Table
of Contents
1. Project Description...........................................................................
1.1 Introduction.................................................................................
1.2. Our Main
Objective: To manage and analyze Terabytes of Data....................
1.2.1. Advanced Data
Organization and Management...................................
1.2.2. Distributed
Architectures............................................................
1.2.3. The Relevant
Data Sets � Data Challenges.........................................
1.3. Expertise,
Activities and Achievements of our Collaboration.......................
1.4. Common Challenges
in Computing for Astronomy and Particle Physics...........
1.4.1. The Commonality
of our Approach...............................................
1.4.2. Analysis of
Typical and Enhanced Queries.......................................
1.4.3. Building
Scalable Server Architectures...........................................
1.4.4. Prototype
Agent-based Query system............................................
1.4.5. Test Bed System
Description......................................................
1.5. Planned Outcomes
of the Research...................................................
Advanced Data
Structures:.................................................................
Prototyping Distributed
Systems:.........................................................
Deliverables:................................................................................
2. Appropriateness for
KDI & Roles of Project Personnel..................................
3. Results from Prior
NSF Support.............................................................
Results from Prior NSF
Support by Alexander Szalay......................................
Results from Prior NSF
Support by Michael T. Goodrich.................................
4. Dissemination of
Results and Institutional Commitment.................................
5. Performance Goals,
Milestones.............................................................
Year 1:.......................................................................................
Year 2:.......................................................................................
Year 3:.......................................................................................
6. Management Plan.............................................................................
7. Letters of
Cooperation/Commitment.....................................................
1. Project Description
1.1 Introduction
���� Information technology has made
great changes during our lives, but these changes are trivial compared to what
we expect in the future.� Current science
information systems are similar to those library systems where the card
catalogs have been automated, but where one still uses the only copy of the
information, the book, in which information is sequentially organized. Compare
this to the �anarchy� of the Web, where a page from each of many books can be
easily (but not necessarily quickly) accessed.
���� Our ability to analyze scientific data has not kept up with its increased flow; our traditional approach of copying data subsets across the Internet, storing them locally, and processing them with home-brewed tools has reached its limits. Something drastically different is required. In this proposal we outline our team's approach to the needed practical advances in data analysis and management. Many ideas on managing such large and complex data sets have been extensively discussed in computer science. However, relatively few of those have been implemented in practice, mainly due to the unavailability of real datasets of the required size. With the recent explosion in scientific data acquisition capabilities, we can now collect huge amounts of raw data: there is an urgent need to apply these ideas to those data sets.
���� A data avalanche is brewing in astronomy with Terabyte catalogs, each covering separate wavebands from X-rays to optical, infrared to radio frequencies. The ability to mine data rapidly, and the use of smart query engines, will be a fundamental part of daily research and education in general in the 21st century. In particle physics the amount of data is even more overwhelming than in astronomy. The raw electronic data in the CERN CMS detector needs to be reduced by a factor of more than 107, but will still amount to over a Petabyte of data per year for scientific analysis! The task of finding rare events resulting from the decays of massive new particles in the dominating background is even more formidable. Particle physicists have been at the vanguard of data-handling technology, beginning in the 1940's with eye scanning of bubble-chamber photographs and emulsions, through decades of electronic data acquisition systems employing real-time pattern recognition, filtering and formatting, and continuing on to the Petabyte archives generated by modern experiments. In the slightly farther future, CMS and other experiments now being built to run at CERN�s Large Hadron Collider expect to accumulate of order of 100 Petabytes within the next decade. These trends are becoming apparent in many other sciences as well.
���� The need to access the data in a variety of ways requires it to be organized in a hierarchy and analyzed in multiple dimensions, tuned to the details of a given discipline. But the general principles are applicable to all fields. To optimize for speed and flexibility we must compromise between fully ordered (sequential) organization, and totally �anarchic�, random arrangements. To quickly access information from each of many �pages� of data, the pages must be arranged in a multidimensional mode in a neighborly fashion, with the information on each page stored judiciously in local clusters. These clusters themselves form a hierarchy of further clusters. Our proposed research will experiment with such hierarchical arrangements on real data sets.
���� Our team represents a true collaboration based on common goals. The collaboration is driven by a real need that we all face in the design and implementation of next generation information systems for the physical sciences. There is a natural cohesion in our goals: we are all flooded with large amounts of complex data, we all share a common vision on how to organize the data, we all use Objectivity/DB as our basic database, and we are all part of the VBNS/I2 high-speed networking research community. At the same time, we have recognized each other's� complementary expertise from our ongoing work in our respective fields. We believe that our team has the data, the expertise, the interest and the motivation to create genuine breakthroughs in this area.
�1.2. Our Main
Objective: To manage and analyze Terabytes of Data
���� Current brute force approaches to data
access will neither scale to hundreds of Terabytes, nor to the multi-Petabyte
range needed within the next few years. Hardware advances alone cannot keep up
with the complexity and scale of the tasks we will describe [Szalay99b]. High
level and semi-automated data management is essential. The components of a
successful large-scale problem-solving environment are:
(1) Advanced data organization and management,
(2) Distributed architecture,
(3) Analysis and knowledge discovery tools,
(4) Visualization of Data.
In this proposal we focus on (1) and (2) in order to build the foundations of efficient data access.
1.2.1. Advanced Data Organization and Management
���� Our over-riding goal is to find fast space- and time-efficient structures for storing large scientific data sets. Though we focus on particular scientific applications, we are confident that our techniques will be applicable to a broad range of data organizational applications. The data organization must support repeated and concurrent complex queries. Moreover, the organization must efficiently use memory, disk, tape, local and wide area networks.� It must economize on storage capacity and network bandwidth. As data sets become bigger, database and indexing schemes have to replace traditional �flat� files. On still larger scales, a unified database will need to be replaced by a loosely coupled and carefully managed, networked database federation. Part of good data organization is to carefully design the proper indexing schemes [Szalay99b, Holtman98a,b]. Data mining techniques can be viewed as �flexible indexing� schemes, permitting the user to specify a target set, hence limiting unnecessary data movement.
���� It would be wonderful if we could use an off-the-shelf SQL, Object Relational (OR), or Object Oriented (OO) database system for our tasks, but we are not optimistic that this will work.� As already explained, we believe that the quantity and the nature of our data require novel spatial indices and novel operators. They also require a dataflow architecture that can execute queries concurrently using multiple processors and disks. As we understand it, current SQL systems provide few of these features. Perhaps, by the end of this project, some commercial SQL system will provide all these features; we hope to work with Database Management System (DBMS) vendors towards this goal, experiment with such systems and with different Object Database Management System (ODBMS) implementations.
���� The large-scale particle physics and astronomy data sets consist primarily of vectors of numeric data fields, maps, time-series sensor logs and images: the vast majority of the data is essentially geometric.� The key to the success of the archive depends on capturing the spatial nature of this large-scale scientific data.
Advanced Data
Structures� � Geometric Organization of
Data
���� Searching for special categories of objects involves defining
complex domains (classifications) in this N-dimensional space, corresponding to
decision surfaces. A typical search in these multi-Terabyte, and future
Petabyte, archives evaluates a complex predicate in k-dimensional space, with
the added difficulty that constraints are not necessarily parallel to the axes.
This means that the traditional 1D indexing techniques, well established with
relational databases, will not work, since one cannot build an index on all
conceivable linear combinations of attributes. On the other hand, one can use
the fact that the data are geometric and every object is a point in this
k-dimensional space. One can quantize the data into containers. Each container
has objects of similar properties, e.g. colors, from the same region of the
sky. If the containers are stored as clusters in the low-level storage, the
cache efficiency in the retrieval will be very high. If an object satisfies our
query, it is likely that some of its �friends� will as well. These containers
represent a coarse-grained density map of the data. They enable us to build an
index tree that tells us whether containers are fully inside, outside or
bisected by our query. Only the last category is searched, as the other two are
wholly accepted or rejected. A prediction of the output data volume and search
time can be computed from the intersection volume. We would like to explore
several ideas in detail in our research program:
Hierarchical partitions and geometric hashing. A fundamental advance in geometric data organization is the concept of hierarchical partitions using recursive splits of cells [AGM97, Samet 1990a,b,AND98] into BSP-trees [Goo97,Goo97p], kd-trees [Bentley80], octrees, and hierarchical cutting trees. These data structures are clearly effective in moderate-dimensional Euclidean spaces [CGR95], yet are not fully deployed even in those applications. We are interested in generalizations to non-Euclidean spaces, such as those defined on a sphere. Partition structures are not as efficient in very high-dimensional spaces if arbitrary search queries are allowed. For these spaces, we are exploring the use of novel geometric hashing strategies that bring the effective dimension of a data set into the realm where hierarchical partitioning schemes are effective [GoR97,GoR98]. A variant of kd-trees is at the heart of the current testbed version of the SDSS archive.
Adaptive data structures. Most modern databases provide a static organizational structure for the data they contain. Another aspect of the paradigm shift is to design databases that can reorganize themselves based on the queries they contain. Even if the data itself do not change, we should allow for the database to reorganize itself based on the spatial and temporal distribution of queries. A sequence of multiple queries often exhibits spatial coherence � many queries are concentrated on similar geometric locations � or temporal coherence, where recent queries are likely to be similar. The cache memory in every modern computer is an effective exploitation of such coherence in program execution. For the largest data sets organized as networked database federations, these concepts must be generalized to take into account the geographical pattern of data delivery resources, network loads and projected latencies, in order to deliver effective data-delivery strategies.
Polytope-query structures. Scientists
usually perform search queries expressed as simple range searches that involve
selecting points with coordinates that fall in a certain set of �rectangular�
ranges specified by intervals. However, modern scientific queries can more
properly be described as that of selecting all points in the interior of a
high-dimensional polytope. We have extensive experience in theoretical advances
for various range-searching problems; we propose putting that theory into
practice, and also to study new data organization schemes for supporting
polytope range searches.
Persistent and kinetic data structures. Scientific applications often include data sets of moving objects (e.g., n-body simulation, particle-tracking), yet there are very few data structures designed for kinetic data [BGS97,Cha85]. Building on our work in geometric data structuring and parallel computational geometry, we propose to study data structures for storing and tracking moving objects. In addition, we plan to apply persistence techniques for searching structures �in the past� to allow scientists to quickly and easily query kinetic data structures representing a configuration that was present at any point in the past.
1.2.2. Distributed Architectures
Scalable
Servers
���� Large data set access is
primarily I/O limited. Even with the best indexing schemes, some queries will
need to scan the entire data set. Acceptable I/O performance can be achieved
with expensive, ultra-fast storage systems, or with lots of commodity servers
in parallel [Arpaci-Dusseau98]. The latter approach can be made scalable for a
well-designed system.� Further economies
are possible by vertically partitioning the data set into a �popular 10%�
subset of attributes.� This can reduce
the cost and speed of the execution of popular queries by a factor of 10.
Another approach can offer a 1% sample of the whole database for quickly
testing and debugging programs.�
Combining these two schemes converts a 3 TBytes data set into 3 GBytes,
which can fit comfortably on desktop workstations for program development.
������ In particle and nuclear physics, the use of hierarchies of event types is being superseded by the use of class hierarchies. From a raw data event size of 0.1 to 50 MBytes, an event �tag� object is constructed, consisting of indices and a few key quantities amount to a few hundred bytes. All the �tag� objects are kept in a separate, dedicated database. The event tags point to event summary data, in the range of 0.01 to 0.1 MBytes, and reconstructed data of 1 MByte or less. The key is the adaptation of the class hierarchy, and to database containers, to ensure that the stored data is both �close� to the user, and physically contiguous as stored. The algorithms and decisions on data organization must be applied on a statistical basis in realtime, when deployed in a multi-user environment[Holtman98a,b].
���� When the whole multi-Terabyte or Petabyte database must be scanned, a parallel database server with over 1 GB/sec I/O rate is essential. Such a system has been demonstrated using Windows NT on Pentium-class Intel servers. The JHU group is collaborating with Intel in building such an experimental system with 24 dual Pentium II servers with a total of 720GB disk space. The Caltech high energy physics group and Caltech�s Center for Advanced Computing Research (CACR) has been using 0.1 to 2 Terabyte object database federations over the last year. An HP NUMA �Exemplar� system with 256 CPUs (0.2 Teraflops), 64 GBytes shared memory and large disk arrays is being used to both generate large data samples of simulated events, and to test high energy physics object database applications with up to 250 �clients.�
���� Such parallelizations are straightforward if the data are naturally partitioned into small independent chunks, a direct benefit of our data organization. We will develop the software to enable this parallelism using clusters of commodity machines, as well as more traditional midrange and large server architectures.� Well-configured servers composed of commodity components appear to be the most cost-effective way to attack the problem of large data sets for the future. The software spreads the data and computation among the nodes, shielding the users from the complexity. There are outstanding technical issues that must be addressed: load balancing large clusters, fault tolerance of nodes, merging data streams, etc. We will build �smart� servers, with high performance network links and interfaces that minimize the network load by determining the optimal network topology and workload scheduling [Szalay99c].
Searching
Distributed Data Sets
���� Very often we need to deal
with rather complex queries that will touch several data sets. A typical
example is to find an object with property A
in the data set D1, and find all
objects in data set D2, which have
property B, and are within a certain
distance (e.g. on the sky) from an object in the first query. Not only will the
data in the two (or more) data sets be at different geographical locations, but
also the queries are non-local. Only after we find an object with property A can we start searching in the other
database. The workload will strongly depend on how well we can optimize the
query, on how well the two query agents searching the databases communicate
with each other, and how quickly we can find a single object in a
multi-Terabyte archive. The agents should be autonomous to ensure robustness
and efficiency in the presence of loaded networks. They will have to be aware
of the prevailing network conditions, resources and usage policies and
priorities at each site. In the largest systems, the ensemble of agents will need
to be coordinated and managed by other special-purpose agents that work to
optimize the overall data-delivery, in a way consistent with other computing
and networking operations going on simultaneously. Again, the importance of
negotiation protocols, multidimensional indices and efficient use of the
networks cannot be emphasized enough.
���� One should also be aware of the problems of paging and locking in an hierarchical system. Objectivity/DB�s container-locking mechanism may or may not work optimally, in a straightforward way, in concert with the Objectivity page-size, and a disk page-size that may be computed in the advanced data structures. As a result, it is very important to have real testbeds, to find practical optima in single-site and distributed environments, and the use of simulation tools, a la MONARC to help understand (and simulate) the detailed behavior.
Distributed
Analysis Environment
���� It is obvious, that with
databases of Tera- to Petabyte sizes, even the intermediate data sets to be
stored locally are excessive. The only way that these can be analyzed is if the
analysis software directly communicates with the Data Warehouse, implemented on
a distributed server, as discussed above. Such an Analysis Engine can then
process the bulk of the raw data extracted from the archive, and the user needs
only to receive a drastically reduced result. Since we will make elaborate
efforts to have the server parallelised and distributed, it would not be
sensible to allow a bottleneck to occur at the analysis level. Thus we need to
consider the analysis engine as a distributed, scalable computing environment,
closely integrated with the server itself. Even the division of functions
between the server and the analysis engine will become fuzzy. A large pool of available
CPU�s may also be allocated to this task. These have to announce themselves as
available.
���� The analysis software itself must be able to run in parallel. Since it is expected that scientists with relatively little experience in distributed programming will work in this environment, we need to create a carefully crafted Application Programmer�s Interface, that will aid in the construction of customized Analysis Engines. Data extraction also needs to be considered carefully. If our server is distributed and the analysis is running on a distributed system, the extracted data should also go directly from one of the servers to one of the many Analysis Engines. Such an approach will also distribute the network load better
1.2.3. The Relevant Data Sets � Data Challenges
���� Our collaboration involves participants from several projects in astronomy and particle physics, which are gathering large data sets. These separate projects have their own funding to collect and archive their data, using today's methodologies. We are dealing with many different datasets in quality and granularity, with a lot of similarities, nevertheless. Astrophysics data are less spread out geographically today, but this is only temporary with more large data sets emerging. These will be tied together hopefully into a "virtual national Observatory", resembling the Particle Physics data sets.
���� The Sloan Digital Sky Survey (SDSS) will digitally map about half of the northern sky in five filter bands from UV to the near IR. It should detect over 200 million objects and will separately acquire spectra sufficient to determine redshifts for the brightest million galaxies, 100,000 quasars, and a somewhat lesser number of special sources. It is now clear that SDSS and other surveys will revolutionize astronomy. The project archives of this and other projects will be large (over 40 Terabytes) and complex, containing textual information, derived parameters, multi-band images, spectra, and time-series data.� The catalog of this �Cosmic Genome Project� will be used for the next several decades as the standard reference to study the evolution of the universe. The SDSS is one of the first to design an archival system to simplify the process of �data mining� and shield researchers from the need to interact directly with any underlying complex architecture. We are planning the process of knowledge discovery in the exploration of large, complex data sets.
���� The GALEX project is a satellite-based survey, which will create an all-sky ultraviolet map of the sky, in two ultraviolet bands, similar in depth and resolution to the SDSS data, creating a perfect complement. The All Sky Imaging Catalog (AIC) will measure fluxes, positions, light profiles for over 10 million galaxies. The Spectral Catalog (AIS) will create spactral information to over 100,000 objects, both galaxies and quasars. The raw data rate for the GALEX satellite will be 28 Gbits/day. The total size of the final archive is expected to be in the 2 TB range.
���� The experimental integration of these two loosely coupled archives, and other ongoing surveys is one of the goals of the astrophysics effort. Such a data set is quite similar in its distributed nature to the particle physics data sets. Searching the federation of SDSS and GALEX data will require autonomous agents searching in the separate data sets, residing at different geographical locations (Caltech, JHU, Fermilab).
���� High energy physics, and more recently nuclear physics in the high energy density regime, has a long tradition of working at the limit of hardware and software technologies. The principal computing-related challenges for the next decade are data storage and access over networks. The next generations of experiments at SLAC (Babar), Fermilab Run 2 (CDF, D0) and RHIC (Phenix and STAR) will produce hundreds of Terabytes to a Petabyte within the next two years, and several Petabytes in 5 years. The LHC experiments (CMS, ATLAS, LHCB and ALICE) will start operation with a projected combined data storage rate of several Petabytes per year starting in 2005, with simulated Petabyte-sized data sets coming earlier during the startup phase.
���� The CMS detector will use high precision measurements of photons, electrons, muons, jets and missing energy in events to validate current belief in the Standard Model, to search for the Higgs, supersymmetry and many other types of exotic new particles. The experiment, and the LHC accelerator, will continue to operate and take data at ever-increasing rates for a period of 15-20 years.
���� All of our current knowledge of fundamental interactions indicates that one of more of these new realms of physics is within the reach of the LHC, at or below the 1 TeV mass scale. Exploration of this new energy range will therefore bring with it a new level of understanding of the nature of matter�s basic constituents, and could also provide keys to understanding the unification of the interactions at the extremely high energies prevalent in the first moments of the universe. CMS and the other LHC experiments, combined with results from intermediate experiments at other laboratories over the next few years, will revolutionize our understanding of high energy and nuclear physics. The data sets associated with these experimental investigations, and anticipated discoveries, will rise from the 1 Petabyte range by 2000, the 10 Petabyte range by approximately 2006, and the 100 Petabyte range by roughly 2010.
���� Each of the LHC experiments will deploy a multi-Petabyte federation of databases, which will be analyzed by hundreds of physicists at institutes located throughout the world. The CMS experiment, for example, encompasses approximately 2000 physicists from 150 institutions in 30 countries. The search for and study of new physics, and for signs of any breakdown in the Standard Model, will take a decade or more of data analysis. The analysis will use continually refined and expanded methods and detector calibrations. Efficient access to � and renewal of � reconstructed data samples of increasing size will thus be a critical element in the potential success of physics discovery for the next twenty or thirty years. The construction of distributed data access, processing and analysis on the LHC scale, using disparate resources in many countries (including the third world) may require a superstructure beyond the realm of DBMS�s to ensure reliable and predictable data delivery over links of varying speed, loading, and quality (error rate).
1.3.
Expertise, Activities and Achievements of our Collaboration
The
Globally Interconnected Object Databases (GIOD) project
���� The GIOD project, a joint
effort between Caltech, CERN and Hewlett Packard Corporation, and instigated by
two of us (Bunn and Newman) has been investigating the use of WAN-distributed
Object Database and Mass Storage systems for use in the next generation of
particle physics experiments.� In the
Project, we have been building a prototype system that tests, validates and
develops the strategies and mechanisms that will make construction of these
massive distributed systems possible.
���� We have adopted several key technologies that seem likely to play significant roles in future particle physics computing systems: OO software (C++ and Java), commercial OO database management systems (ODBMS) (Objectivity/DB), hierarchical storage management systems (HPSS) and fast networks (ATM LAN and OC12 regional links).� The kernel of our system is a large (~1 Terabyte) Object database containing ~1,000,000 fully simulated LHC events: we use this database in all of our tests.� We have investigated scalability and clustering issues in order to understand the performance of the database for physics analysis.� These tests included making replicas of portions of the database, by moving objects in the WAN, executing analysis and reconstruction tasks on servers that are remote from the database, and exploring schemes for speeding up the selection of small sub-samples of events. The tests already touch on the challenging problem of deploying a multi-petabyte object database for physics analysis.
���� So far, the results have been most promising.� For example, we have demonstrated excellent scalability of the ODBMS for up to 250 simultaneous clients, and reliable replication of objects across transatlantic links from CERN to Caltech.� We have achieved aggregate write rates of around 170 Mbytes/second into the ODBMS, indicating the viability of direct experimental data acquisition into the database. In addition, we have developed portable physics analysis tools that operate with the database, such as a Java3D event viewer and a di-jet analysis code.� Such tools are powerful indicators that the planned systems can be made to work. A full status report from the project may be found at: https://julianbunn.org/results/report99.html.
���� Future GIOD work will include
deployment and tests of terabyte-scale databases at a few US universities and
laboratories participating in the LHC program.�
In addition to providing a source of simulated events for evaluation of
the design and discovery potential of the CMS experiment, the distributed
system of object databases will be used to explore and develop effective
strategies for distributed data access and analysis at the LHC.� These tests are foreseen to use local,
regional (CalREN-2) and the I2 backbones nationally, to explore how the
distributed system will work, and which strategies are most effective.
The
Models of Networked Analysis at Regional Centers (MONARC) project
���� This project was initiated in
mid-1998 as a follow-on to GIOD, and is a joint effort between Caltech, CERN,
FNAL, Heidelberg, INFN, KEK, Marseilles, Munich, Orsay, Oxford and Tufts. Two
of us are involved: Newman as project spokesperson, Bunn as member on all the
working groups. The project�s main goals are to define and specify the main
parameters characterizing the Computing Models of the Large Hadron Collider
(LHC) experiments, and to find cost-effective ways to perform data analysis on
an unprecedented scale. Working groups within MONARC have been launched with
mandates to determine designs for the data analysis systems. These include the
design of site-architectures at Regional Centres, the definition of feasible
analysis strategies for the LHC Collaborations, the construction of an
evolvable simulation model of the entire distributed data analysis operation,
and the implementation of a network of testbed systems to test the design
concepts and the fidelity of the system simulation. To place the work in
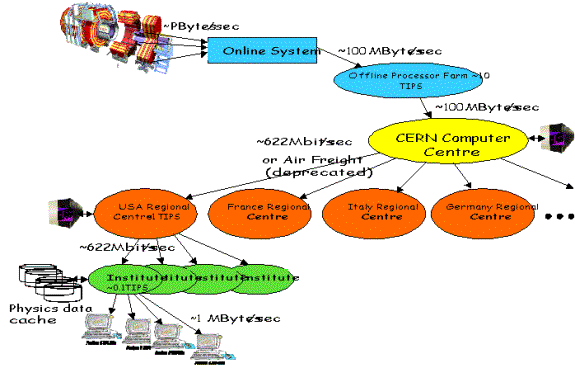
context, the following Figure shows a probable scheme for distributing data
from one of the two largest LHC experiments out to Regional Centers, and then
on to physicists' desktops. MONARC aims to evaluate the performance of such
models, to determine if the model is feasible (i.e. matched to the available
network capacity and data handling resources, with tolerable turnaround times).
The planned outcome of the project includes the specification of several
"Baseline Models" which will be used as a source of strong boundary
conditions for implementation of the production LHC computing systems. As part
of the project, we have already delevoped a portable (Java) toolset for the
simulation and performance verification of distributed analysis systems. This
tool is and will be used for ongoing design, evaluation, and further
development of the Computing Models by the experiments in the coming years.
The SDSS and GALEX Archives
���� The Science Archive and
future public archives employ a three-tiered architecture: the user interface,
an intelligent query engine, and the data warehouse. This distributed approach
provides maximum flexibility, while maintaining portability, by isolating
hardware specific features. Both the Science Archive and the Operational
Archive are built on top of Objectivity/DB, a commercial OODBMS. Our current
experimental system is written in C++, using the Rogue Wave Tools.h++ and
Net.h++ libraries. We have developed our own query language, a subset of SQL,
implementing some special operators for spatial relations.
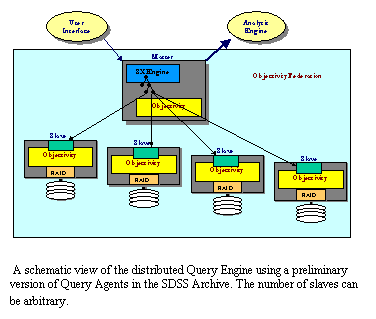
 ���� The
SDSS data is too large to fit on one disk or one server. The system is
currently based on a distributed LAN/SAN architecture, where data are spatially
partitioned among multiple servers, executing in parallel (see section on
Building Scalable Systems) for higher I/O speed. The system is designed for a
scalable architecture � as new servers are added, the data will repartition.� New data will be placed to its
partition.� Some of the high-traffic data
will be replicated among servers.� It is
up to the database software to manage this partitioning and replication.� In the near term, designers specify the
partitioning and index schemes, but we hope that in the long term, the DBMS
will automate this design task as access patterns change, to make our approach
more generally useable.
���� The
SDSS data is too large to fit on one disk or one server. The system is
currently based on a distributed LAN/SAN architecture, where data are spatially
partitioned among multiple servers, executing in parallel (see section on
Building Scalable Systems) for higher I/O speed. The system is designed for a
scalable architecture � as new servers are added, the data will repartition.� New data will be placed to its
partition.� Some of the high-traffic data
will be replicated among servers.� It is
up to the database software to manage this partitioning and replication.� In the near term, designers specify the
partitioning and index schemes, but we hope that in the long term, the DBMS
will automate this design task as access patterns change, to make our approach
more generally useable.
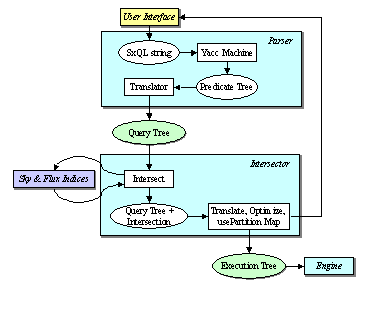
 ���� Each
query received from the User Interface is parsed into a Query Execution Tree
(QET) that is then executed by the Query Engine.� Each node of the QET is either a query or a
set-operation node, and returns a bag of object-pointers upon execution. The
multi-threaded Query Agents execute in parallel at all the nodes at a given
level of the QET. Results from child nodes are passed up the tree as soon as
they are generated.� In the case of
aggregation, sort, intersection and difference nodes, at least one of the child
nodes must be complete before results can be sent further up the tree. In
addition to speeding up the query processing, this ASAP data push strategy
ensures that even in the case of a query that takes a very long time to
complete, the user starts seeing results almost immediately, or at least as
soon as the first selected object percolates up the tree. This mode of
distributed querying is a unique feature of our design, normally an OODBMS
serves the raw objects, from multiple�
data sources, which are all queried at the client � ere they are all
queried close to their physical location, minimizing the need to move large
amounts of data.
���� Each
query received from the User Interface is parsed into a Query Execution Tree
(QET) that is then executed by the Query Engine.� Each node of the QET is either a query or a
set-operation node, and returns a bag of object-pointers upon execution. The
multi-threaded Query Agents execute in parallel at all the nodes at a given
level of the QET. Results from child nodes are passed up the tree as soon as
they are generated.� In the case of
aggregation, sort, intersection and difference nodes, at least one of the child
nodes must be complete before results can be sent further up the tree. In
addition to speeding up the query processing, this ASAP data push strategy
ensures that even in the case of a query that takes a very long time to
complete, the user starts seeing results almost immediately, or at least as
soon as the first selected object percolates up the tree. This mode of
distributed querying is a unique feature of our design, normally an OODBMS
serves the raw objects, from multiple�
data sources, which are all queried at the client � ere they are all
queried close to their physical location, minimizing the need to move large
amounts of data.
���� The SDSS data has high dimensi-onality � each item has more than a hundred attributes. Categorizing objects involves defining complex domains (classifications) in this N - dimensional space, corresponding to decision surfaces. Our group is investigating algorithms and data structures to quickly compute spatial relations [Csabai97], such as finding nearest neighbors, or other objects satisfying a given criterion within a metric distance. The answer set cardinality can be so large that intermediate files simply cannot be created. The only way to analyze such data sets is to pipeline the answers directly into analysis tools.� This data flow analysis has worked well for parallel relational database systems [DeWitt92].� We expect these data river ideas will have merit for scientific data analysis as well.� These data rivers link the archive directly to the analysis and visualization tools.
Sky Partitioning
���� There is a lot of interest in
the definition of common areas over the sky, which can be universally used by
different astronomical databases. The need for such a system is indicated by
the widespread use of the ancient constellations � the first spatial index of
the celestial sphere. The existence of such an index, in a more computer
friendly form will substantially speed up cross-referencing among other
catalogs. Such an index may also be of considerable importance for storing data
related to the Earth, in particular GIS systems.
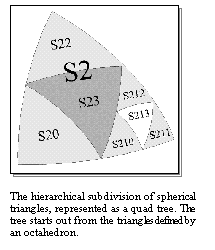 ���� Having
a common scheme, that provides a balanced partitioning for all catalogs, may
seem to be impossible, but there is an elegant solution, a �shoe that fits all�:
subdivide the sky in a hierarchical fashion! Instead of taking a fixed
subdivision, we specify an increasingly finer hierarchy, where each level is
fully contained within the previous one. Starting with an octahedron base set,
each spherical triangle can be recursively divided into 4 sub-triangles of
approximately equal areas. Each sub-area can be divided further into additional
four sub-areas, ad infinitum. Such hierarchical subdivisions can be very
efficiently represented in the form of quad-trees. Areas in different catalogs
map either directly onto one another, or one is fully contained by another.
���� Having
a common scheme, that provides a balanced partitioning for all catalogs, may
seem to be impossible, but there is an elegant solution, a �shoe that fits all�:
subdivide the sky in a hierarchical fashion! Instead of taking a fixed
subdivision, we specify an increasingly finer hierarchy, where each level is
fully contained within the previous one. Starting with an octahedron base set,
each spherical triangle can be recursively divided into 4 sub-triangles of
approximately equal areas. Each sub-area can be divided further into additional
four sub-areas, ad infinitum. Such hierarchical subdivisions can be very
efficiently represented in the form of quad-trees. Areas in different catalogs
map either directly onto one another, or one is fully contained by another.
���� We store the angular coordinates in a Cartesian form, i.e. as a triplet of x,y,z values per object.� The x,y,z numbers represent only the position of objects on the sky, corresponding to the normal vector pointing to the object. (We can guess the distance to only a tiny fraction of the 200 million objects in the catalog.) While at first this may seem to increase the required storage (three numbers per object vs two angles, it makes querying the database for objects within certain areas of the celestial sphere, or involving different coordinate systems considerably more efficient. This technique was used successfully by the GSC project [GSC2]. The coordinates in the different celestial coordinate systems (Equatorial, Galactic, Supergalactic, etc) can be constructed from the Cartesian coordinate on the fly. Due to the three-dimensional Cartesian representation of the angular coordinates, queries to find objects within a certain spherical distance from a given point, or combination of constraints in arbitrary spherical coordinate systems become particularly simple. They correspond to testing linear combinations of the three Cartesian coordinates instead of complicated trigonometric expressions.
 ���� The
two ideas, partitioning and Cartesian coordinates merge into a highly efficient
storage, retrieval and indexing scheme. We [Szalay99] have created a recursive
algorithm that can determine which parts of the sky are relevant for a
particular query. Each query can be represented as a set of half-space
constraints, connected by Boolean operators, all in three-dimensional space.
���� The
two ideas, partitioning and Cartesian coordinates merge into a highly efficient
storage, retrieval and indexing scheme. We [Szalay99] have created a recursive
algorithm that can determine which parts of the sky are relevant for a
particular query. Each query can be represented as a set of half-space
constraints, connected by Boolean operators, all in three-dimensional space.
���� The task of finding objects that satisfy a given query can be performed recursively as follows.� Run a test between the query polyhedron and the spherical triangles corresponding to the tree root nodes. The intersection algorithm is very efficient because it is easy to test spherical triangle intersection. Classify nodes, as fully outside the query, fully inside the query or partially intersecting the query polyhedron. If a node is rejected, that node's children can be ignored. Only the children of bisected triangles need be further investigated. The intersection test is executed recursively on these nodes. The SDSS Science Archive implemented this algorithm in its prototype query engine [Szalay97].
1.4. Common
Challenges in Computing for Astronomy and Particle Physics
1.4.1. The Commonality of our Approach
���� Despite the obvious difference between the applications and the data that are used in the fields of astronomy and particle physics, there are numerous common and crucial areas of the computing task that together amply justify a joint research effort. First of all, the sheer amount of data has forced both communities to move from flat files to highly organized databases. The complex nature of the data suggested the use of an object-oriented system. After careful evaluation of the available technologies, both communities converged independently on the same choice of ODBMS (Objectivity/DB). In addition, the following problems face both communities:
� How are we going to integrate the querying algorithms and other tools to speed up the database access?
� How are we going to cluster the data optimally for fast access?
� How can we optimize the clustering and querying of data distributed across continents?
� What dynamical reclustering strategies should be used as we study the usage patterns?
���� By designing a layer of middleware, which operates between the low-level data warehouse and the user tools, a common framework can be created that can be used by both communities. The particular details on what precise data structures are used to store and hierarchically organize the data may be different between astronomy and particle physics. In the beginning, these will be built heuristically, using domain-specific expertise, but will be implemented within the same middleware and distributed environment. Towards the end of this project we expect to be able to identify a few algorithms for data clustering that work well for astronomy and particle physics, and which might therefore generalize into other scientific domains.
���� Many of these overlapping and complementary interests form the basis of our collaboration. The Caltech group has considerable expertise in building and implementing distributed WAN-based ODBMS systems. The JHU/Fermilab group has experimented with spatial indexing, distributed query agents, all in a LAN environment. Gray of Microsoft is an expert on scalable systems, and how to tune and balance them. Goodrich is currently working on advanced data clustering algorithms, which may grow into a generic tool.
���� Below we outline, how we propose to make the best use of our joint expertise. The first task we would like to do is to analyze carefully what are the questions that we would like to ask from the data archive. These include some very simple tasks, but also others, which require non-local information, like dynamic cluster analysis, or spatial proximities in some unusual metric spaces. The result of this analysis will be reflected in the special operators we need to implement, and query language enhancements to be defined. Another area of research will be on scalable server architectures � no single architecture is optimal for all possible uses. By having multiple �views� of the data (or at least of some selected part of the data) we dampen the effects of �worst-case queries�. Having smaller, statistically representative subsets, like the 5% most popular attributes, or a 1% random subset may make the task of debugging analysis software, and getting a "feel" for the nature of the data much more efficient. The most important area of our collaboration is to create the intelligent middleware, by merging what we learned on locally running distributed query agents with the GIOD experience of implementing large object databases across WAN connections. There are substantial differences between a LAN/SAN environment and the WAN connected world: the optimization will be non-trivial, and will require a substantial amount of additional work. We plan on creating a large scale Test Bed system to test, analyze and measure the performance of our system in a real-world case.
���� The joint development of data access solutions that are applicable for both astrophysics and particle physics will have substantial benefit for each field. The tree-based and geometrical data access strategies of astrophysics could be applied or extended to derive optimal clustering/reclustering strategies for particle physics. Scaling from terabytes to petabytes, and to globally-distributed systems housing multiple database federations, is a prime focus of current research in particle and nuclear physics, through the GIOD, MONARC and the just-starting Particle Physics Data Grid (PPDG) projects.� Optimal strategies of data delivery in distributed systems, taking site architectures, system status in real time, and tradeoffs between the effective �costs� of recomputation and of data transport (cost measured in resource-usage and/or time delay) are areas where HEP experience could lead to improved solutions for astrophysics as it moves from terabyte-to petabyte-scale data archives over the coming decade.
���� A strategic open question is how to meld the ideas of fine-grained �tightly coupled� systems used on the terabyte scale for astrophysics, with the more loosely-coupled coarser-grained and heterogenous data-delivery and processing systems of the large particle physics experiments. The former ideas could lead to higher-speed access for a given DB (or DB-federation) size, while the latter loosely coupled ideas are certainly needed for larger, more geographically dispersed systems running over international (including transoceanic) networks. Bringing these two aspects into �collision� will engender new system-solutions that will have broader applicability than solutions derived to serve one field or the other in isolation. Our proposed research is distinct from our ongoing respective activities, although we fully intend to leverage off of these projects� evolving experience.
1.4.2. Analysis of Typical and Enhanced Queries
���� We will evaluate the middleware and the distributed systems described above with a set of typical tasks, in the form of representative database queries from the two disciplines. This technique has proved to be most useful in the past, based on Jim Gray�s experience with the Sequoia Project.� We propose defining 20 queries for each of the two disciplines. In our experience, this figure is about the right number to challenge the system and obtain a meaningful measurement of its general performance. A few of the queries will be trivial, but some will represent difficult tasks considerably beyond the capabilities of any relational, SQL based system. Some examples of these include queries based on spatial proximities between two classes selected by different predicates. A few examples of these 20 candidate queries follow below:
|
Astronomy Queries |
Particle Physics Queries |
|
Find galaxies with an isophotal major axis 30"<d<1', at an
r-band surface brightness=24mag/arcsec2 , and with an
ellipticity>0.5 |
Select all events with at least two Jets,
each Jet having a transverse momentum of at least 20 GeV, then calculate and
graph the invariant mass of the di-Jet combinations |
|
Find all galaxies at 30<b<40, -10<sgb<10, and dec<0 |
Select all events consistent with any
decay mode of the Higgs particle and return their identifiers |
|
Find all galaxies without unsaturated pixels within 1' of a given
point of ra=75.327, dec=21.023 |
Select all space points in detector X that
lie on a helix with parameters (R,Phi,Z,Theta,Rtr) |
|
Find all galaxies with a deVaucouleours
profile, and the photometric colors consistent with an elliptical |
Fit the latest Higgs mass spectrum to a
falling exponential and a Breit-Wigner function |
|
Find galaxies that are blended with a
star, output the deblended magnitudes |
Move all SuperSymmetry event candidates to
a dedicated database at Caltech |
|
Create a gridded count of galaxies with u-g>1 and r<21.5 over
60<dec<70, and 200<ra<210, on a grid of 2', and create a map of
masks over the same grid |
Return all tracks within distance D of
electron candidate E in event N |
|
Provide a list of stars with multiple
epoch measurements, which have light variations >0.1m |
Search for any events with three
electrons, muons or taus, and return their identifiers |
|
Provide a list of moving objects consistent with an asteroid |
Flag all tracks for Run R as invalid, to
be reconstructed on demand later |
|
Find all objects within 1' which have more
than two neighbors with u-g, g-r, r-I colors within 0.05m |
Replicate a remote results database at
Caltech into the main Federation |
|
Find binary stars where at least one of them has the colors of a
white dwarf |
|
|
For a galaxy in the BCG data set, in 160<ra<170,
25<dec<35, give a count of galaxies within 30" which have a
photometric redshift within 0.05 of the BCG |
|
|
Find quasars with a broad absorption line
in their spectra and at least one galaxy within 10". Return both the
quasars and the galaxies |
|
A careful analysis of these queries will be performed, and as the result we will create certain special operators, which can evaluate certain functions, like spatial proximity, or proximity in a certain subspace of attributes, given a proper distance metric. These operators will then be added to our query language. For efficiency, they will use the features of the internal indices. Other types of operators may build a minimal spanning tree over a certain metric, then cut the links longer than a certain distance, to recognize clusters (objects of similar properties) of a given size.
1.4.3. Building Scalable Server Architectures
���� Accessing large data sets is primarily I/O limited. Even with the best indexing schemes, some queries must scan the entire data set. Acceptable I/O performance can be achieved with expensive, ultra-fast storage systems, or with many of commodity servers operating in parallel. We are exploring the use of commodity servers and storage to allow inexpensive interactive data analysis.� We are still exploring what constitutes a balanced system design: the appropriate ratio between processor, memory, network bandwidth and disk bandwidth.��
���� Using the multi-dimensional indexing techniques described in the previous section, many queries will be able to select exactly the data they need after doing an index lookup.�� Such simple queries will just pipeline the data and images off of disk as quickly as the network can transport it to the user's system for analysis or visualization. When the queries are more complex, it will be necessary to scan the entire dataset or to repartition it for categorization, clustering, and cross comparisons.� Experience will teach us the necessary ratio between processor power, main memory size, IO bandwidth, and system-area-network bandwidth.
���� Our simplest approach is to run a scan machine that continuously scans the dataset evaluating user-supplied predicates on each object [Acharya95].� We are building an array of 20 nodes.� Each node has 4 Intel Xeon 450 Mhz processors, 256MB of RAM, and 12x18GB disks (4TB of storage in all). Experiments by Andrew Hartman of Dell Computers show that one node is capable of reading data at 150 MBps while using almost no processor time [Hartman98].� If the data is spread among the 20 nodes, they can scan the data at an aggregate rate of 3 GBps. This half-million dollar system could scan the complete (year 2004) SDSS catalog every 2 minutes.� By then these machines should be 10x faster.� This should give near-interactive response to most complex queries that involve single-object predicates.
���� Many queries involve comparing, classifying or clustering objects. We expect to provide a second class of machine, called a hash machine that performs comparisons within data clusters.� Hash machines redistribute a subset of the data among all the nodes of the cluster. Then each node processes each hash bucket at that node.� This parallel-clustering approach has worked extremely well for relational databases in joining and aggregating data.� We believe it will work equally well for scientific spatial data. The hash phase scans the entire dataset, selects a subset of the objects based on some predicate, and "hashes" each object to the appropriate buckets � a single object may go to several buckets (to allow objects near the edges of a region to go to all the neighboring regions as well).� In a second phase all the objects in a bucket are compared to one another. The output is a stream of objects with corresponding attributes.��
���� These operations are analogous to relational hash-join, hence the name [DeWitt92].� Like hash joins, the hash machine can be a highly parallel, processing the entire database in a few minutes. The application of the hash-machine to tasks like finding gravitational lenses or clustering by spectrum or by velocity vector should be obvious: each bucket represents a neighborhood in these high-dimensional spaces. We envision a non-procedural programming interface to define the bucket partition function and to define the bucket analysis function.
���� The hash machine is a simple form of the more general data-flow programming model in which data flows from storage through various processing steps.� Each step is amenable to partition parallelism. The underlying system manages the creation and processing of the flows.� This programming style has evolved both in the database community [DeWitt92, Graefe93, Barclay 95] and in the scientific programming community with PVM and MPI [Gropp98].� This has evolved to a general programming model as typified by a river system [Arpaci-Dusseau 99].�
���� We propose to let the users construct dataflow graphs where the nodes consume one or more data streams, filter and combine the data, and then produce one or more result streams.� The outputs of these rivers either go back to the database or to visualization programs. These dataflow graphs will be executed on a river-machine similar to the scan and hash machine. The simplest river systems are sorting networks. Current systems have demonstrated that they can sort at about 100 MBps using commodity hardware and 5 GBps if using thousands of nodes and disks [Sort].�� We will build smaller versions of each of these architectures and compare them in a real-life environment. We will experiment with different underlying database systems, and compare their performance to the fiducial Objectivity/DB realizations. In particular we will build alternate versions with SQL Server, Oracle 8 and Jasmine.
1.4.4. Prototype Agent-based Query system
���� To aid in experimentation with novel data organization techniques and distribution and delivery strategies, we propose to deploy a Test Bed, which incorporates parts of the distributed resources we already have available at our institutes.
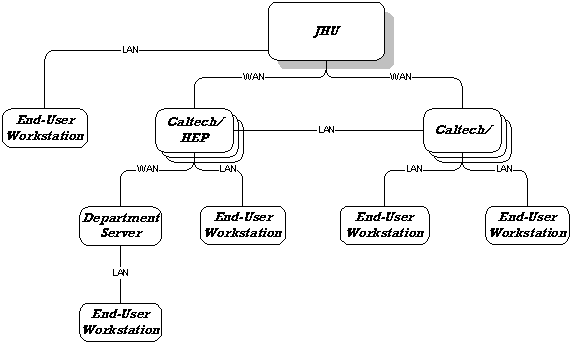
This figure shows the network architecture of our
Test Bed. Data is stored and queried at all locations. The configuration
contains a mix of various speed LAN and WAN connections
���� The architecture of the Test Bed can be envisaged as a tree structure (see Figure) with the primary node (JHU) being the location of the primary store of and the leaf nodes being end-users� workstations. Intermediate nodes in the tree correspond to �Satellite� data centers, and Department servers. The workstations are LAN-connected devices located at the Primary Site, or a Satellite center at Caltech. The Satellite centers and the Primary site are interconnected via high-speed WAN links. Data is stored at all locations, in the form of an Objectivity/DB Federation, organized into Autonomous Partitions.
���� In the Test Bed, researchers will be issuing selection queries on the available data. How the query is formulated, and how it gets parsed, depends on the analysis tool being used. The particular tools we have in mind are custom applications built with Objectivity/DB, but all built on top of our middleware. A typical meta-language query on a particle physics dataset might be: �Select all events with two photons, each with PT of at least 20 GeV, and return a histogram of the invariant mass of the pair�, or "find all quasars in the SDSS catalog brighter than r=20, with spectra, which are also detected in GALEX". Further representative queries are listed in 1.4.2.
���� This query will typically involve the creation of database and container iterators that cycle over all the event data available. The goal is to arrange the system so as to minimize the amount of time spent on the query, and return the results as quickly as possible. This can be partly achieved by organizing the databases so that they are local to the machine executing the query, or by sending the query to be executed on the machines hosting the databases. These are the Query Agents mentioned before. The Test Bed allows us to explore different methods for organizing the data and query execution.
1.4.5. Test Bed System Description
To leverage the codes and algorithms that we have already developed in our collaborations, we propose an integration layer of middleware based on Autonomous Agents. The middleware is a software and data �jacket� that:
(1) encapsulates the existing analysis tool or algorithm,
(2) has topological knowledge of the Test Bed system,
(3) is aware of prevailing conditions in the Test Bed (system loads and network conditions)
(4) uses tried and trusted vehicles for query distribution and execution (e.g.� Condor)
We propose to use Agent technology (in particular the �Aglets� toolkit from IBM [ref.]) to implement the integration middleware as a networked system. Agents are small entities that carry code, data and rules in the network. They move on an itinerary between Agent servers that are located in the system. The JHU site, all the Satellite centers and the Department systems run Agent servers. The servers maintain a catalogue of locally (LAN) available database files, and a cache of recently executed query results.
For each query, an Agent is created in the most proximate Agent server in the Test Bed system, on behalf of the user. The Agent intercepts the query, generates from it a set of required database files, decides which locations the query should execute at, and then dispatches the query accordingly. To do this, the Agent starts by internal communication with the analysis tool, as a proxy for the end user, and does the following:
� Determines the list of database files required to satisfy this query
� For each file i in the list:
� If the file is locally available:
� evaluates the access cost function, Ai
� evaluates the processing cost function, PI
� If the file is not locally available, marks it as such
� Stores the cost functions
� Evaluates local cost for the query, as ? Pi Ai
���� Developing suitable access cost functions, Ai, is one goal of this research. Clearly, it needs to take into account the speed of the media on which the file is stored, its latency and so on. Likewise the processing cost function, P, will take into account system load and other prevailing conditions on the machines in the system. If all the required files are available on the local system, the Agent simply executes the query, and encapsulates the results in a suitable format (we suggest using XML as a platform independent data description language). These results are immediately retrievable by the end user. They are also cached in the proximate Agent server.
���� If one or more of the required files is not available locally (which will normally be the case), then the Agent is dispatched on an itinerary that includes all the Agent servers in the system. On arrival at each Server, the Agent evaluates the cost functions for the files it requires, adds these to a list, and moves on to the next Server. Eventually it arrives back at its birthplace. At this point it can suggest whether it is best to dispatch the user�s query to one or more remote servers, or whether the required database files should be transferred across the network to the local machine and executed there. This information is made available to the end user who must then decide what is to be done. (Making this decision automatic is another goal of the research.)
���� There are two possible outcomes: either the query must be executed locally, or it must be executed (at least in part) remotely. In either case the locations of the required databases are known. If database files need to be transferred from one system to another before the query can execute, then this process will be managed by separate �file mover� Agents, who travel to the target system Server and invoke FTP (or whatever), and then perhaps a subsequent step such as an ooattachdb for an Objectivity database. The file mover Agents must all return to the proximate Server before the query can start (perhaps some concurrency will be possible).
���� This is a very simple scheme, which is robust against network congestion or outages. At any moment, the end user can interrogate the status of the Agent�s results, its position on the Server itinerary, and the prevailing conditions. The user can request that the Agent terminate and return immediately at any time. Note that the Agent does not (can not) move to a new Server if the network is unavailable to that Server: in these cases it can select a different one from its itinerary. Timeouts would eventually force the Agent to return to its birthplace in the case of extreme network congestion. The scheme lends itself very well to unattended (or �batch�) execution, since the end user does not need to interact with the Agent. Even when the Agent has completed executing the query on the user�s behalf, the results are stored in XML form on the proximate Server for later perusal. (The user query result cache in each Server should mark un-read result files against purge out of the cache.)
���� The system should have a �large time quantum� property, to be used by scheduling of queries. For example, if a query has to scan over a large fraction of the data, it may be more optimal to queue these, and scan the data once per time quantum, then execute all the relevant queries simultaneously. We also need to accommodate differentiated services, higher priority given to shorter interactive tasks, or real-time time-shared applications over longer queries. A detailed profiling utility will be used to measure resource usage, and to develop the appropriate prioritization policies via carefully balanced cost functions.
1.5. Planned
Outcomes of the Research
���� Here we describe our specific plans. We do request funding for
the steps beyond the immediate data collection and storage needs of the
individual projects, all in the area of our proposed research:
Advanced Data Structures:
� We will explore what data structures, and physical hierarchical data storage configurations, can provide the biggest benefit for the archival of the next generation astronomy and particle physics experiments. We will also explore how hierarchical storage maps onto the data organization. We will develop tools that can be shared beyond the immediate disciplines.
� We will build and distribute our prototype spatial index, designed to handle spherical data, very efficient for both astronomical and GIS data, and make it publicly available as a class library.
Prototyping Distributed Systems:
� We will experiment with different scalable server architectures, like the scan machine, river machine and hash machine, and evaluate their respective performances
� We will implement multiple versions of our distributed data warehouse, using different database systems (not only Objectivity/DB, but also SQL Server, Oracle 8 and Jasmine).
� We will experiment with novel data organization techniques, distribution and delivery strategies, for single sites and distributed systems. We will create prototypes, locally and across wide area networks, and measure their relative efficiencies. We will implement our data structures on scalable servers, and benchmark the scalability, using local and long-range networks in different bandwidth ranges, with various quality of service (QoS) mechanisms.
� We will build distributed databases, containing Terabytes of real data, connected with hierarchies of high-speed networks. We will create intelligent query agents, capable of operating in a distributed environment, aware of the network status, resources and policies. We will implement these systems on an array of commodity servers.
� We will deploy and develop a distributed Test Bed system which we will use to validate and test our research using representative subsets of the data stores available from our two disciplines.�
Deliverables:
� We will develop a code base of middleware, which will enable efficient querying of large distributed data sets, without the need to move a lot of data, and which will be developed to professional coding standards.
� We will create a toolkit to generate a formal query language, which is easily extensible, and interfaces well to the middleware, can address issues about distributed data archives.
� We will produce a series of technical reports that describe our experiments, and discuss the tradeoffs we encountered, the performance gains we were able to achieve, the comparisons between different database systems and architectures, depending on the different types of queries.
� We expect to define a set of specific guidelines for scientists in other disciplines, who want to build similar persistent object stores. The recommendations would address (a) server architectures, (b) network topologies, (c) advanced data structures/ data models (d) query formulation (e) architecting distributed query/analysis tools.
� One the deliverables will be a simulation-model that enables us to predict the behavior of larger systems than can presently be assembled with a reasonable budget.
2. Appropriateness for KDI & Roles of Project Personnel
���� Our project is at the intersection of several different disciplines. It involves astronomers (Szalay, Vishniac, Martin), particle physicists (Newman, Pevsner, Bunn), database experts (Gray) and experts in data structures and computational geometry (Goodrich), and representatives of various areas of the industry (Intel - database servers, Cisco - networking technologies, Objectivity/DB - object oriented databases, Microsoft - relational databases).
���� The focus of the proposal is to explore various alternative ways how large data sets consisting of many Terabytes of data, distributed over several continents can be organized and managed in a way, that enables efficient scientific analysis. Particle physicists and astronomers (and many other scientific disciplines as well) are faced with these large data sets, obtained by multinational collaborations. Both of these disciplines are converging on a methodology, which appears to be rather similar: store the data in distributed object oriented databases, in a highly structured form, and use a sophisticated framework of analysis and query tools built on top of the database. Once we realized how large the overlap is in the methods and tools between the two areas (astronomy/particle physics), our collaboration was natural. We have been exchanging ideas and consulting with each other for over a year.
���� Our group is rather heavily weighted towards application domain scientists � physicists and astronomers. This is the natural outcome of the enormous pressure that our currently available data sets produce. We need to experiment with concrete (not simulated) data immediately, and we need deployable systems on a few years' timescale. At the same time most of the physicists and astronomers in our group are rather knowledgeable about computer science, and had a hands-on experience for over a decade in manipulating large amounts of data. Our CoI's from computer science represent a very important expertise in the two critical areas of relevance, scaleable database servers and advanced data structures. They are also genuinely interested in working on these problems � we have been actively collaborating for a long time. Szalay and Gray just finished a paper on the SDSS archive design [Szalay 99], Goodrich and Szalay are jointly supervising several computer science students working on this research.
Johns Hopkins: Szalay, an astrophysicist is the chief designer of the archive for the Sloan Digital Sky Survey project, a collaboration of several institutions, including Johns Hopkins and Fermilab. He is also responsible for the archive of the GALEX project, a collaboration of Caltech and JHU, among others. For several years he has closely collaborated with Goodrich, a computer scientist, with special expertise in advanced data structures and computational geometry. Vishniac, a theoretical astrophysicist, is an expert in statistical data analysis of large data sets. Pevsner, a particle physicist, the discoverer of the ?-meson, has an involvement with the CERN experiments and has been actively working with the SDSS archive effort at JHU.
Caltech: Newman, a particle physicist, is spokesperson for the US collaboration within the CERN CMS experiment. He has been experimenting with distributed databases for several years. He originated international networking in the field of particle physics in 1982; (he was a member of the NSF Technical Advisory Group for NSFNET in 1986-7) and has been responsible for US-CERN networking on behalf of the US HEP community since 1985.� He has recently submitted the plan for US-CERN networking to meet the LHC program�s needs to the DoE, as extension of our existing US-CERN link, based on the ICFA-recognized requirements report that he authored last year (see http://l3www.cern.ch/~newman/icfareq98.html). He is also a member of the ICFA Standing Committee on International Connectivity.� Bunn, a particle physicist, with enormous expertise in scientific computation, has been directly involved with the design and implementation of many of the testbed systems built at CERN and Caltech. Martin, an astronomer, is the PI of the GALEX satellite.
Fermilab:Nash, a particle physicist, is heavily involved with the SDSS project, he is overseeing the data processing at Fermilab, and he is also a member of the SDSS Advisory Council. He is involved with the data processing aspects of� CMS.
Microsoft: Jim Gray of Microsoft, is one of the world's leading computer scientists, a recent recipient of the Turing prize. He has been collaborating with Szalay for the last 18 months on the design of the SDSS archive system. He has also been on the advisory board of Objectivity. He is a member of the Presidential Information Technology Advisory Committee (PITAC). He is interested in using commodity servers for large archives, and comparing several design solutions and architectures.
3. Results from Prior NSF Support
Results from Prior NSF Support by Alexander Szalay
PI: Alexander Szalay, JHU
Award title: The Structure of the Universe Beyond 100 Mpc
Award number: AST 90-20380
Support period: 01/01/1992 -- 12/31/1994
Amount: $192,000 total
Recent
research, awarded support by the NSF from 1992-1994, was aimed at understanding
the redshift distribution of galaxies obtained in a few very deep but
well-sampled redshift surveys. The first results of a combined survey at the
North and South Galactic Poles indicated a strong one-dimensional clustering of
galaxies, on a scale exceeding 100 Mpc, with a provocative regularity
(Broadhurst etal 1990, BEKS). This paper has generated a lot of interest, but
also a lot of controversy. The results suggested that features, like the �Great
Wall�, (de Lapparent etal 1986) are quite general. On the other hand the
extreme regularity in the data (with a sharply defined scale of 128 Mpc) was
not easy to understand. There was a lot of debate about the features found in
the survey, about the statistics applied, about the fluctuations due to the
sample size (the survey only consisted of 396 galaxies, in two 30 arc minute
pencilbeams). The major questions were about the reality of the detected peak
in the power spectrum (real or just chance), about the transverse extent of the
spikes in the redshift distribution (walls or groups), and about the redshift
distribution in other, independent samples. In order to get closer to answering
these questions it was clearly necessary to collect further new data, and
perform various other statistical tests on the existing data.
Over the grant
period, the PI has succeeded in accomplishing the research goals proposed:
extended the original analysis, substantially increased the data set by new
observations, developed new analysis techniques, and applied these to other
data sets as well. After an initial 1.5 years the list of redshifts has been
made electronically available for anyone who requested a copy.
Since the BEKS
paper, several nearby data sets have been analysed to find traces of the 128
Mpc scale (Vettolani etal 1993, Collins etal 1993) -- with success. We conclude
that the statements of the original Nature paper�even though they were
considered to be provocative at the time�have been confirmed by subsequent
independent observations and analyses. How it fits into the general scheme of
cosmological models is an other question.
Specific
results:
�
We
have performed a more detailed analysis of the statistical significance of the
peak in the power spectrum (Szalay etal 1993). This has shown that by
determining the level of �aliased power� from the small scales one can measure
the significance without external assumptions. Different variants of our
analysis technique, applied to the BEKS data have been performed since
(e.g.� Luo and Vishniac 1993).
�
We
have performed numerical simulations of extreme non-Gaussian distributions, by
placing galaxies on thin walls of a Voronoi-foam, with a built-in
characteristic scale of 100 Mpc.�
Pencilbeam surveys in the models, simulating BEKS, had a peak similar to
BEKS in about 5-10 percent of the cases. This implies that the observed �periodicity�
occurs quite frequently in the presence of large, thin �walls� (SubbaRao and
Szalay 1992).
�
By
applying successfully for more telescope time (KPNO, AAT), in the NGP/SGP
region we have now 10 pencilbeams each, over a 6x6 degree field, containing
over 1100 galaxies.� We have extended the
usual power spectrum analysis to cross-correlation power spectra by only using
pairs of galaxies which are in different pencil-beams. This almost entirely
eliminates the criticism due to �aliasing� (Kaiser and Peacock 1991) -- the
transfer of small scale clustering power to large scales. The large peak in the
wide angle NGP/SGP power spectrum is just as strong as in the original
pencil-beams, indicating that most of the signal is contained in structures of
large transverse extent.
�
We
have carried out a survey of a mini-slice (4o by 40�) around the
NGP, to intermediate depth (B<20), in order to study the coherence of the
nearest few spikes (Willmer etal 1994). We have now redshifts to 327 of 1000
galaxies within this magnitude range. One of the spikes has a definite
wall-like appearence, while another is clearly a localised group.
�
In
order to explore other directions we have successfully obtained more than 20
nights on 4m telescopes (KPNO, AAT, CTIO, INT) and collected over 2000
redshifts to a limiting magnitude of B=21.5.
�
With
Mark SubbaRao, we have extended Lynden-Bell�s C-method of luminosity function
determination, and applied it to the pencil beam catalogs, containing a lot of
low luminosity galaxies.� In
collaboration with others (Koo etal, to be submitted early 1995), we have found
that the faint end of the luminosity function is quite steep.
�
With
Stephen Landy we have devised an improved estimator for angular correlations of
galaxies, with a reduced variance for small samples (Landy and Szalay 1992). The
technique has since been used by several other groups (Bernstein etal 1994,
Bernstein 1994, Brainerd etal 1994). The main motivation for this technique was
to study systematic changes in the angular correlation properties of galaxies
with their observed colors.
�
Various
color cuts (like selecting faint blue galaxies) affect the redshift
distribution of the sample. The number of random projected pairs is
proportional to the second moment of the dn/dz distribution, thus angular
correlations provide a very sensitive measure of this quantity. Combined with
the number counts, we found, that contrary to common belief the bluest part of
the faint galaxy population is very strongly clustered in angle. The only
simple resolution is if the blue population consists of intrinsically faint
galaxies at low (approx 0.2-0.3) redshifts (submitted for publication recently,
Landy, Szalay and Koo 1994).
�
Another
related application of the same correlation technique has been the analysis of
a set of color selected faint galaxies in the vicinity of a broad absorption
system at z=3.4 (Giavalisco, Steidel and Szalay 1994). The strength of the
clustering�in spite of the small number of objects detected�is consistent with
a cluster of galaxies at that redshift.
�
With
Istvan Szapudi we have devised several new statistical techniques to
characterize higher order correlations on small scales.� Of these the most promising is the method of
factorial correlators, which reduces the effects of shot noise in an elegant
fashion (Szapudi and Szalay 1993). This has been applied to all existing large
catalogs: Lick (Szapudi etal 1992), IRAS (Meiksin etal 1992), APM (Szapudi etal
1994), in various collaborations with P. Boschan, A.� Meiksin, G.Dalton and G.Efstathiou. We have
shown from the data, that the higher order correlation functions are fully
consistent with the gravitational hierarchy, up to 10th order, and
we measured the clustering amplitudes (Szapudi etal 1994).
�
The
mathematical and statistical techniques applied in these projects provided a
natural explanation for a long standing puzzle: the strong amplification of
cluster correlations (Bahcall and Soneira 1982, Bahcall 1990). We have shown,
that they are almost entirely due to these higher order correlations
interacting with the cluster finding algorithm, basically in agreement with
Kaiser�s original motivation for biasing (Kaiser 1984).
Human
aspects, graduate students
The PI had a
lively interaction with his graduate students through these projects. Stephen
Landy graduated in 1993, and after a postdoc at the Carnegie Institute at
Pasadena, then at UC Berkeley, he is now at William and Mary.� Istvan Szapudi graduated in 1994, and after a
postdoc at Fermilab, then at Durham, he is moving to CITA, Toronto. Mark
SubbaRao graduated in 1996, and is now at the University of Chicago. Robert
Brunner graduated in 1997, and currently is a postdoc at Caltech.
Results from Prior NSF Support by Michael T.
Goodrich
Michael T. Goodrich has received
prior NSF support from the following grants:
� CCR-9300079, �Constructing, Maintaining, and Searching Geometric Structures� (PI: Michael T. Goodrich), August 27, 1993 � August 26, 1996, $134,976.
� CCR-9625289, �Application-Motivated Geometric Algorithm Design� (PI: Michael T. Goodrich), August 15, 1996 � August 14, 1998, $107,389.
These projects were directed at the design of geometric data structures and algorithms for fundamental computational geometry problems and geometric problems that are motivated from applications in other research domains. The main results of these projects were for problems arising in geometric modeling, approximation, and visualization; geometric information retrieval; and large-scale geometric computing.
Geometric modeling,
approximation, and visualization.
Research in this area is focused
on the design of methods for taking a set of objects that have some pre-defined
geometric or topological relationships and producing a geometric structure that
concisely represents these relationships. For example, in the classic convex
hull problem the input is a set of points and the relationship is based upon
convex combinations of these points. Other examples include problems arising in
the fast-growing area of graph drawing. Often, the main difficulty in solving
such a problem is in producing a geometric model efficiently and
concisely�efficiently in terms of the running time needed to produced the model
and concisely either in terms of its combinatorial structure or in terms of the
volume of space that it occupies. We have therefore concentrated our efforts on
these challenging aspects of geometric modeling, approximation, and
visualization. For example, we have designed efficient graph drawing methods
for producing small geometric representations of trees, planar graphs, or partially-ordered
sets, using methods that have provably optimal running times. We have also
developed methods for quickly finding concise piecewise-linear functional
representations of 2-dimensional point sets and 3-dimensional convex polytopes.
Our 2-dimensional result finds the best k-link functional approximation in O(n
log n)� time, which is optimal and
improves the previous quadratic-time methods, and our 3-dimensional result
quickly finds a convex approximation whose number of facets is within a
constant factor of the optimal value (the general problem is believed to be
NP-hard), and improves the previous� O(
log n)� approximation factor. Actually,
our algorithm for 3-dimensional convex polytopes applies to any situation that
has a constant combinatorial �dimension� known as the VC-dimension. Finally, we have given what we conjecture is an
asymptotically optimal method for constructing a snap-rounded segment
arrangement in the plane.
Geometric information retrieval.
Producing a geometric model or model approximation is often a preprocessing step to a process that performs queries for that model. Alternatively, we may wish to maintain a geometric structure dynamically, subject to on-line update and query operations. Thus, in addition to methods for constructing or approximating geometric structures, we have studied methods for performing information retrieval on geometric structures, in both static and dynamic environments. In the static framework we studied the problem of retrieving all matches between a pattern set of points, P, and a database �text� set of points, T, under Euclidean motions, both in terms of finding optimal matches and also in terms of quickly finding approximate matches. This problem has applications, for example, in computer vision. We have also studied several tolerancing problems motivated from computational metrology, including approximate and exact algorithms for testing flatness and roundness of 3-dimensional point sets, and for tolerancing convex polygons in the plane.
In the dynamic framework we have studied the problem of maintaining a planar subdivision, subject to edge insertion and deletion, as well as point location and ray-shooting queries. Our methods in these cases achieve running times for update and query operations that are polylogarithmic and are the current best times for dynamically solving these queries. We also give methods for point locations that can adapt over time to the distribution of queries and in some cases do better than logarithmic time.
Large-scale geometric computing.
As geometric problems grow larger traditional methods for solving them no longer apply, either because the problem is too large to fit into main memory or because the problem is too large to be efficiently solved by a single processor. Thus, a fundamental component of our efforts was directed at large-scale geometric computing. For example, we developed several general parallel algorithmic techniques and we designed the first provably-optimal parallel methods for a host of fundamental computational geometry problems, including Voronoi diagram construction, polygon triangulation, convex hull construction (both in the plane and in higher dimensions), hidden-line elimination, segment intersection, and fixed-dimensional linear programming. Our methods are optimal in terms of their running times and the total amount of work they perform, even for problems that can have variable output sizes. Many of the techniques we developed, such as cascading divide-and-conquer, parallel plane sweeping, and parallel epsilon-net construction, are fairly general and applicable to a wide-variety of problems.
Still, these techniques do not directly apply to situations where one wishes to solve a very large problem on a single computer whose internal memory is too small to contain the entire problem instance. We therefore initiated pioneering work on external-memory algorithms for computational geometry, as well graph searching and graph traversal procedures that arise in geometric contexts. We have also developed external-memory data structures, such as the topology B-tree, which has applications to dynamic closest pair maintenance and approximate nearest-neighbor searching.
We believe we have therefore performed a coherent research program for geometric algorithm design. We have solved a number of previously unsolved problems and we initiated a number of promising new research areas, including external-memory computational geometry.
Human and Educational Resources Impact.
The support from these grants provided for partial support for a graduate student. By leveraging this support with other grant support and teaching-assistantship support, we were able to support the work of several graduate students, and our joint research efforts have resulted in several research publications co-authored with the PI�s Ph.D. students, Paul Tanenbaum, Kumar Ramaiyer, and Mark Orletsky. These grants also provided travel support, which allowed the PI to collaborate with Ph.D. students studying at other universities, including Ashim Garg at Brown Univ., Herv� Bronnimann at Princeton Univ., Mark Nodine at Brown Univ., Dina Kravets at M. I. T., Nancy Amato and Edgar Ramos at Univ. of Illinois at Urbana-Champaign, Yi-Jen Chiang at Brown Univ., and Darren Vengroff at Duke Univ. Thus, although the student support in these grants was fairly modest, it nevertheless had a significant impact upon the educational opportunities of a large number of Ph.D. students, some of which are members of minority or gender groups currently under-represented in computer science. In addition, we have collaborated with students at Brown and Johns Hopkins to develop the GeomNet system for geometric algorithm demonstration, which is useful for teaching computational geometry.
Results from Prior NSF Support by Ethan T. Vishniac
AST9020757: - �The Formation of Structure in the Universe� $225,000 (9/1/91 through 8/31/95)
This contract was granted through the Extragalactic Astronomy Division of NSF and was primarily used to support work in cosmology, including work on shape recognition.�� However, it also supported ongoing work on shock waves.
Yi and E.T. Vishniac studied the evolution of cosmological density fluctuations during an early inflationary epoch by approximating the fully quantum mechanical field evolution of the local energy density using a semi-classical stochastic evolution equation.
This approach allowed us to evaluate the distribution of fluctuations as a function of scale for a wide variety of inflationary models.� The main focus of our work was the nature of the distribution functions obtained in way and the extent to which they could be distinguished from a purely gaussian distribution of fluctuations.� We found that even when nonlinear effects were important in the evolution of the inflaton field, deviations from gaussian statistics were very small on all observable scales.� Specific models that violated this rule could be found, but they were invariably those models that produced strong features in the perturbation power spectrum at observable scales.� Our basic conclusion was that scale-invariance and gaussian fluctuation statistics are linked in the sense that they both hold, or are both violated.� We also examined the implications of this approach for chaotic inflation and found that a large fraction of the phase space of initial conditions at the Planck epoch leads to successful inflation, although the boundaries of this region can be quite different from those obtained in a purely classical analysis.
E.T. Vishniac continued work on the stability of hydrodynamic shock waves.� Previous work along this line (mostly in collaboration with D. Ryu) had focused on a linear instability that sets in when a decelerating shock has a strong density contrast relative to the external medium (i.e. a density ratio of 14 or more).� In subsequent work we examined the stability of shock bounded slabs with large density contrasts which do not satisfy the conditions for linear instability, either because there is no significant thermal support on the trailing surface, or because the slab is stationary.� We developed an approximate treatment of nonlinear effects and showed that nonlinear instabilities set in whenever cooling is important, unless the slab is stationary and bounded on one side by a shock and on the other by an equivalent thermal pressure.� Our results for a stationary slab confined on both sides by shocks are consistent with previously unexplained numerical results (Hunter et al. 1986; Stevens et al. 1992).� We also predicted a new family of nonlinear instabilities for accelerating or decelerating slabs bounded by at least one shock and free of any significant external thermal pressure.� These results indicated that cooling shocks are a strong source of vorticity.� These instabilities are likely to be important for star formation and dynamos in cold molecular clouds as well as for galaxy formation in pancake models of structure formation.
This grant also supported work by R.C. Duncan on quasar absorption lines and the �Ly-alpha forest.�� In collaboration with J. Bechtold (Univ. of Arizona), A. Crotts and Y. Fang (Columbia Univ.), he obtained spectra of the 9.5� binary quasar Q1343+264.�� These observations put very strong constraints on the size and velocity structure of the Ly-alpha forest absorbers.� Remarkably, all of the most popular and well-known models of the Ly-alpha clouds are excluded by these data with stronger than 99% confidence; in particular, they falsify pressure-confined and/or freely-expanding cloud models, in which the absorbers formed in a significantly more compressed state at redshift z>>2, as well as models in which the hydrogen is stably confined by �mini-halos� of cold dark matter.� This led us to consider a class of scenarios in which the Ly-alpha forest absorbers at z� 2 are dynamically collapsing gas concentrations, many or most of which are fated to form dwarf galaxies.� [Since the completion of this work this point of view has become the consensus within the field.]
S. Luo and E.T. Vishniac explored new methods of evaluating the shape and amplitude of large scale structures in the universe.� The basic thrust of this work is to combine earlier work (Vishniac 1986) on shape statistics with a Bayesian approach to estimating the significance of clustering.� Our first work was a reanalysis of the significance of the periodicity in the Broadhurst et al. sample (Broadhurst et al., 1990). The result was that the hypothesis that the peak in the power spectrum was intrinsic to the primordial spectrum was favored by roughly a factor of about a hundred over the null hypothesis.� However, a general enhancement of the large scale power was only disfavored by a factor of roughly ten to twenty.� Subsequently, we concentrated on producing a set of shape statistics which can be used to produce information roughly complementary to the usual two point correlation function analysis.� There are a number of candidate statistics, however we concentrated on statistics defined by low order moments of the distribution in a sampling window, since these seem to produce the strongest signal for a wide range of sample distributions.� In separate papers we described our methodology, and applied this work to computer simulations of structure formation and galaxy catalogs.� The statistic was shown to be a robust measure of structure in the computer simulations.� Comparison with actual catalogs from the southern and northern hemispheres showed significantly different structure, suggesting that neither represent statistically fair samples of the universe, either because of intrinsic differences or because the available catalogs were affected by different selection problems.
4. Dissemination of Results and Institutional Commitment
Dissemination
of Results
���� We will maintain a WWW site at JHU,
containing all the relevant documents, technical drawings, publicly available
software, contents of talks at conferences, electronic presentations. We will
put demos on the WWW, as soon as possible. We will aggressively give talks
about our results at various meetings, in all the three subject areas:
astronomy meetings, particle physics meeting and in computer science
conferences. We are currently preparing several papers for the SIGMOD 2000
Conference. We will have two Project Meetings every year, at alternating
locations, where the participants will give short presentations about their
progress to the Collaboration. On these meetings we will make further plans on
which conferences to target for the next year, and coordinate the publication
effort. We will make the software we create publicly available, through the
project website. This will include the middleware for the Query Agents, the
spatial index for the sky/earth, and various other class libraries.
Data
Center Resources Available in 1999/2000
|
Site |
CPUs |
Mass Storage
Management Software |
Disk Cache |
Robotic Tape
Storage |
Network
Connections |
Network Access
Speeds |
|
Fermilab |
128 CPU |
HPSS |
1 TB |
10 TB |
ESnet |
OC-12 |
|
JHU |
48 CPU Intel |
N/A |
0.7 Tbyte |
N/A |
VBNS |
OC-3 |
|
Caltech |
256 CPU Exemplar ~0.1 TIPS |
HPSS |
1.5 TByte |
~300 TBytes |
NTON CalREN-2 |
OC12-(OC48) |
Additional
resources
���� Through the Intel Technology
for Education 2000, T4E2K the JHU participants have been awarded approximately
$700K from Intel so far, mostly in terms of computers, to Goodrich and Szalay.
According to the support letter from George Bourianoff, should this proposal
succeed, it is likely that our group will receive further support from Intel,
beyond the current commitment. There is a large computer room available for the
distributed system, in the Bloomberg Center for Physics and Astronomy, with
sufficient growth space for a much larger cluster. There are already 2 highly
trained professionals, Peter Kunszt and Ani Thakar, both Associate Research
Scientists already working on the prototype system, they would be involved in
our research effort. Two computer science graduate students are currently
working with us on the spatial indexing, and we expect one new graduate student
starting this fall. They are all supervised jointly by Goodrich and Szalay. JHU
contributes to 30% of a systems support person, who is responsible for both the
workstations involved and the database cluster. There� is a separate networking hub in the
Department of Physics and Astronomy for our group, linked directly with
Goodrich's group on an ATM OC-3 backbone, sitting directly on the outgoing VBNS
router.
Stephen Wolff, Executive Director, Advanced Internet Initiative Division, Cisco, expressed an interest in supporting our activities, and we hope he will be able to make a commitment shortly.
5. Performance Goals, Milestones
Year 1:
Alternate database experiments
Build alternative versions of the SDSS archive, using SQL Server
Determine if and how GIOD/Objectivity data can be migrated into Oracle 8 and Jasmine
Milestone: May 2000 - complete conversion of
Objectivity system
����
LAN tests of the ODBMS
Develop network, server and client load monitoring tools to measure instantaneous features of multi-client ODBMS access, and extend LAN/ATM reconstruction tests to <16<=240 clients
������� Milestone:
July 2000 - complete measurements for <= 240 clients
WAN tests of the ODBMS
Repeat LAN tests above, but over WAN links, set up GIOD databases replicas with Data Replication Option at remote sites, measure physics task (reconstruction, analysis, event viewing) behaviour with replicas as they receive replica data from the WAN
������ Milestone:
September 2000 - complete WAN measurements for <= 240 clients
���� Advanced Data Structures
��������� Release production version of the spatial index
Milestone: December 2000 -Finish detailed documentation, release
software
Start design of alternate distributed server layouts (river machine, hash machine)
Year 2:
���� Simulator Package:
��������� Use measured LAN/WAN
data from tests above as input to model of favoured distributed system
������� configurations. Use tool to
predict global system response, determine bottlenecks, maximum query rate
����� ��� Milestone 1: December 2000 - Simulate LAN
measurements, and demonstrate that simulation can successfully extrapolated
from N to 2N clients
��������� �������� Milestone
2: July 2001 - As above, using WAN results
���� Query Agent Middleware:
��������� Create prototype version of the middleware for the distributed Query Agents
Milestone 1: December 2000 -Finish detailed specifications, and coarse
grained design
Milestone 2: July 2001 - Finish first tentative implementation
����
���� Advanced Data Structures
��������� Release production version of the spatial index
Build alternate distributed server layouts (river machine, hash machine)
Milestone: December 2000 -Finish detailed documentation, release
software,
first version of guidelines document
Year 3:
���� Advanced data structures
Create tool for automatically finding optimal data clustering for different types of data, and interface it to the query agent middleware
Milestone: December 2001 - Publish algorithm, design class library
Milestone : July 2002 - Finish detailed guidelines document
Milestone : September 2002 - Release package
���� Query Agent Middleware:
��������� Finalize middleware for the distributed Query Agents
Milestone : July 2002 - Release package and documentation
6. Management Plan
� The PI, Alex Szalay is responsible for coordinating the overall management of the project. Mike Goodrich will coordinate the JHU activities. The Caltech CoI, Harvey Newman is the coordinator of the Caltech effort, and Tom Nash will be responsible for the Fermilab activities.
� The project will have monthly meetings by video and teleconferencing. We have the necessary infrastructure for videoconferencing at all sites, and have been routinely doing this over the course of the last two years, anyway. There will be person-to-person project meetings twice a year, alternating between the different sites, beginning with JHU, then Caltech. Our industrial collaborators will also be invited to these meetings.
� At each Project meeting we will review the milestones. At the end of each funding year we prepare a yearly report on our activities, addressing in the detail the milestones reached, publications, talks and other deliverables. The report will be sent to both the NSF and to our industrial partners.
� We will maintain a Web site for the project, managed by JHU, containing all project documents, results and publicity material. As discussed in the Objectivity support letter, we will get a special licence for Objectivity, and we will create a publicly accessible demo site to submit queries into our distributed system.
� As part of the startup activities, we will rapidly advertise the postdoctoral and programmer positions, and try to fill these as quickly as possible. Szalay will spend a month at Caltech in early 2000, to accelerate the collaboration. His visit to Caltech will be targeted at addressing the inter-field issues (merging the query agent technology with the WAN-distributed databases).
7. Letters of Cooperation/Commitment
Attached below, we have letters of collaboration and/or commitment from:
Jim Gray, Microsoft
George Bourianoff, Intel
Ron Raffensberger, Objectivity
|
Microsoft ��� |
|
14 May
1999 Dr. James
N. Gray Senior
Researcher Microsoft
Research Laboratory 301Howard
St., 8th fl. San
Francisco, CA. 94105 415-778-8222
(fax:-8210) http://Research.Microsoft.com/~Gray |
Dr. Alex Szalay
Professor
Department of Physics and Astronomy,
The Johns Hopkins University
�3701 San Martin Drive
Baltimore, MD 21218
Dear Dr. Szalay:
This is to confirm my intention to collaborate with you on the research
about distributed databases, in particular on the Sloan Digital Sky Survey
Archive research project, we are proposing to the National Science Foundation's
KDI program. My research focus will be on the use of COTS hardware and software
arrays to build data mining tools for astronomers.� I will also consult with the team on software
design issues.� Microsoft will cover my
salary and expenses as a regular part of my research duties.� I look forward to collaborating with you on
this.
�
Very truly yours,
 Dr. James N. Gray
Dr. James N. Gray
Senior Researcher
�
May 14, 1999
Professor Alex Szalay
Johns Hopkins University
3701 San Martin Drive
Baltimore, MD� 21218
Dear Professor Szalay,
Intel Corporation understands that Johns Hopkins University has submitted a proposal to NSF as part of the KDI initiative dealing with the design and operation of multi-terabyte distributed data archives of astronomical data.�� This archive will be unique in that it will be in the public domain and must be accessible to a very wide range of users interested in extracting many different types of information.� The scale of the data management and retrieval problem exceeds anything that has been attempted up to the present time.�
Intel feels that this program will have a profound impact on the way astronomy and other scientific enquires are conducted.� Creating a central database that contains the sum of all human knowledge and the tools to efficiently extract knowledge from the information will enable rapid progress in areas where data gathering and data analysis can be separated.
Intel intends to track this work closely and will look for appropriate ways in which we support the effort.
Sincerely yours,
George Bourianoff, PhD
Technology for Education 2000 Program Manager

Mr. Alex
Szalay
Johns
Hopkins University
Baltimore,
MD 21218
Dear Alex:
Objectivity is
pleased to be able to offer support for the proposal titled "Accessing
Large Distributed Archives in Astronomy and Particle Physics".� Objectivity support will take the following
form:
-
Direct
access to a designated member of our development team for advice and support
for� applications which will involve
Objectivity's distributed architecture.
-
A
special license to allow limited access via the web for the testbed
applications.� This license will be
negotiated as a part of our "Built on Objectivity" program.
We will also
provide access to our product development planning process so that special
consideration is given to requests for product modifications which might
enhance the applications being developed for this proposal.
The exact
details of these actions will be determined after award of the project.� We are excited to be involved in this
important work.
Sincerely,
Ronald W. Raffensperger
Vice President, Marketing