of local,
continental and transoceanic networks.
HEP Grid architecture should
therefore include the following layers, above the Collective layer shown in
Chapter 4[24]
Physics Reconstruction, Simulation and Analysis Code
Layer
Experiments� Software Framework Layer
Modular and Grid-aware: Architecture able to
interact� effectively with the lower
layers (above)
Grid Applications Layer
(Parameters and algorithms that govern system
operations)
Policy and
priority metrics
Workflow
evaluation metrics
Task-site
coupling proximity metrics
Global End-to-End System Services Layer
(Mechanisms and services that govern long-term system
operation)
Monitoring
and Tracking component performance
Workflow
monitoring and evaluation mechanisms
Error
recovery and redirection mechanisms
System
self-monitoring, evaluation and optimization mechanisms
The Global End-to-End System
Services Layer consists of services that monitor and track all the subsystem
components over long periods, monitor and in some cases try to optimize or
improve system performance, as well as resolve problems or inefficiencies
caused by contention for scarce resources. This layer is �self aware� to the
extent that is continually checking how well the resource usage is matched to
the policies, and attempting to steer the system by redirecting tasks and/or
altering priorities as needed, while using adaptive learning methods (such as
the Self-Organizing Neural Net described in Section 8.5) for optimization.�
The Grid Applications Layer refers to the parameters, metrics and in some cases the algorithms used in the End-to-End System Services layer. This allows each experiment to express policies relating to resource usage and other desired system behaviors, and such aspects as how tightly coupled the processing tasks of a given sub-community are to a given geographical region.
��
8.3 Grid
System Software Design and Development Requirements
The issues raised in Section
8.1 lead to a number of general architectural characteristics that are highly
desirable, if not required, for the services composing an open scalable Grid
system of global extent, able to fulfill HEP�s data-intensive needs.
The system has to be dynamic,
with software components designed to cooperate across networks and to
communicate state changes throughout the system, end-to-end, in a short time.
It must be modular and loosely coupled, with resilient autonomous
and/or semi-autonomous service components that will continue to operate, and
take appropriate action (individually and cooperatively) in the case other
components fail or are isolated due to network failures. It must be adaptable
and
heuristic, able to add new services and/or reconfigure itself without
disrupting the overall operation of the system, to deal with a variety of both
normal and abnormal situations (often more complex than point failures) that
are not known a priori in the early
and middle stages of system design and development. It must be designed
to inter-communicate, using standard protocols and de facto mechanisms
where possible, so that it can be easily integrated while supporting a variety
of legacy systems (adopted at some of the main sites for historical reasons or
specific functional reasons). It must support a high degree of parallelism
for ongoing tasks, so that as the system scales the service components are not
overwhelmed by service requests.�
A prototype distributed
services architecture with these characteristics is described in Section 9.
Because of the scale of HEP
experiments, they are usually executed as managed projects with milestones and
deliverables well-specified at each stage. The developing Grid systems
therefore also must serve and support the development of the reconstruction and
simulation software, and as a consequence they must also support the vital
studies of online filtering algorithms, detector performance and the expected
physics discovery potential. These studies begin years in advance of the
start-up of the accelerator and the experiment[25], and continue up to and
into the operations phase. As a consequence, the development philosophy must be
to deploy working vertically integrated systems, that are (to an
increasing degree) production-ready, with increasing functionality at each
development cycle. This development methodology is distinct, and may be at odds
with, a �horizontal� mode of development (depending on the development
schedule) which focuses on basic services in the lower layers of the
architecture and works its way up[26].
In order to mitigate these
differences in development methods, some experiments (e.g. CMS) have adopted a
procedure of �sideways migration�. Home-grown tools (scripts and applications;
sometimes whole working environments) that provide timely and fully functional support
for �productions� of simulated and reconstructed physics events, currently
involving tens of Terabytes produced at 10-20 institutions are progressively
integrated with standard services as they become available and are
production-tested. The drive towards standardization is sometimes spurred on by
the manpower-intensiveness of the home-grown tools and procedures.� An example is the evolution from the MOP to a
more integrated system employing a wide range of basic Grid services.
8.4 HEP
Grids and Networks
As summarized in the
introduction to this chapter, HEP requires high performance networks, with data
volumes for large scale transfers rising from the 100 Gigabyte to the 100
Terabyte range (drawn from 100 Terabyte to 100 Petabyte data stores)� over the next decade. This corresponds to
throughput requirements for data flows across national and international
networks rising from the 100 Mbps range now to the Gbps range within the next
2-3 years, and the 10 Gbps range within 4-6 years. These bandwidth estimates
correspond to static data flows lasting hours, of which only a few could be
supported (presumably with high priority) over the �baseline� networks
currently foreseen.
These requirements make HEP a
driver of network needs, and make it strongly dependent on the support and
rapid advance of the network infrastructures in the US (Internet2 [[24]],
ESNet [[25]]
and the Regional Networks [[26]]),
Europe (GEANT [[27])],
Japan (Super-SINET [[28]]),
and across the Atlantic (StarLight [[29]];
the US-CERN Link Consortium and DataTAG [[30]])
and the Pacific (GTRN [[31]]).
In some cases HEP has become a very active participant in the development and
dissemination of information about state of the art networks. Developments
include bbcp (�BaBar Copy�) [[32]]
and bbftp� (�BaBar ftp�) [[33]],
the Caltech-DataTAG �Grid-TCP� project [[34]]
and the Caltech �Multi-Gbps TCP� project [[35]],� as well as monitoring systems in the Internet
End-to-end Performance Monitoring (IEPM) project at SLAC [[36]].
The development and deployment of standard working methods aimed at high
performance is covered in the Internet2 HENP (High Energy and Nuclear Physics)
Working Group [[37]],
the Internet2 End-to-end Initiative [[38]],
and the ICFA Standing Committee on Inter-Regional Connectivity [[39]].
If one takes into account the
time-dimension, and the fact that a reliable distributed system needs to have
both task queues (including queues for network transfers) of limited length and
a modest number of� pending transactions
at any one time,� then the resulting
bandwidth (and throughput) requirements are substantially higher than the
baseline needs described above. We may assume, for example, that typical
transactions are completed in 10 minutes or less, in order to avoid the
inherently fragile state of the distributed system that would result if
hundreds to thousands of requests were left pending for long periods, and to
avoid the backlog resulting from tens and then hundreds of such
�data-intensive� requests per day. A 100 Gigabyte transaction completed in 10
minutes corresponds to an average throughput of 1.3 Gbps, while a 1 Terabyte
transaction in 10 minutes corresponds to 13 Gbps[27].
In order to meet these needs
in a cost-effective way, in cooperation with the major providers and academic
and research networks, some of HEP sites are pursuing plans to connect to a key
point in their network infrastructures using �dark fiber[28]�. A leading, nearly
complete example is the State of
http://webcc.in2p3.fr ) to CERN in Geneva.
Beyond the simple requirement
of bandwidth, HEP needs networks that interoperate seamlessly across multiple
world regions and administrative domains. Until now the Grid services are
(implicitly) assumed to run across networks that are able to provide
transparent high performance (as above) as well as secure access. The particle
physics-related Grid projects PPDG, GriPhyN/iVDGL, EU DataGrid, DataTAG and
others are taking steps towards these goals[31].
But the complexity of the
networks HEP uses means that a high degree of awareness of the network
properties, loads, and scheduled data flows will be needed to allow the Grid
services to function as planned, and to succeed in scheduling the work
(consisting of hundreds to thousands of tasks in progress at any point in time)
effectively.
Grid and network operations
for HEP will therefore require an Operations Center (or an ensemble of centers)
to gather and propagate information on the system status, problems and
mitigating actions, assist in troubleshooting, and maintain a repository of
guidelines and best practices for Grid use. One example is the iVDGL
8.5
Strategic Resource Planning: the Key Role of Modeling and Simulation
HEP data analysis is and will
remain resource-constrained, and so large production teams, small workgroups
and individuals all will often need to make strategic decisions on where and
how to carry out their work. The decisions will have to take into account their
quotas and levels of priority for running at each site, the likely time-delays
incurred in running at a given site. Grid users will need to be provided with
information (to the degree they are willing to deal with it) on the state of
the various sites and networks, task queues with estimated times, data flows in
progress and planned, problems and estimated time-to-repair if known. They will
need to choose whether to run remotely, using centralized large scale
resources, or regionally or even locally on their group�s servers or desktops,
where they have more control and relatively greater rights to resource usage.
The hope is that eventually
many of these functions will be automated, using adaptive learning algorithms
and intelligent software agents, to allow the physicists to concentrate on
their own work rather than the internal workings of the Grid systems. But in
(at least) the early stages, many of these decisions will have to be manual,
and interactive.
Since the basic strategies
and guidelines for Grid users (and for the operational decisions to be taken by
some of the Grid services in a multi-user environment) have yet to be
developed, it is clear that Modeling and Simulation (M&S) will have a key
role in the successful development of Grids for High Energy Physics. M&S is
generally considered an essential step in the design, development and
deployment of complex distributed systems in a wide range of fields [[40]],
from space missions to networks, from battlefields to agriculture and from the
factory floor to microprocessor design. Yet such simulations, with an
appropriately high degree of abstraction and focusing on the key component and
distributed system behaviors (so that they can scale to very large and complex
systems), have so far not been widely adopted in the HEP community or in the
Grid projects.
One such simulation system
was developed in the MONARC project [[41]]
(http://monarc.web.cern.ch/MONARC/sim_tool/).
This system was applied to regional center operations, to data replication
strategies [[42]],
and to the optimization of job scheduling among several Regional Center sites
using a Self-Organizing Neural Network (SONN) [[43]],
but it has yet to be applied directly to problem of designing and testing of a
wide range of user- and service-strategies for HEP Grids. Such a series of
studies, using this or a similar system, will be needed to (1) develop scalable
Grid services of sufficient robustness, (2) formulate and then validate the
architecture and design of effective Grid and decision-support services, as
well as guidelines to be provided to users, and (3) determine the achievable
level of automation in handling strategic scheduling, job placement, and
resource co-scheduling decisions. Because the MONARC system is based on
process-oriented discrete event simulation, it is well-adapted to real time
operational support for running Grid systems. The system could be applied, for
example, to receive monitoring information within a real operational Grid, and
return evaluations of the estimated time to completion corresponding to different
job placement and scheduling scenarios.
9.� A Distributed Server Architecture for Dynamic
HEP Grid Services
A scalable agent-based
Dynamic Distributed Server Architecture (DDSA), hosting loosely coupled dynamic
services for HEP Grids has been developed at Caltech, that meets the general
criteria outlined in Section 8.3. These systems are able to gather, disseminate
and coordinate configuration, time-dependent state and other information across
the Grid as a whole. As discussed in this section, this architecture, and the
services implemented within it, provide an effective enabling technology for
the construction of workflow- and other forms of global higher level end-to-end
Grid system management and optimization services (along the lines described in Section
8.2).
A prototype distributed
architecture based on JINI [[44]]
has been developed[32], with services written in
Java. This has been applied to the development of a flexible realtime
monitoring system for heterogeneous regional centers [[45]]
(described in the next section), and to the optimization of the
interconnections among the �reflectors� making up Caltech�s Virtual Room
Videoconferencing System (VRVS [[46]])
for worldwide collaboration.
The prototype design is
based on a set of �Station Servers� (generic network server units) dynamically
interconnected (peer-to-peer) to form a distributed framework for hosting
different types of services. The use of JINI distributed system support allows
each Station Server to easily keep a dynamic list of active Station Servers at
any moment in time.
The prototype framework has
been based on JINI because it allows cooperating services and applications to
discover and to access each other seamlessly, to adapt to a dynamic
environment, and to share code and configurations transparently. The system
design avoids single points of failure, allows service replication and
re-activation, and aims to offer reliable support for large scale distributed
applications in real conditions, where individual (or multiple) components may
fail.�
9.1� The Station Server Framework
The Station Server
framework provides support for three types of distributed computing entities:
Dynamic Services are hosted by the framework of networked Station Servers and made
available to interested clients. The framework allows each service to locate
and access information from anywhere in�
the entire system, and to interact with other services. The Station
Server does the service management and facilitates inter-service communication.
Mobile Agents are dynamic autonomous
services (with internal rules governing their behavior) which can move between
Station Servers to perform one or more specified tasks. This transfer is done using
a transaction management service, which provides a two phase commit and
protects the integrity of the operation. Agents may interact synchronously or
asynchronously using the Station Servers� support for �roaming� and a messages
mailbox.
�Smart� Proxies
are flexible services which are deployed to the
interested clients and services and act differently according to the rule base
encountered at the destination, which includes a set of local and remote
parameters.
These
types of components work together and interact by using remote event
subscription/ notification and synchronous and asynchronous message-based
communication. Code mobility is also required to provide this functionality in
a scalable and manageable way.
9.2� Key Distributed System Features of the JINI
Prototype
The purpose of the JINI
architecture is to federate groups of software components, according to
a reliable distributed object model, into an integrated, loosely coupled
dynamic system supporting code mobility. The key service features and
mechanisms of JINI that we use are:
Lookup Discovery
Service: Services are found and resolved by a lookup service.
The lookup service is the central bootstrapping mechanism for the system and
provides the major point of contact between the system and its users
Leasing Mechanism: Access to
many of the services in the JINI system environment is lease based. Each
lease is negotiated between the user of the service and the provider of the
service as part of the service protocol, for a specified time period.
Remote Events: The JINI
architecture supports distributed events. An object may allow other
objects to register interest in events (changes of state) in the object and
receive a notification of the occurrence of such an event. This enables distributed
event-based programs to be written with a variety of reliability and
scalability guarantees.
Transactions Manager: Reliable
distributed object models require transaction support to aid in protecting the
integrity of the resource layer. The specified transactions are inherited from
the JINI programming model and focus on supporting large numbers of
heterogeneous resources, rather than a single large resource (e.g. a database).
This service provides a series of operations, either within a single service or
spanning multiple services, that can be wrapped in one transaction.
The JavaSpaces Service[33]:
This service supports an ensemble of
active programs, distributed over a set of physically dispersed machines. While
each program is able to execute independently of the others, they all
communicate with each other by releasing data (a tuple) into tuple spaces
containing code as well as data. Programs read, write, and take tuples
(entries) from tuple spaces that are of interest to them[34]
The Mailbox Service: This
service can be used to provide asynchronous communications (based on any type
of messages) between distributed services.
9.3� Station Server Operation
The
interconnections among the Station Servers, and the mechanisms for service
registration and notification that keep the Server framework updated, are shown
schematically in Figure 11 below. Each Station Server registers itself to be a
provider of one or more dynamic services with a set of JINI lookup-servers. As
a result it receives the necessary code and parameter data (the yellow dots in
the figure), downloaded from a JavaSpace. At the same time the Station Server
subscribes as a remote listener, to be notified (through remote events) of
state changes in any of the other Station Servers.� This allows each Server to keep a dynamically
updated list of active Station Servers, through the use of a proxy for each of
the other Servers. The JINI lease mechanism is used to inform each unit of
changes that occur in other services (or to alert the Servers of other changes,
as in the case of network problems).�
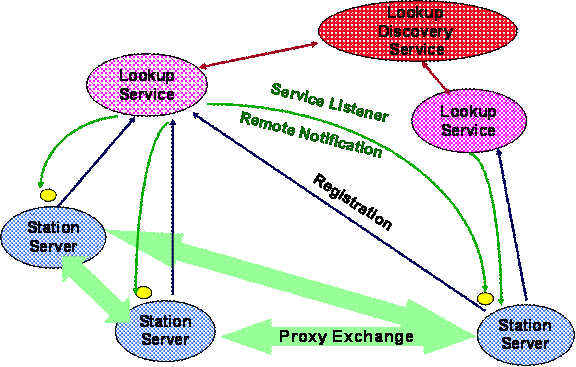
Figure 13 Showing the
interconnections and mechanisms for registration and notification in the DDSA
Station Server framework.
The use of dynamic remote event subscription allows a
service to register to be notified of certain event types, even if there is no
provider to do the notification at registration time. The lookup discovery
service will then notify the Station Servers when a new provider service, or a
new service attribute, becomes available.
In large complex systems such as those foreseen for
LHC, the services[35] will be organized and
clustered according to a flexible, somewhat-hierarchical structure. Higher
level services that include optimization algorithms are used to provide
decision-support, or automated decisions, as discussed in the next sections. As
the information provider-services are distributed, the algorithms used for decisions
also should be distributed: for the sake of efficiency, and to be able to cope
with a wide variety of abnormal conditions (e.g. when one or more network links
are down).
9.4� Possible Application to a Scalable Job
Scheduling Service
As a simple example,
we describe how the distributed Station Server framework may be used for job
scheduling between Regional Centers[36].
Each Center starts a Station Server, and the Server network is created through
the mechanisms described earlier. Each Station Server registers for, and
downloads code and a parameter set for a �Job Scheduling optimization� service.
When a Regional Center (through its Station Server) considers exporting a job
to another site it first sends out a call to (all or a designated subset of) the
other Station Servers for �remote job estimation�, requesting that the time to
complete the job at each designated site be provided by the Station Server
(specifically by a job-execution estimation agent housed by the Server) at that
site. The answers received within a set time window then are used to decide if
and where to export the job for execution.
In order to
determine the optimal site to execute the job, a �thin proxy� is sent to each
remote site. The Station Server there does an evaluation, using the
characteristics of the job, the site configuration parameters, the present load
and other state parameters of the local site. It may also use the historical
�trajectory� of resource usage and other state variables, along with external
information (such as the resource usage policies and priorities). The
evaluation procedure may also use adaptive learning algorithms, such as a
Self-Organizing Neural Network (SONN; introduced in Section 8.5).
Having the
evaluation done in parallel by each of the Station Servers has a performance
advantage. The Server at each site also may have direct access to local
monitoring systems that keep track of the available resources and queues, as
well as access to local policy rules and possibly to more complex local systems
managing job scheduling, based on detailed knowledge of the characteristics and
history of each job.
As the remote
evaluations are completed, the results are returned to the original site that
sent out the request. These results may be as simple as the time to complete
the job, or as complex as a set of functions that give the �cost to complete�
expressed in terms of the priority for the job (and the implied level of
resource usage). The originating site then makes the final decision based on
the information received, as well as its own �global� evaluation algorithms
(such as another SONN).
Once the
decision on the (remote) site for execution has been made, the description
object for the job is transferred to the remote site using a Transaction
Manager and a progress job handle is returned. This provides the mechanisms for
the originating site to control the job execution at a remote site and to
monitor its progress (through the notification mechanism and/or explicit
requests for information). A schematic view of a prototypical Job Scheduling
Service using the DDSA is illustrated in Figure 14 below.��
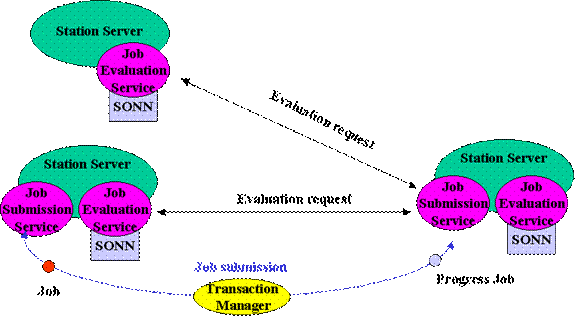
Figure 14 Illustration of a basic job
scheduling system based on the DDSA architecture.
9.5 An Agent-Based Monitoring System Using
the DDSA
A prototype
agent-based monitoring system MONALISA[37]
has been built using the DDSA architecture, based on JINI as well as WSDL and
SOAP technologies. The system has been deployed and in its initial implementation
is currently monitoring the prototype Regional Centers at Caltech, CERN,
The goal of
MONALISA is to gather and disseminate real-time and historical monitoring
information on the heterogeneous
Some of
MONALISA�s main features are:
- A mechanism to dynamically discover all the �Farm
Units� used by a community
- Remote event notification for changes in any
component in the system
- A lease mechanism for each registered unit
- The ability to change the farm/network elements,
and the specific parameters being monitored, dynamically, on the fly,
without disturbing system operations
- The ability to monitor any element through SNMP,
and to drill down to get detailed information on a single node,� storage or other element
- Real-time tracking of the network throughput and
traffic on each link
- Active filters (applied through code in the
mobile agents in JINI) to process the data and to provide
dedicated/customized information to a number of other services or clients
- Routing of selected (filtered) real-time and/or
historical information to each subscribed listener, through a set of
predicates with optional time-limits
- Flexible interface to any database supporting JDBC
[[49]]
- When using self-describing WSDL [[50]]
Web services, being able to discover such services via UDDI [[51]],
and to automatically generate dynamic proxies to access the available
information from each discovered service in a flexible way
9.5.1
Data Collection and Processing in MONALISA
The data
collection in MONALISA is based on dynamically loadable �Monitoring Modules� and a set of �Farm Monitors�, as illustrated in Figure
15.
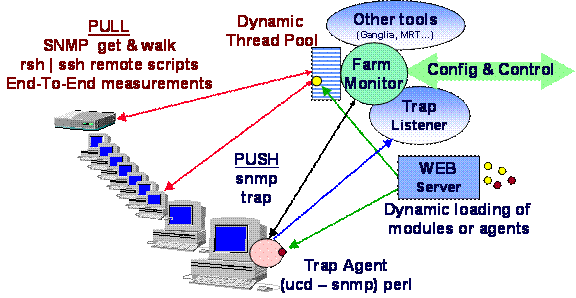
Figure 15 Data collection and processing in
MONALISA. Farm Monitors use dynamically loadable Monitoring Modules to pull
or push information from computational nodes or other elements at one or
more sites.
Each Farm Monitor unit is responsible for
the configuration and the monitoring of one or several farms.� It can dynamically load any monitoring
modules from a (set of) Web servers (with http), or a distributed file system.
The Farm Monitor then uses the modules to perform monitoring tasks on each
node, based on the configuration it receives from a Regional Center Monitor unit (not shown) that controls a set of
Farm Monitors. The multithreaded engine controlling a dynamic pool of threads
shown in Figure 13 is used to run the specified monitoring modules concurrently
on each node, while limiting the additional load on the system being monitored.
Dedicated modules adapted to use parameters collected by other monitoring tools
(e.g. Ganglia, MRTG) are controlled by the same engine. The use of
multi-threading to control the execution of the modules also provides robust
operation, since a monitoring task that fails or hangs (due to I/O errors for
example) will not disrupt or delay the execution of the other modules. A
dedicated control thread is used to stop any threads that encounter errors, and
to reschedule the tasks associated with this thread if they have not already
been successfully completed. A priority queue is used to handle the monitoring
tasks that need to be executed periodically.
A Monitoring Module is a dynamically
loadable unit which executes a procedure (runs a script or a program, or makes
an SNMP request) to monitor a set of values, and to correctly parse the results
before reporting them back to the Farm Monitor. Each Monitoring Module must implement
a method that provides the names (identifiers) for the parameters it monitors.
Monitoring Modules can be used to pull data once, or with a given frequency.
They may also push and install code at a monitored node (the dark dots at the
right of the figure), after which they will autonomously push back the
monitoring results (using SNMP, UDP or TCP) periodically back to the Farm
Monitoring module.�
Dynamically
loading the Monitoring Modules from a relatively small set of sites when they
are needed, makes it much easier to keep large monitoring systems updated and
able to provide the latest functionality in a timely manner.
�
9.5.2
Farm Monitor Unit Operation and Data Handling
The operation
of the Farm Monitor unit and the flow of monitored data are illustrated in
Figure
16.� Each Farm
Monitor registers as a JINI service and /or a WSDL service. Clients or other
services get the needed system configuration information, and are notified
automatically when a change in this information occurs. Clients subscribe as
listeners to receive the values of monitored parameters (once or periodically;
starting now or in the future; for real-time and/or historical data).� The monitoring predicates are based on
regular expressions for string selection, including configuration parameters
(e.g. system names and parameters), conditions for returning values and time
limits specifying when to start and stop monitoring.� In addition predicates may perform elementary
functions such as MIN, MAX, average, integral, etc. The predicate-matching and
the client notification is done in independent threads (one per client IP
address) under the control of the DataCache Service unit (shown in the figure).
The measured
values of monitored parameters are currently stored in a relational database
using JDBC (such as InstantDB,�
MySQL,� Postgres, Oracle, etc.) in
order to maintain an historical record of the data. The predicates used to
retrieve historical data are translated into SQL queries, which are then used
to select the desired data from the database and deliver it to the client who
made the query. The thread associated with the query remains active, and as
soon as it receives additional data satisfying the predicates, it sends that
data on (as an update) to the client.
The system
also allows one to add additional data writers and to provide the collected
values to other programs or tools, through the use of user-defined dynamically
loadable modules (shown at the bottom of the figure).
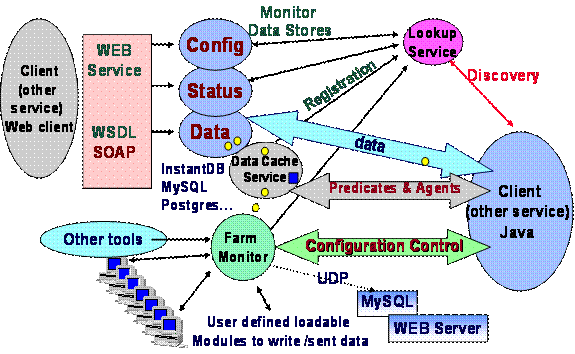 �
�
�
�
����������������������������������������������������������������������������������������������
Figure 16 Data flow and operation of the
Farm Monitor unit in MONALISA.
More complex data
processing can be handled by Filter Agents (represented as the blue square in Figure 16). These agents are "active objects" which
may be deployed by a client or another service to perform a dedicated task
using the data collected by a Farm Monitor unit. Each agent uses a predicate to
filter the data it receives, and it may send the computed values back to a set
of registered Farm Monitor units.� As an
example, a maximum flow path algorithm[38]
can be performed by such an agent. Agents may perform such tasks without being
deployed to a certain service, but in this case the Data Cache Service unit
needs to send all the requested values to the remote sites where the units that
subscribed to receive these values are located.
�
The Farm
Monitor unit is designed as a service system able to accept values,
predicate-based requests from clients, and Agent Filters, and to manage all of
them asynchronously. The Farm Monitor is then "published" as a JINI
service and a WSDL service at the same time.
9.5.3
MONALISA Output Example
An example of
the monitoring system�s output is shown in Figure
17. In the upper left there is a real-time plot of the
farms being monitored, indicating their loads (Green = low load; Pink = high
load; Red = unresponsive node) and the bottleneck bandwidths (monitored using
Various kinds
of information can be displayed for each site-component or set of components.
In this example, the bottom left plot shows the CPU load as a function of time
on a single selected node at the CERN site, with three curves showing the
time-averages over the last N minutes
(N = 5, 10, 15) using a sliding time-window. The bottom center plot shows the
current CPU load� for selected nodes in a
sub-cluster of 50 nodes, averaged over the same three time-intervals.� The bottom right plot shows the current bottleneck
bandwidth between CERN and each of the other four sites being monitored.
The monitored
values in the plots are updated frequently in real time, as new measurements
are performed and the results come in.
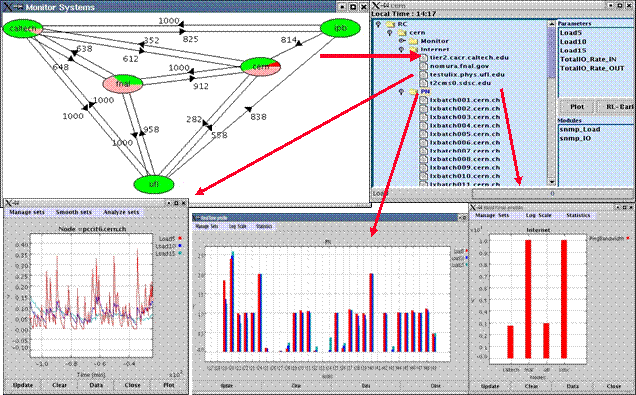
Figure 17 Example output (screenshot) from
the MONALISA monitoring system, running on farms at (left to right in the
upper left plot) Caltech, Fermilab ,
Florida Politechnica University Bucharest
|
Figure 17 Example output (screenshot) from
the MONALISA monitoring system, running on farms at (left to right in the
upper left plot) Caltech, |
10. The Grid-Enabled Analysis Environment
Until now, the
Grid architecture being developed by the LHC experiments has focused on sets of
files and on the relatively well-ordered large-scale production environment.
Considerable effort is already being devoted to the preparation of Grid
middleware and services (this work being done largely in the context of the
PPDG, GriPhyN, EU DataGrid and LHC Computing Grid projects already described).
However, in early 2002, the problem of how processed object collections,
processing and data handling resources, and ultimately physics results may be
obtained efficiently by global physics collaborations had yet to be tackled
head on. Developing Grid-based tools to aid in solving this problem over the
next few years, and hence beginning to understand new concepts and the
foundations of the analysis solution, was deemed to be essential if the LHC
experiments were to be ready for the start of LHC running.
We have
described how the prevailing view of the LHC Experiments� computing and
software models is well developed, being based on the use of the Grid to
leverage and exploit a set of computing resources that are distributed around
the globe at the collaborating institutes. Analysis environment prototypes
based on modern software tools, chosen from both inside and outside High Energy
Physics have been developed. These tools have been aimed at providing an
excellent capability to perform all the standard data analysis tasks, and
assumed full access to the data, very significant local computing resources,
and a full local installation of the experiment�s software. These prototypes
have been, and continue to be very successful; a large number of physicists use
them to produce detailed physics simulations of the detector, and attempt to
analyze large quantities of simulated data.
However, with
the advent of Grid computing, the size of the collaborations, and the expected
scarcity of resources, there is a pressing need for software systems that
manage resources, reduce duplication of effort, and aid physicists who need
data, computing resources, and software installations, but who cannot have all
they require locally installed.
������������������ ��
10.1
Requirements: Analysis vs. Production
The
development of an interactive Grid-enabled Analysis Environment
(GAE) for physicists working on the LHC Experiments was thus proposed in 2002.
In contrast to the production environment, which is typically operated by a
small number of physicists dedicated to the task, the analysis environment
needed to be portable, lightweight (yet highly functional), and make use of
existing and future experimental analysis tools as plug-in components. It
needed to consist of tools and utilities that exposed the Grid system
functions, parameters and behavior at selectable levels of detail and
complexity. It is believed that only by exposing this complexity can an
intelligent user learn what is reasonable (and efficient for getting work done)
in the highly constrained global system foreseen. The use of Web Services to
expose the Grid in this way, will allow the physicist to interactively request
a collection of analysis objects, to monitor the process of preparation and
production of the collection and to provide �hints� or control parameters for
the individual processes. The Grid enabled analysis environment will provide
various types of feedback to the physicist, such as time to completion of a
task, evaluation of the task complexity, diagnostics generated at the different
stages of processing, real-time maps of the global system, and so on.
10.2
Access to Object Collections
A key challenge in the development of a
Grid Enabled Analysis Environment for HENP is to develop suitable services for object
collection identification, creation and selection. In
order to complete an analysis a physicist needs access to data collections.
Data structures and collections not available locally need to be identified.
Those collections identified as remote or non-existent need to be produced and
transferred to an accessible location. Collections that already exist need to
be obtained using an optimized strategy.��
Identified computing and storage resources need to be matched with the
desired data collections using available network resources.
It is intended to use Web-based
portals and Web Services to achieve this functionality, with features that
include collection browsing within the Grid, enhanced job submission and
interactive response times. Scheduling of object collection analysis
activities, to make the most efficient use of resources, is especially challenging
given the current ad hoc systems. Without Grid-integrated tools,
scheduling cannot advance beyond the most basic scenarios (involving local
resources or resources at one remote site).�
Accordingly, a set of tools to support the creation of more complex and
efficient schedules and resource allocation plans is required.� In the long term, the Grid projects intend to
deliver advanced schedulers which can efficiently map many jobs to distributed
resources. Currently this work is in the early research phase, and the first
tools will focus on the comparatively simpler scheduling of large batch
production jobs.� Experience with using
new scheduling tools should also help the ongoing development efforts for
automatic schedulers.
10.3
Components of the GAE
The GAE should consist of tools
and utilities that expose the Grid system functions, parameters and behavior at
selectable levels of detail and complexity. At the request submission level, an
end-user might interact with the Grid to request a collection of analysis
objects. At the progress monitoring level, an end-user would monitor the
process of preparing and producing this collection. Finally at the control
level, the end-user would provide �hints� or control parameters to the Grid for
the production process itself. Within this interaction framework, the Grid
would provide feedback on whether the request is �reasonable�, for example by
estimating the time to complete a given task, showing the ongoing progress
towards completion, and displaying key diagnostic information as required. This
complexity must be visible to the user so that can s/he can learn what is
reasonable in the highly constrained global Grid system.
By using Web Services, it is
ensured that the GAE is comparatively easy to deploy, regardless of the
platform used by the end-user. It is important to preserve the full
functionality of the GAE regardless of the end-user�s platform. The desire is
for OS-neutrality, so allowing access from as wide a range of devices as
possible. The GAE Web Services are integrated with other services such as
agent-based monitoring services (as discussed in Section 9) and the Virtual
Data Catalog Service.
10.4
Clarens
At Caltech, we
have been developing a key component of the GAE toolset. The Clarens component
software aims to build a wide-area network client/server system for remote
access to a variety of data and analysis services. It does this by facilitating
the integration of several existing HEP analysis and production tools, in a
plug-in architecture which features an extremely small client footprint, and a
modular server-side implementation.
One example of
a Clarens service provides analysis of events stored in a CMS Objectivity
database. This service has been extended to support analysis of events stored
in RDBMS�s
such as Oracle and SQLServer. Another Clarens service provides remote access to
Globus functionality for non-Globus clients, and includes file transfer,
replica catalog access and job scheduling.
Communication
between the Clarens client and server is conducted via the lightweight
XML-RPC[39]
remote procedure call mechanism. This was chosen both for its simplicity, good
degree of standardization, and wide support by almost all programming
languages. Communication using SOAP is also available.
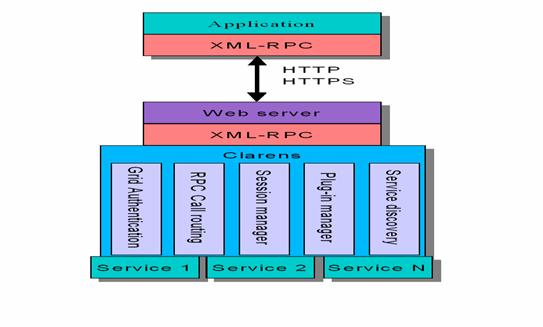
Figure 18 The architecture of the Clarens
system
The modular
design of the Clarens server allows functionality to be added to a running
server without taking it off-line by way of drop-in components written in
Python and/or C++. The multi-process model of the underlying Web server
(Apache) allows Clarens to handle large numbers of clients as well as
long-running client requests. The server processes are protected from other
faulty or malicious requests made by other clients since each process runs in
its own address space.
Several
Clarens features are of particular note
�
The Python
command line interface
�
A C++ command
line client as an extension of the ROOT analysis environment
�
A Python GUI
client in the SciGraphica analysis environment
�
The
transparent GUI and command-line access to remote ROOT files, via a download
service.
10.6 CAIGEE
The CAIGEE
�CMS Analysis � an Interactive Grid Enabled Environment� proposal to NSF's ITR
program[40],
directly addresses the development of a Grid Enabled Analysis Environment. The
proposal describes the development of an interactive Grid-enabled analysis
environment for physicists working on the CMS experiment. The environment will
be lightweight yet highly functional, and make use of existing and future CMS
analysis tools as plug-in components.
The
CAIGEE architecture is based on a traditional client-server scheme, with one or
more inter-communicating servers. A small set of clients is logically
associated with each server, the association being based primarily on
geographic location. The architecture is �tiered�, in the sense that a server
can delegate the execution of one or more of its advertised services to another
server in the Grid, which logically would be at the same or a higher level in
the Tiered hierarchy. In this way, a client request can be brokered to a server
that is better equipped to deal with it than the client�s local server, if
necessary. In practice CAIGEE will initially deploy Web Services running on
Tier2 regional centers at several US CMS institutions. Each of these servers
will be the first point of interaction with the �Front End� clients (local
physicist end users) at US CMS sites.
The
servers will offer a set of Web-based services. This architecture allows the
dynamic addition of, or improvement to, services. Also, software clients will
always be able to correctly use the services they are configured for. This is a
very important feature of CAIGEE from a usability standpoint; it can be
contrasted with static protocols between partner software clients, which would
make any update or improvement in a large distributed system hard or
impossible.
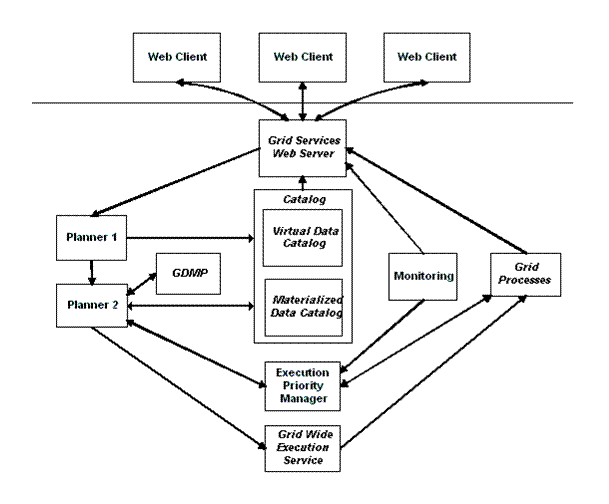
Figure 19 The CAIGEE architecture for a
Grid-enabled HEP analysis environment. The use of Web Services with thin
clients makes the architecture amenable to deployment on a wide range of client
devices.
Grid-based
data analysis requires information and coordination of hundreds to thousands of
computers at each of several Grid locations.�
Any of these computers may be offline for maintenance or repairs.� There may also be differences in the
computational, storage and memory capabilities of each computer in the
Grid.� At any point in time, the Grid may
be performing analysis activities for tens to hundreds of users while
simultaneously doing production runs, all with differing priorities.� If a production run is proceeding at high
priority, there may not be enough CPUs available for the user�s data analysis
activities at a certain location.�
Due to
these complexities, CAIGEE will have facilities that allow the user to pose
�what if� scenarios which will guide the user in his/her use of the Grid. An
example is the estimation of the time to complete the user�s analysis task at
each Grid location. CAIGEE monitoring widgets, with selectable levels of
detail, will give the user a �bird�s eye view� of the global Grid system, and
show the salient features of the prevailing resources in use and scheduled for the
future. CAIGEE will also be interfaced to the MONALISA monitoring system
(described in Section 9.5) for more sophisticated decisions, and
decision-support.
11.
Conclusion: Relevance of Meeting These Challenges for Future Networks and
Society
The HEP (or HENP, for high
energy and nuclear physics) problems are the most data-intensive known.
Hundreds to thousands of scientist-developers around the world continually
develop
software to better select
candidate physics signals, better calibrate the detector and better reconstruct
the quantities of interest (energies and decay vertices of particles such as
electrons, photons and muons, as well as jets of particles from quarks and
gluons). The globally distributed
ensemble of facilities, while
large by any standard, is less than the physicists require to do their work in
an unbridled way. There is thus a need, and a drive to solve the problem of
managing global resources in an optimal way, in order to maximize the potential
of the major experiments for breakthrough discoveries.
In order to meet these
technical goals, priorities have to be set, the system has to managed
and monitored globally
end-to-end, and a new mode of "human-Grid" interactions has to be
developed and deployed so that the physicists, as well as the Grid system
itself, can learn to operate optimally to maximize the workflow through the
system. Developing an effective set of tradeoffs between high levels of
resource utilization, rapid turnaround time, and matching resource usage
profiles to the policy of each scientific collaboration over the long term
presents new challenges (new in scale and complexity) for distributed systems.
A new scalable Grid
agent-based monitoring architecture, a Grid-enabled Data Analysis Environment,
and new optimization algorithms coupled to Grid simulations are all under
development in the HEP community.
Successful construction of
network and Grid systems able to serve the global HEP and other scientific
communities with data-intensive needs could have wide-ranging effects: on
research, industrial and commercial operations. The key is intelligent,
resilient, self-aware, and self-forming systems able to support a large volume
of robust Terabyte and larger transactions, able to adapt to a changing
workload, and capable of matching the use of distributed resources to policies.
These systems could provide a strong foundation for managing the large-scale
data-intensive operations processes of the largest research organizations, as
well as the distributed business processes of multinational corporations in the
future.�
It is also conceivable that
the development of the new-generation of systems of this kind could lead to new
modes of interaction between people and �persistent information� in their daily
lives. Learning to provide and efficiently manage and absorb this information
in a persistent, collaborative environment could have a profound
transformational effect on society.
Acknowledgements
A great number of people
contributed to the work and ideas presented in this chapter. Prominent among
these are Richard Mount (SLAC), Paul Messina (Caltech), Laura Perini
(INFN/Milan), Paolo Capiluppi (INFN/Bologna), Krzsystof Sliwa (Tufts), Luciano
Barone (INFN/Bologna), Paul Avery (Florida), Miron Livny (Wisconsin), Ian
Foster (Argonne and Chicago), Carl Kesselman (USC/ISI), Olivier Martin
(CERN/IT), Larry Price (Argonne), Ruth Pordes (Fermilab), Lothar Bauerdick
(Fermilab), Vicky White (DOE), Alex Szalay (Johns Hopkins), Tom de Fanti (UIC),
Fabrizio Gagliardi (CERN/IT), Rob Gardner (Chicago), Les Robertson (CERN/IT),
Vincenzo Innocente (CERN/CMS), David Stickland (Princeton), Lucas Taylor
(Northeastern), and the members of our Caltech team working on Grids and
related issues: Eric Aslakson, Philippe Galvez, Koen Holtman, Saima Iqbal,
Iosif Legrand,� Sylvain Ravot, Suresh
Singh, Edwin Soedarmadji, and Conrad Steenberg. This work has been supported in
part by DOE Grants DE-FG03-92-ER40701 and DE-FC03-99ER25410 and by NSF Grants
8002-48195, PHY-0122557 and ACI-96-19020.
�