Software |
||
| PPDG Middleware | 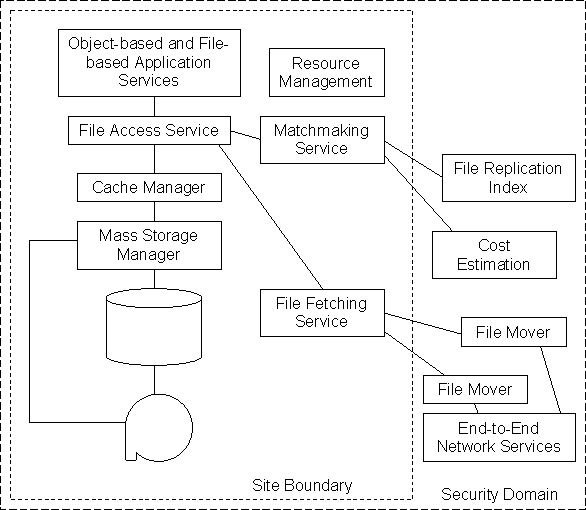 |
|
| PPDG System Overview | 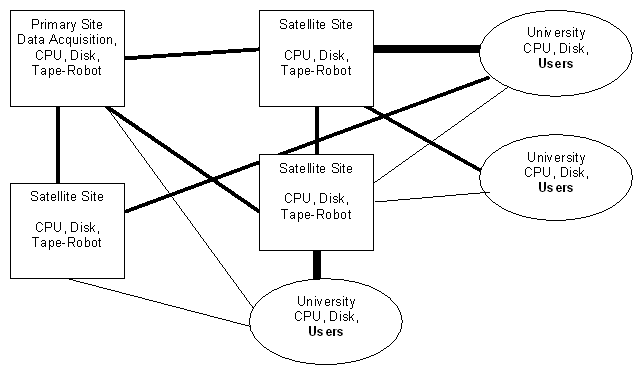 |
|
| PPDG Use Case Idea | ||
Hardware |
||
| GIOD Testbed | 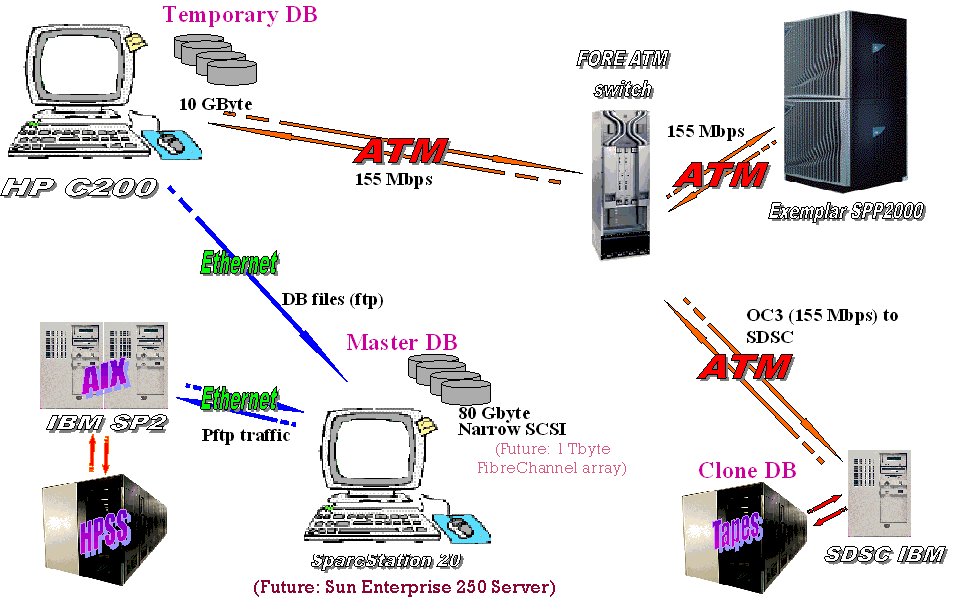 |
|
Networks |
LAN Connectivity in CACR | 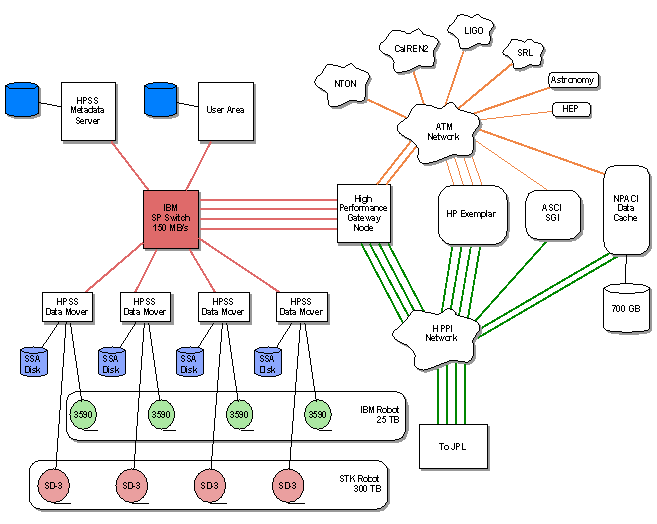 |
| WAN Connectivity to CACR | 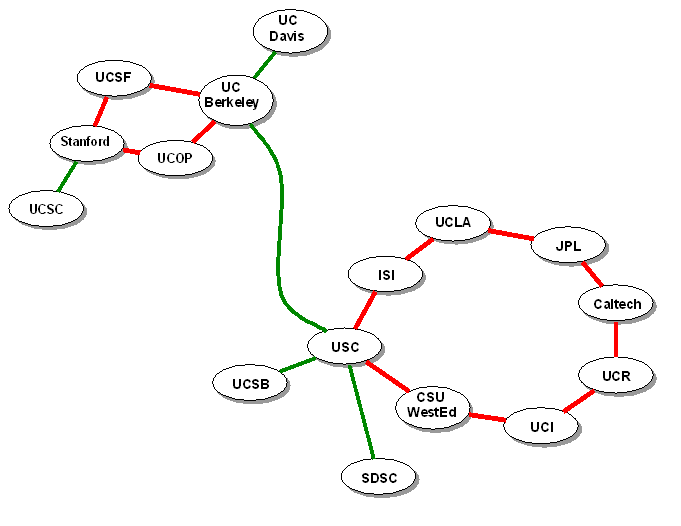 |
|
| PPDG Network Diagram | 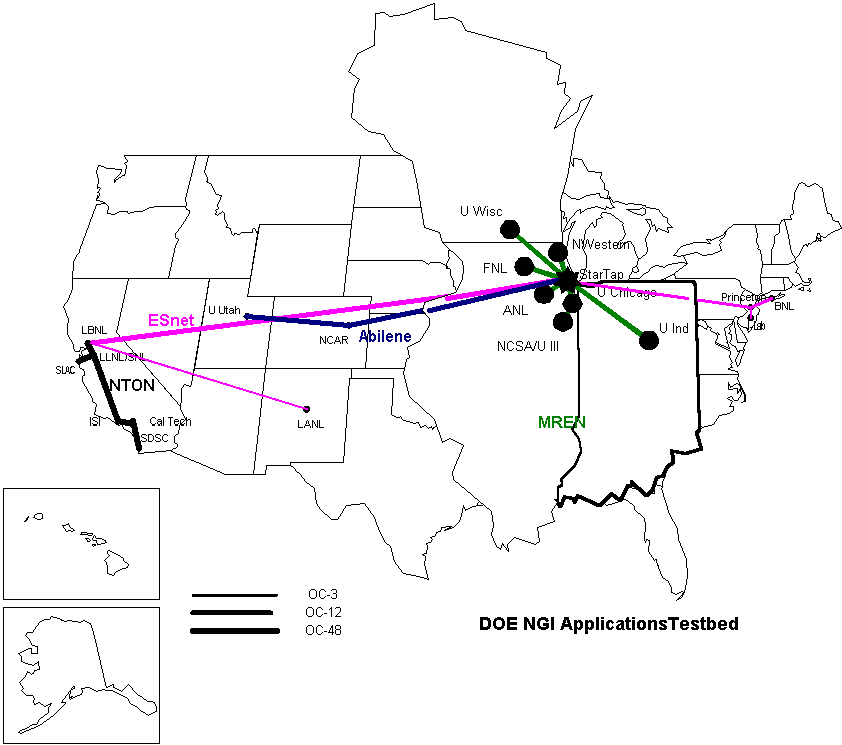 |
| Project Name | Particle Physics Data Grid | ||||||||||||||
| Application Description | |||||||||||||||
| PI's | |||||||||||||||
| Sites Involved |
|
||||||||||||||
| Networks Used | ESnet, NTON, Abilene | ||||||||||||||
| Bandwidth Requirements | |||||||||||||||
| Latency Requirements | |||||||||||||||
| QOS Requirments (bandwidth, jitter, etc.) | |||||||||||||||
| Other (multicast? multiple streams? etc) | |||||||||||||||
| Systems used and their locations (e.g.: HPSS, T3E, PC cluster, Cave, etc.) |
|
||||||||||||||
| WAN POP Contact (1 per site) | |||||||||||||||
| LAN Contact (1 per site) | |||||||||||||||
| Application contact (persons responisible for making the applications work well in an NGI enviromnent) |
Software |
||
| PPDG Middleware | |
|
| PPDG System Overview | |
|
| PPDG Use Case Idea | ||
Hardware |
||
| GIOD Testbed | |
|
Networks |
LAN Connectivity in CACR | |
| WAN Connectivity to CACR | |
|
| PPDG Network Diagram | |
The Particle Physics Data Grid has two long-term objectives. Firstly the delivery of an infrastructure for very widely distributed analysis of particle physics data at multi-petabyte scales by hundreds to thousands of physicists and secondly the acceleration of the development of network and middleware infrastructure aimed broadly at data-intensive collaborative science.
The specific research will design, develop, and deploy a network and middleware infrastructure capable of supporting data analysis and data flow patterns common to the many particle physics experiments represented among the proposers. Application-specific software will be adapted to operate in this wide-area environment and to exploit this infrastructure. The result of these collaborative efforts will be the instantiation and delivery of an operating infrastructure for distributed data analysis by participating physics experiments. While the architecture must address the needs of particle physics, its components will be designed from the outset for applicability to any discipline with large-scale distributed data needs.
Among the hypotheses to be tested are these:
The experimental high energy physics program at Caltech began with the construction of
the Caltech Electron Synchrotron, built and used by R. Bacher, M. Sands, R. Walker and A.
Tollestrup. Now Caltech, like other university groups, performs its research through
participation in large experiments on major facilities away from the campus.
The Caltech administration has traditionally given strong support to the high energy
program, and within physics, activities in astrophysics and fundamental particle physics
have had the highest priority. Institutional support has been given in the form of faculty
appointments, special grants for developing or purchasing equipment, start-up funds for
new faculty, funds for visitors, flexible teaching arrangements, special support for
postdoctoral fellows, substantial support for computing, an upgrade of our electronics
shop, forward financing for equipment projects, etc.
The HEP experimental program is made up of an active group of faculty, a strong post-doctoral research staff and a number of very bright graduate students. The experimental activities consist of a mix of productive ongoing physics, plus significant effort toward future upgrades or new projects. The ongoing program is centered on detectors at Beijing, CERN, Cornell, and the Gran Sasso. In addition, the department is deeply involved in the SLAC B factory detector, plus other activities toward future experiments.
The GIOD project, a joint effort between Caltech, CERN and Hewlett Packard Corporation, has been investigating the use of WAN-distributed Object Database and Mass Storage systems for use in the next generation of particle physics experiments. In the Project, we have been building a prototype system in order to test, validate and develop the strategies and mechanisms that will make construction of these massive distributed systems possible.
We have adopted several key technologies that seem likely to play significant roles in the LHC computing systems: OO software (C++ and Java), commercial OO database management systems (ODBMS) (Objectivity/DB), hierarchical storage management systems (HPSS) and fast networks (ATM LAN and OC12 regional links). We are building a large (~1 Terabyte) Object database containing ~1,000,000 fully simulated LHC events, and using this database in all our tests. We have investigated scalability and clustering issues in order to understand the performance of the database for physics analysis. These tests included making replicas of portions of the database, by moving objects in the WAN, executing analysis and reconstruction tasks on servers that are remote from the database, and exploring schemes for speeding up the selection of small sub-samples of events. The tests touch on the challenging problem of deploying a multi-petabyte object database for physics analysis.
So far, the results have been most promising. For example, we have demonstrated excellent scalability of the ODBMS for up to 250 simultaneous clients, and reliable replication of objects across transatlantic links from CERN to Caltech. In addition, we have developed portable physics analysis tools that operate with the database, such as a Java3D event viewer. Such tools are powerful indicators that the planned systems can be made to work.
Future GIOD work includes deployment and tests of terabyte-scale databases at a few US universities and laboratories participating in the LHC program. In addition to providing a source of simulated events for evaluation of the design and discovery potential of the CMS experiment, the distributed system of object databases will be used to explore and develop effective strategies for distributed data access and analysis at the LHC. These tests are foreseen to use local, regional (CalREN-2) and the I2 backbones nationally, to explore how the distributed system will work, and which strategies are most effective.
Center for Advanced Computing Research
CACR is dedicated to the pursuit of excellence in the field of high-performance computing, communication, and data engineering. Major activities include carrying out large-scale scientific and engineering applications on parallel supercomputers and coordinating collaborative research projects on high-speed network technologies, distributed computing and database methodologies, and related topics. CACR's goal is to help further the state-of-the-art in scientific computing.
Current Major Computational Resources at CACR