Use Case “Test Bed” for the Particle Physics Data Grid - J.J.Bunn, March 1999
We describe a testable
scenario for accomplishing physics data analysis tasks in the framework of the
proposed Particle Physics Data Grid.
The computing
infrastructure that is already deployed in the collaborating laboratories and
institutes includes:
·
Large aggregates of
CPU servers of a variety of types
·
Tape robots and
jukeboxes of capacity measured in Tbytes
·
Storage management
software, such as 3rd party products like HPSS, and in-house
packages like SAM
·
High speed regional
networks such as MREN and CalREN2
·
High speed LANs such
as Gigabit Ethernet
This is the
infrastructure which we intend to leverage in the Test Bed system described
below.
The available physics
data comes from a variety of experiments:
·
ATLAS test beam
data: several hundreds of Gbytes of raw data, with several tens of Gbytes
“nTuple” data in PAW format
·
CMS simulated data
from GIOD: roughly 100 Gbytes of Objectivity database files
·
And others I’ve
missed ….
PPDG Test Bed – System Infrastructure
In the proposed project, we wish to deploy a Test Bed which can be used by physicists as a powerful and convenient infrastructure for executing analysis tasks on the data.
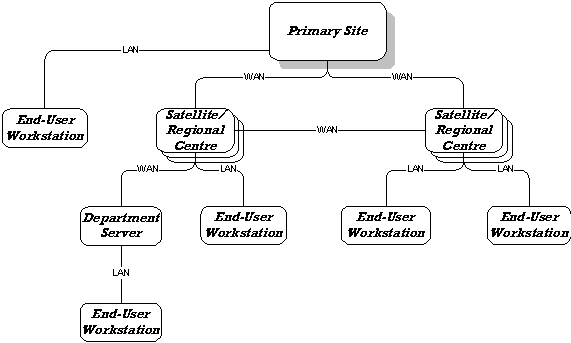
Figure 1: Showing the network architecture
of the Test Bed
The architecture of the
Test Bed can be envisaged as a tree structure (see Figure 1) with the primary
node being the location of the primary store of data (typically at the
laboratory where the experiment is taking or took data), and the leaf nodes
being end-users’ workstations. Intermediate nodes in the tree correspond to
“Regional” (or “Satellite”) data centres, and Department servers. The
workstations are LAN-connected devices located at the Primary Site, a Regional
centre, or in a physics department at a collaborating institute. The Regional
centres and the Primary site are interconnected via high speed WAN links.
The major unit of
transfer in the system is a file. The file typically contains binary event
data: it is a few hundred Mbytes in size for the datasets we propose using. The
file may be an Objectivity Database file, or a Zebra FZ file. Inter-centre
transfer speeds in the WAN of such files will take a few seconds at OC3 (155
Mbits/sec): just over the limit of acceptable response for interactivity. We thus
prefer to execute queries close to the data, depending on the tradeoff between
available processing power and this transfer latency.
In the system, end-users
will be issuing selection queries about the available data. How the query is
formulated, and how it gets parsed, is defined and controlled by the analysis
tool being used. The particular tools we have in mind are custom applications
built with Objectivity/DB, or PAW commands/macros, or ROOT commands, or JAS
with an appropriate Data Interface Module. A typical query (in meta-language)
might be: “Select all events with two photons each with PT of at least 1 GeV, and return a histogram of
the invariant mass of the pair”. The analysis tool will typically need
to obtain from a catalogue a list of “available” data files, and match these
with a list of required data files. By “available” we mean located somewhere in
the system.
The Test Bed system will
eventually allow the use of any of the analysis tools mentioned, although
intially we will target Objectivity applications and PAW macros(?). This will
be made possible by the development of middleware
into which the chosen analysis tool is inserted.
PPDG Middleware – Agents,
The middleware is built
both from components that already exist in our collaboration, and from an
enabling software/network layer based on Autonomous Agents. The middleware is a
software and data “jacket” that:
·
encapsulates the
analysis tool,
·
has topological
knowledge of the system
·
is aware of
prevailing conditions of the systems’ components
·
uses tried and
trusted vehicles for query diistribution and execution such as Condor, Globus
etc. etc. (I need to be more specific here).
We propose to use Agent
technology (in particular the “Aglets” toolkit from IBM [ref.]) to glue the
middleware components together as a networked system. Agents are small entities
that carry code, data and rules in the network. They move on an itinerary
between Agent servers that are located in the system. The Primary site, all the
Regional centres and the Department systems run Agent servers. The servers
maintain a catalogue of locally (LAN) available files and a cache of recently
executed query results.
For each query, an Agent
is created in the most proximate Agent server in the Test Bed system, on behalf
of the user. The Agent intercepts the query, generates from it a set of
required data files, decides where the query should execute, and then
despatches the query accordingly. It starts by internal communication with the
analysis tool, as a proxy agent for the end user, and does the following
·
Determines the list
of files required to satisfy this query
·
For each file i in the list:
·
If the file is
locally available:
·
evaluates the access
cost function, Ai
·
evaluates the
processing cost function, PI
·
If the file is not
locally available, marks it as such
·
Stores the cost
functions
·
Evaluates local cost
for the query, as ∑ Pi
Ai
(Developing a suitable
access cost function, A, is one goal of this research. Clearly, it needs to
take into account the speed of the media on which the file is stored, its
latency and so on. Likewise the processing cost function, P, will take into
account system load and other prevailing conditions on the machines in the
system.)
If all the required files
are available on the local system, the Agent simply executes the query, and
encapsulates the results in a suitable format (we suggest using XML as a
platform independent data description language). These results are immediately
retrievable by the end user. They are also cached in the proximate Agent
server.
If one or more of the
required files is not available locally (which will normally be the case), then
the Agent is despatched on an itinerary that includes all the Agent servers in
the system. On arrival at each Server, the Agent evaluates the cost functions
for the files it requires, adds these to a list, and moves on to the next
Server. Eventually it arrives back at its birthplace. At this point it can
suggest whether it is best to despatch the user’s query to one or more remote
servers, or whether the required data files should be transferred across the
network to the local machine and executed there. This information is made
available to the end user, who must then decide what is to be done. (Making
this decision automatic is another goal of the research.)
There are two possible
outcomes: either the query must be executed locally, or it must be executed (at
least in part) remotely. In either case the locations of the required files are
known. If files need to be transferred from one system to another before the
query can execute, then this process will be managed by separate “file mover”
Agents, who travel to the target system Server and invoke FTP (or whatever),
and then perhaps a subsequent step such as an “ooattachdb” for an Objectivity
database. The file mover Agents must all return to the proximate Server before
the query can start (or maybe not: perhaps some concurrency will be possible).
This is a very simple
scheme which is robust against network congestion or outages. At any moment,
the end user can interrogate the status of the Agent’s results, its position on
the Server itinerary, and the prevailing conditions. The user can request that
the Agent terminate and return immediately at any time. Note that the Agent
does not (can not) move to a new Server if the network is unavailable to that
Server: in these cases it can select a different one from its itinerary.
Timeouts would eventually force the Agent to return to its birthplace in the
case of extreme network congestion. One other advantage of the scheme is that
it lends itself very well to unattended (or “batch”) execution, since the end
user does not need to interact with the Agent. Even when the Agent has
completed executing the query on the user’s behalf, the results are stored in
XML form on the proximate Server for later perusal. (The user query result
cache in each Server should mark un-read result files against purge out of the
cache.)