Folios Similarities
Something Knox said recently made me wonder how the vocabulary of the VMs
folios changes throughout the manuscript.
I made some counts and filled them into an Excel
spreadsheet. I defined the Similarity between folio i and j to be computed
as follows:
1) List all unique words in Folio i = Ni
2) List all unique words in Folio j = Nj
3) List all unique words appearing in both Folio i and Folio j =
Mij
Then compute Similarity = Mij / (Ni + Nj - Mij)
(If Folio i contains exactly the same words as Folio j then S = 1,
and if it contains no words in common with Folio j then S = 0)
You can see a visual pattern of of the Similarity distribution here:

(I have a feeling I've seen something similar to this for the Voynich
before ... but can't find it now - can someone help? -
see References below!)
This contour plot is symmetric about a line running diagonally from
the left hand bottom corner to the top right hand corner, corresponding
to i=j (for which I set the values to 0 for easier viewing).
The rectangular red region around folios 140 to 165 corresponds to
strong similarity in the VMs folios f75r to f84v - the Biological Folios.
These pages all typically share up to 50% of the same words.
What I found surprising is the generally low level of shared vocabulary between
the folios: typically only a few of the words used on one folio are used
on the next - but see below.
The spreadsheet answers questions like "Which folio is most similar to folio
f1v?" ... the answer being f24r by this metric.
Clustering
Using the Similarity number as a connection strength
between each pair of folios, we can generate a cluster map that arranges the
folios so that similar folios appear together. I used the freely available
software called LinLogLayout
to do this. Here are the results:
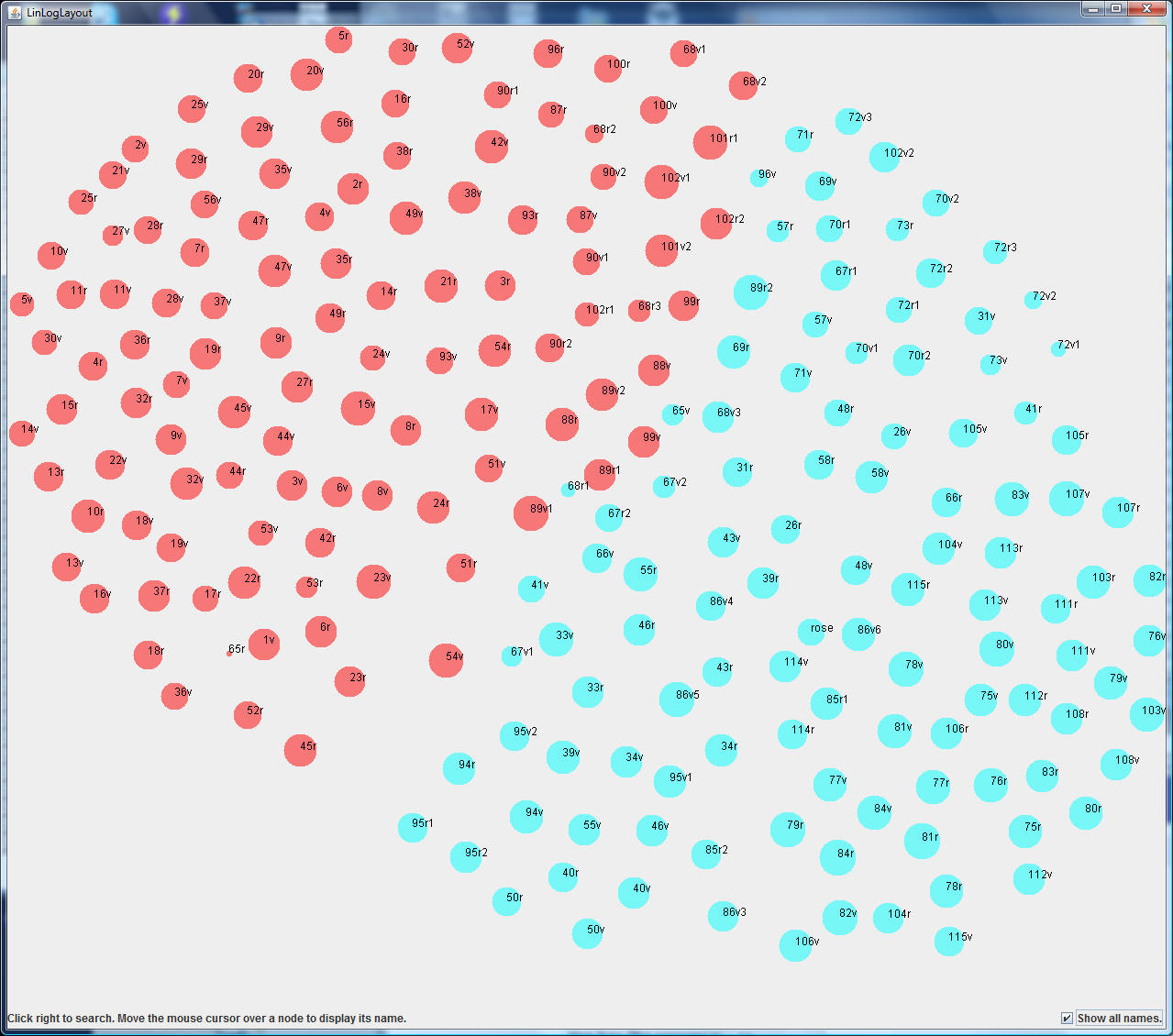
The algorithm has split the folios into two clusters,
shown as red and blue circles. Interestingly, the red circles generally match
Currier Hand 1 and the blue match Currier Hand 2. For some folios near the
interface, e.g. f68r1, the Currier Hand is "unknown" (according to
http://voynich.freie-literatur.de/index.php?show=page&id=f68r1) ...
indicating uncertainty in the attribution, consistent with the folio's position
on the cluster map.
For folio f103v, at the far right edge of the blue
cluster, the Currier Hand is "X".
Comparison with a Latin Text
Here I took the Latin
Herb Garden and split it into 20 folios corresponding to each of the herbs
described. Then I ran the same code against it to generate the similarities
between each folio, and made an Excel
spreadsheet.. The corresponding contour plot is shown below, with the same
colour scale as the one for the Voynich above.

As you can see, the typical value of "Similarity" between
folios is around 0.02 or so ... much *lower* than for the Voynich. The
conclusion is that the Voynich folios are much more alike than this Latin text,
and the Biological Folios in particular are quite unusually similar.
References
This is very similar work to that done by Rene in 1997:
http://www.voynich.nu/extra/lang.html although his word counting rules are
different (I only count unique words).