
This is a collection of various computational methods I have used in an attempt to get some understanding of the cipher used in the Voynich manuscript.
Supposing that Strong's conjecture about the structure of the VMs cipher is correct, we use a computational method to try to infer the alphabets and their sequence with the use of a large Latin diictionary.
Details are here.
Using a Java Media Framework MIDI application that processes the Voynich text, aach character is mapped to a note on the MIDI scale in a two octave range: Note = 48 + i mod 24
Each word is played as one or more chords of these notes, using the Grand Piano instrument.
If a gallows character ("h" or "k") appears in the word, then the notes preceding the gallows character are played as a chord, followed shortly by the notes after the gallows character, but shifted by either 1 octave ("h") or two octaves ("k"). If the character "9" appears as the last in the word, then the delay before playing the next word is reduced.
Using this method, here is what the common Voynich word "8am" sounds like: 8am
The word "okoe": okoe
The word "4ohc89": 4ohc89
And the complete Folio f1r (a long pause is taken after each paragraph on the folio): Folio f1r
And Folio f3r

More details here.
Comparing the phonetic content of various texts with VMs "words", using "Soundex" and "Double Metaphone"
For details, go here.
This study is based on the idea that the Voynich "Words" are in fact codes for parts of plaintext words. The Voynich symbol "9" is used to delimit the words. A Genetic Algorithm is used to explore the cipher, using a large body of common Latin phrases (as opposed to single words).
For details, go here.
For details, go here.
This study looks at the probabilities associated with glyph sequences in the VM. E.g. which is the most likely glyph to find at the beginning of a word in the herbal section?
For details, go here.
This investigation was inspired by Robert Teague's deciphering of e.g. f68r3.
For details, go here.
Extract:
For N=3, looking at the Herbal folios f1v-f20v inclusive, 1331 different words. Confirmed valid prefix/stem/suffix counts 99 252 111 Prefix/Stem/Suffix frequency, normalised 4ok 0.1010101 o89 0.05952381 o89 0.09009009 4oh 0.07070707 1oe 0.055555556 8am 0.09009009 1oe 0.060606062 4ok 0.055555556 1c9 0.054054055 1oh 0.04040404 8am 0.04761905 1oy 0.054054055 ok1 0.04040404 4oh 0.04761905 1oe 0.045045044 8oe 0.030303031 1oy 0.03968254 coe 0.036036037 1oy 0.030303031 1c9 0.031746034 cc9 0.027027028 1co 0.030303031 1co 0.023809524 e89 0.027027028 1ok 0.030303031 8oe 0.023809524 ham 0.027027028 4oj 0.030303031 coe 0.01984127 2c9 0.027027028
For more results, go here.
This is by no means an exhaustive list, but these are some of the Voynich sites/pages I have found useful, interesting and/or amusing.
Rene Zandbergen's site
Voynich Central
http://www.voynichcentral.com/
Elmar Vogt's blog
http://voynichthoughts.wordpress.com/
H.R. Santa Coloma's site
http://www.santa-coloma.net/voynich_drebbel/voynich.html
Philip Neal's webpages
http://voynichcentral.com/users/philipneal/
Jan Hurych's VM Letter Frequency Analysis
http://hurontaria.baf.cz/CVM/b2.htm
Voynich Transcription
http://voynichcentral.com/transcriptions/Voynich-101/index.html Edith Sherwood's site http://www.edithsherwood.com/voynich_botanical_plants/ This is a list of Latin herb names compiled from various sourceMy assumption in the work with Genetic Algorithms (GAs) is that the Voynich is a terse, compressed, abbreviated n-Gram conversion of the plaintext language. The scribe would have consulted a table of n-Grams while converting the Latin (or whatever) to the VM text, perhaps even writing the enciphered words out on a separate work sheet before copying them into the VM.
For example, assume the following extract from a set of possible n-Gram conversion rules (or "mappings") used by the scribe:
| Source n-Gram | Voynich n-Gram |
| pot | oc |
| he | c |
| is | 9 |
| h | f |
| s | 8 |
| y | a |
then, to convert the English word "hypothesis" to Voynichese, we do as follows:
h => f
y => a
pot => oc
he => c
s => 8
is => 9
so that "hypothesis" => "faocc89"
The inverse mapping can be used to decode the Voynich word (perhaps not unambiguously ...).
Clearly, there are a very large number of possible n-Gram mappings!
Go here to look at folio 27v, and see the various Genetic Algorithm attempts at deciphering the text.
Edith Sherwood has a web site where she details compelling possible identifications for the plants depicted in the "herbal" pages of the VM.
Dana Scott's page also has plausible identifications for the plants.
As has often been pointed out, if we look at the first Voynich "word" that appears on each page of the herbal part of the VM, we find that those words are unique, or appear elsewhere very rarely. It thus seems reasonable that the words may be the names of the plants depicted.
The GA was set up to find a set of n-Gram mappings that would convert a list of 111 Voynich first herbal words into Latin/English or Spanish. For this, dictionaries of Latin, English and Spanish herb/plant names were used.
The GA sought a mapping that would convert all the Voynich words for herbs/plants into as many valid plaintext (Spanish, English, Latin) words as possible. The best result was for a mixed English/Latin dictionary (see table): 31 of the 111 Voynich words were converted, about 30% success rate.
(One should never expect 100% success, due to missing names in the dictionary, transcription errors, missing n-Grams, incomplete n-Grams etc..)
The results are shown below in tabular form, together with Dana Scott's and Edith Sherwood's identification. The first column shows the folio in the VM, the second shows the first Voynich word on that folio. For the GA identification columns (3 and 4) the Voynich mapped word is shown, in quotation marks if not found in the associated dictionary, and in bold if found in the dictionary.
Note that, probably unsurprisingly, nowhere do the IDs from the GA in Spanish, English/Latin and Scott/Sherwood, agree! NOT YET, anyway :-)
(What amuses me about about this mapping technique is that it tends to produce words that sound plausible in the target language. E.g. for f4r the Latin/English word "paptise" sounds like a valid word.)
| Folio | Voynich 1st Word | Candidate GA ID, Spanish | Candidate GA ID, Latin/Engish | Dana Scott ID, English | Dana Scott ID, Latin | Sherwood ID, Latin | Sherwood ID, English |
| f1r | fa19s | costa | "greica" | ||||
| f1v | h1s9 | rabo | geum | Deadly Nightshade | Atropa belladonna Hyoscyamus niger Solanum nigrum Solanum dulcamara | Atropa belladonna | Deadly Nightshade |
| f2r | h98an9 | "jzba" | "ariapha" | Cornflower | Centaurea cyanus | Centaurea diffusa | Diffuse Knapweed |
| f2v | hoom | "meic" | "padi" | Water Lily | Nymphaea candida | Nymphoides | Nymphoides |
| f3r | k2cos | chinita (Impatiens) | arnica | Celosia argentea | Feathery amaranth | ||
| f3v | hoam | menta (mint) | paris | Helleborus foetidus | Dungwort | ||
| f4r | ho8ae19 | "mezirn" | "paptise" | Saxifraga cespitosa | Alpine Saxifrage | ||
| f4v | j1oom | pastora (Poinsettia) | "oigle" | Campanula rapunculus | Rampion | ||
| f5r | h2o89 | "piyn" | "hicse" | Arnica montana | Wolfs Bane | ||
| f5v | hA1coy | malanga (Malanga) | cirsium | Tennis Racket Plant | Agrimonia eupatoria | Malva sylvestris | Mallow |
| f6r | foay | "oote" | "erk" | Acanthus mollis | Bear Breeches | ||
| f6v | hoay9say1Chay | "meotendoteisedh" | "pakpikrtsst" | Eryngium maritimum | Sea Holly | ||
| f7r | f1o8am | "saynta" | acris | Trientalis europea | Starflower | ||
| f7v | joe29 | "rden" | anise | Myrica gale | Bog Myrtle | ||
| f8r | g2oe | "dno" | "miv" | Pisum sativum | Green Pea | ||
| f8v | Ko8 | "anop" | "amot" | Symphytum officinale | Comfrey | ||
| f9r | k98eo | "uardna" | "cernur" | Ricinus communis | Casteroil | ||
| f9v | fo1oy | "oveh" | "erut" | Heartsease, Wild Pansy | Viola tricolor | Violaceae | Viola |
| f10r | g1oK9 | "pohon" | "apryse" | Cichorium pumilum | Chicory Endive | ||
| f10v | gam | tora (Tora Tree) | gale | Linnaea borealis | Twinflower | ||
| f11r | k2oe | chino (Chinese Hat Plant) | "arv" | Rosmarinus officinalis | Rosemary | ||
| f11v | goe81o89 | "albaveaca" | "maadud" | Curcuma longa | Turmeric | ||
| f13r | koy3oy | "lenga" | "mdoium" | Banana | Banana | ||
| f13v | hoaiy | "memh" | "paft" | Lonicera periclymenum | Honeysuckles Woodbines | ||
| f14r | g1o8am | "poynta" | "apcris" | Scorzonera | Black Salsify Vipers Grass | ||
| f14v | g891om | "uomic" | "gesdi" | Stachys monnieri | Wood Betony Heal-all Sel-heal Woundwort | ||
| f15r | k2oy | "chiga" | "arium" | Sonchus oleraceus | Sow Thistles | ||
| f15v | gayoy | "t8h" | "gabt" | Paris quadrifolia | Herb Paris | ||
| f16r | go1co89 | "alblanyn" | "marscse" | Cannabis | Cannabis | ||
| f16v | g1yAm | "potoora" | "aptule" | Chrysanthemum | Chrysanthemum | ||
| f17r | f2o89 | "hayn" | "ulcse" | Catananche caerulea | Cupids Dart | ||
| f17v | g1o8oe | "poyno" | "apcv" | Dioscorea | Yams | ||
| f18r | g8yaz89 | "ullngn" | "gmeagse" | Aster alpinus | Aster | ||
| f18v | koe8 | la (?) | mad | Telfairia | Fluted pumpkin | ||
| f19r | g1oy | "poga" | apium | Polemonium coeruleum | Greek Valerian | ||
| f19v | go1am | "albbora" | mantle | Draba nivalis | Nailwort | ||
| f20r | h81o89 | "caveaca" | woud | Astragalus hypoglottis | Milk vetch | ||
| f20v | faIsay | "crrote" | greek | Cynara cardunculus | Cardoon | ||
| f21r | g1oy | "poga" | apium | Anagallis arvensis | Pimpernel | ||
| f21v | koe829 | "laol" | "madpe" | Dictamnus albus | Burning bush False Dittany White Dittany Gas Plant | ||
| f22r | goe | "albv" | "maus" | Verbena officinalis | Common Vervain Holy Herb | ||
| f22v | g9samoy | "..dah" | "hnshot" | Tulip | Tulip | ||
| f23r | g9818op | ".fhilo" | "hsthlo" | Pulsatilla vulgaris | Pasque flower | ||
| f23v | go8azoe | "albzucv" | "mapacus" | Borago officinalis | Borage Star Flower | ||
| f24r | goyoy9 | "alb.." | "maby" | Cucumis sativus | Cucumber | ||
| f24v | k1o8ay | coyote (wild) | rock | Ficus religiosa | Sacred Fig Bo Tree | ||
| f25r | f1oe89 | "sanoaca" | "avd" | Wild Thyme | |||
| f25v | goCam | "albcuora" | "malile" | Isatis tinctoria | Woad | ||
| f26r | g%coh9 | "spnij" | lunaria | Prunella vulgaris | Self heal | ||
| f26v | g1c8ay | pochote (Pochote) | "apgok" | Lens culinaris | Lentil | ||
| f27r | hsoy | manga (Mango) | "veium" | Spinacia oleracea | Spinach | ||
| f27v | fo1ou | oveja (?) | eruca | French Marigold | Tagetes patula | Dianthus superbus | Dianthus |
| f28r | g1o8ay | "poyote" | "apck" | Aristolochia | Smearwort Birthwort Pipevine | ||
| f28v | h2oe | pino (Pine) | "hiv" | Dahlia | Dahlia imperialis | Rhododendrons | Rhododendrons |
| f29r | gosam | "alb.ora" | "mansle" | Lactuva sativa longifolia | Romaine Cos Lettuce | ||
| f29v | hoom | "meic" | "padi" | Nigella sativa | Roman coriander | ||
| f30r | oh1cs9 | "elanbo" | "inrsum" | Prunella vulgaris | Healall | ||
| f30v | Ks1an | rubia (Madder) | montana | Cuscuta europaea | Dodder | ||
| f31r | hcc8c9 | lichi (Lychee) | "rgoio" | Erigeron acris | Fleabane | ||
| f31v | go8az | "albzon" | "mapnn" | Fernleaf yarrow | Achillea filipendulina | Valerian | Valerian |
| f32r | f1am | santa (?) | "aris" | Veronica triphyllos | Speedwell | ||
| f32v | h1co8am | "ranizora" | "genple" | Campanula rotundifolia | Harebell | ||
| f33r | k28ay | "chizh" | "arpt" | Silene vulgaris | Bladder Campion | ||
| f33v | kayay | "qllh" | "opmet" | Masterwort | Astrantia major | Tanacetum parthenium | Feverfew |
| f34r | g1cocj19 | "ponianos" | "apnbie" | Anemone hortensis | |||
| f34v | hs189 | "mansn" | "vewse" | Lunaria annua | Honesty Money Plant | ||
| f35r | Koo | anona (Custard Apple) | amur | Cichorium intybus | Radicchio | ||
| f35v | gay1oy | "trtga" | galium | Ribes nigrum | Blackcurrant | ||
| f36r | j1af8aN | "pa.nzti" | "onupfl" | Delphinium staphisagria | Delphinium | ||
| f36v | g1ayos9 | "pooteesn" | "apksise" | Lamium amplexicaule | Henbit | ||
| f37r | koGoe | "luiv" | malus | Mentha longifolia | Mint | ||
| f37v | h2o89 | "piyn" | "hicse" | fedtschenkoi englerii | Emilia fosbergii | Tassel flower | |
| f38r | koeoy | "lilh" | "mmut" | ||||
| f38v | oh1oj | "eveet" | inula | Euphorbia myrsinites | Myrtle Spurge | ||
| f39r | kc7o128 | "goguadp" | "gienmpot" | ||||
| f39v | g7aiy | "inmh" | "naft" | ||||
| f40r | g1c9 | "poi" | apio | Erodium malacoides | Storks bill | ||
| f40v | j1c7an | "pagmo" | "oospo" | Epiphyllum oxypetalum | Crocus vernus | Crocus | |
| f41r | j2c9hc8aecc9 | "roilizrii" | "ediorpcuio" | Origanum vulgare | Wild Marjoram | ||
| f41v | hcSo8ae | "lirbzv" | "riupus" | Coriandrum sativum | Coriander Cilantro | ||
| f42r | 2o | "ah" | st | ||||
| f42v | k1o˛ | cola (?) | rosa | Aquilegia vulgaris | Columbine Culverwort | ||
| f43r | kayo8am | "q.zora" | "opbple" | Stellaria media | Chickweed | ||
| f43v | g8saiy9 | "u.lbn" | "gnsicse" | Elytrigia repens | Couch grass | ||
| f44r | k2o8g9 | "chiy." | arch | Mandragora officinarum | Mandrake | ||
| f44v | k2o | china (Impatiens) | "arur" | Apium graveolens | Celery | ||
| f45r | g9h98ae | ".jzv" | "hariapus" | Atriplex hortensis | Orach Saltbush | ||
| f45v | hosay9 | "me.." | pansy | Lavandula angustifolia | Lavender | ||
| f46r | g1coJ9 | "ponitr" | "apnta" | Leucanthemum vulgare | Oxeye Daisy | ||
| f46v | jo79e3c7 | "rimvig" | "andretos" | Tanacetum parthenium, Chrysanthemum parthenium | Inula conyza | Ploughmans Spikenard Great Fleabane | |
| f47r | g1aiy | "pomh" | "apft" | Lady's Mantle, Lion's Foot | Alchemilla vulgaris Rosaceae | Sempervivum tectorum | Houseleek |
| f47v | g2cok | "dnier" | minor | Arnica montana | Pulmonaria officinalis | Lungwort | |
| f48r | g28am | "dzora" | "miple" | Adonis Vernalis | False Hellebore | ||
| f48v | g1co819 | "ponifn" | "apnsse" | Ruta graveolens | Rue Herb of Grace | ||
| f49r | gA2oe | "ceahv" | costus | Nymphaea caerulea | Blue Nile Lotus | ||
| f49v | g | he | wort | ||||
| f50r | g2coy | "dnih" | mint | Astrantia major | Masterwort | ||
| f50v | k19 | con (?) | rose | Telopea speciosissima | Gentiana frigida | Stiff Gentain | |
| f51r | k2oe819 | "chinofn" | "arvsse" | Cakile maritima | Searocket | ||
| f51v | go2o89 | albahaca (Basil) | "mastd" | Salva officinalis | Sage | ||
| f52r | k8oh1F9 | "queacn" | "toinnise" | Anemone coronaria | Poppy Anemone | ||
| f52v | g1oy | "poga" | apium | Polystichum setiferum | Fern | ||
| f53r | hA8ap | "mazlo" | "ciplo" | Achillea Ptarmica | Sneezewort | ||
| f53v | k2oy3c9 | "chigamin" | "ariumocse" | Hieracium aurantiacum | Hawkweed | ||
| f54r | go8am | "albzora" | maple | Cirsium oleraceum | Cabbage thistle | ||
| f54v | g1co8ay | "ponizh" | "apnpt" | Bittersweet Nightshade | Solanum dulcamara | Perovskia atriplicifolia | Russian Sage |
| f55r | go8am | "albzora" | maple | Fumaria officinalis | Fumitory | ||
| f55v | h1C8189 | "raecsn" | "geriwse" | Forest lily | Veltheima bracteata | Broccoli | Broccoli |
| f56r | ok1ae | "tebv" | "trntus" | Drosera | Sundews | ||
| f56v | h1cok | "ranier" | "genor" | Cycas revoluta | Sago Palm | ||
| f57r | joccoHc9 | "riopei" | "anomiaio" | Sherardia arvemsis | Blue Field Madder | ||
| f65r | Alchemilla vulgaris | Ladies Mantle | |||||
| f65v | Centaurea cyanus | Cornflower | |||||
| f66v | Satureja montana | Winter Savory | |||||
| f87r | Satureja hortensis | Summer Savory | |||||
| f87v | Senecio | Primula vulgaris | Primrose | ||||
| f87v | Kleinia | Pedicularis flammea | Lousewort Wood Bettony | ||||
| f89v | Actaea spicata | Baneberry | |||||
| f90r | Conyza bonariensis | Fleabane | |||||
| f90v | Eruca vesicaria | Arugula Rocket | |||||
| f93r | Cynara cardunculus | Artichoke | |||||
| f93v | Lupinus | Lupin | |||||
| f94r | Botrychium lunaria | Botrychium lunaria | Moonwort Moonfern | ||||
| f94v | Agrostemma Githago | Corncockle Red Campion | |||||
| f94v | Glycyrrhiza glabra | Liquorice | |||||
| f94v | Plantago lanceolata | Ribwort Plantain Kemps | |||||
| f95r | Berberis | Sambucus nigra | Elderberry | ||||
| f95v | Althaea Rosea | Hollyhock | |||||
| f96r | Angelica archangelica | Garden Angelica | |||||
| f96v | Tamus communis | Black Bryony |
See the section "Bibliography" at the end for the provenance of the various texts used.
Here is the ranking of the most popular words in each text (full tables are available in the Excel spreadsheet)
The 1/2/3/4 n-Grams are calculated as follows. Suppose the word "sesame" appears in the text. The following counts are made:
Then, each count is weighted by the length of the group, yielding s=2, e=2, a=1, m=1, se=2, es=2, sa=2, am=2, me=2, ses=3, etc. The counts are added to running sums for each distinct group found, and normalised at the end of processing.
| Comparison of most popular "words" | Comparison of most popular characters | Comparison of most popular 1/2/3/4 character
combinations |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
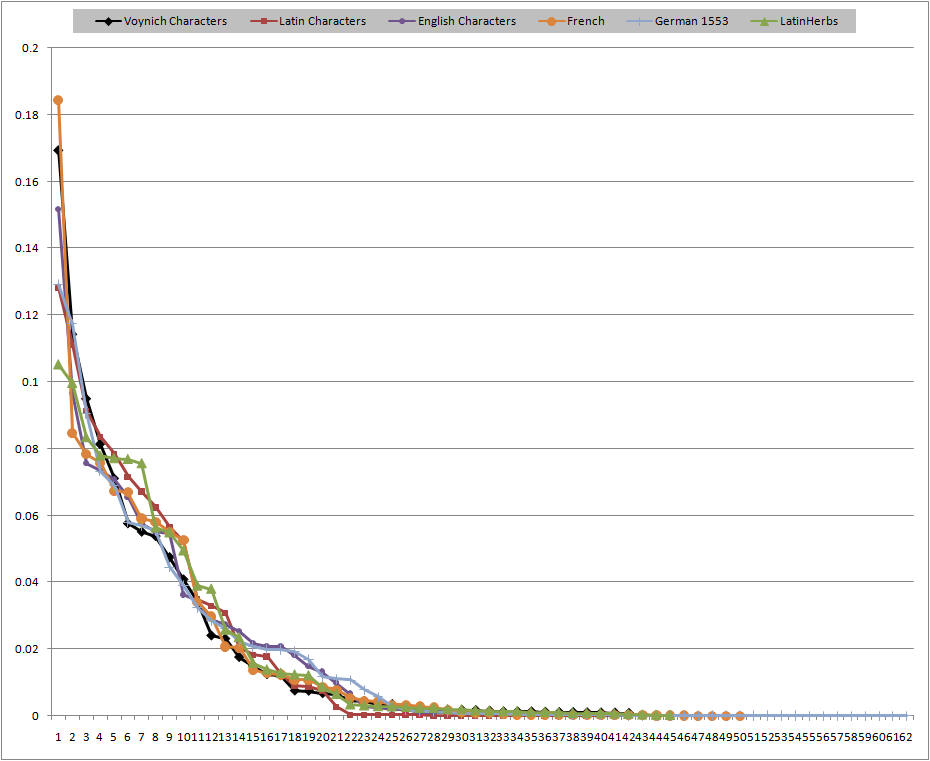
The full distributions are plotted in graphical form. Here is the single character distribution. The leftmost points correspond to the top row of the middle table above.
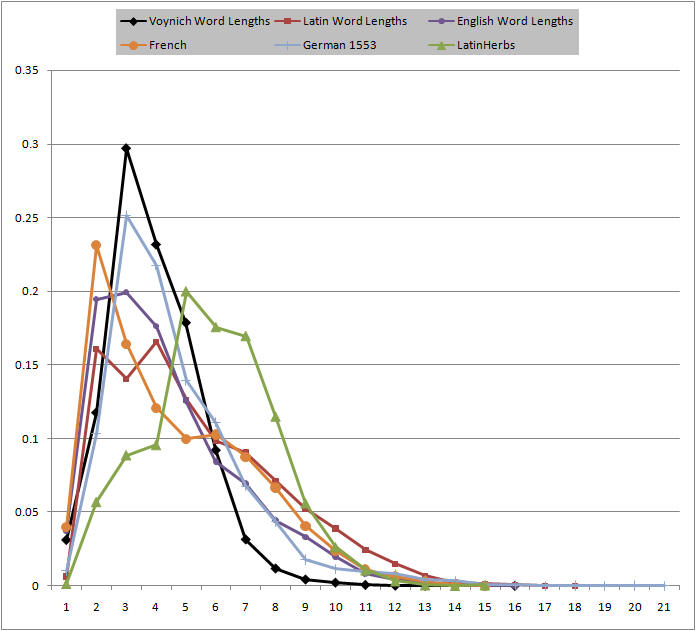
Here is the word length distribution. (Note the striking similarity between mediaeval German and Voynich.)
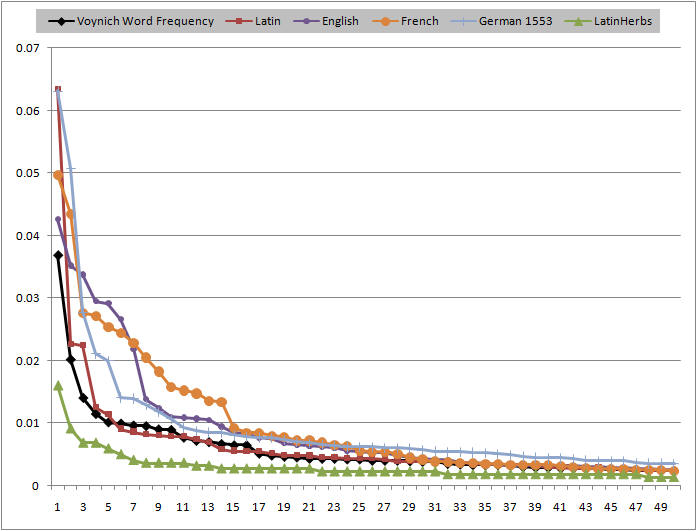
Here is the frequency of the appearance of words. Note that the Latin Herbs (a specialized text) has a similar shape to the Voynich Herbal.
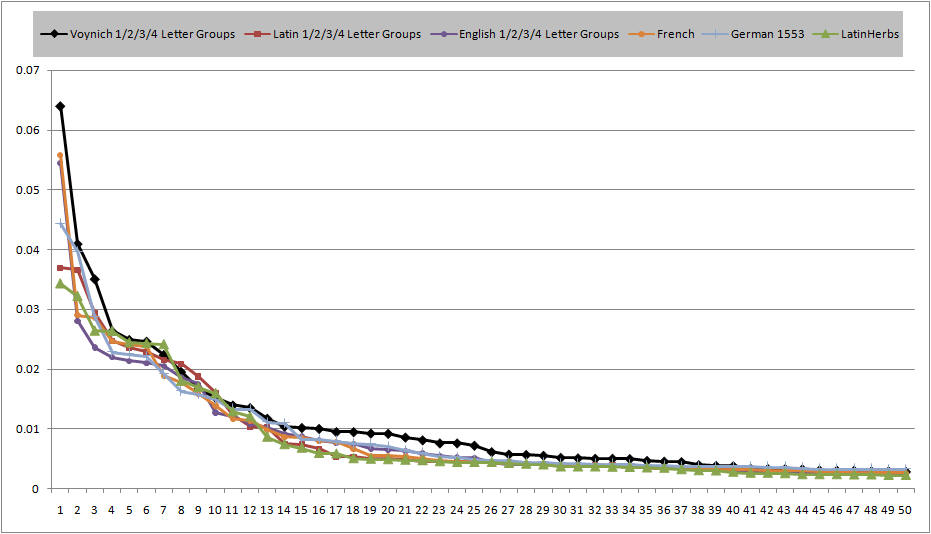
Here is the 1/2/3/4 letter group frequency plot.
See also: Comparison of "Voyn_101" and "PagesH" Transcriptions
Armed with the character analysis above, the following cipher presents itself as a possibility: in the plaintext, convert each group of 1, 2, 3 or 4 characters into a Voynich group of 1,2,3 or 4 characters. We call this a "mapping". For example, referring to the tables above, when creating Voynich from Latin, an obvious cipher just based on the frequencies of the groups would be:
e => o, i => 9, ...
er => 4o, is => ok, ti => 8a, ...
ent => 9k, ant => A, ...
This can be encoded into an algorithm thus which maps strings in "repl" to strings in "seek"
String seek[] = {"4ok1",
"4oh","8am","1oe","4ok","ok1","o89","1oy","oh1","o8a","oha","ohc","c89","1co","k1o","1c9",
"c79","h1o","1o8","oko","oho","coe","8ae","co8","k19","h19","8ay","ham","hcc","koe","oka",
"hco",
"1o", "oe", "oh", "4o", "ok", "8a", "89", "am", "1c", "oy", "o8", "co", "ay",
"k1", "h1", "19", "hc", "c9", "ha", "ae", "79", "2o", "cc", "ko", "ho", "c8", "9h",
"9k", "c7", "2c", "ka", "kc", "1a", "an", "h9", "o,", "e8", "k9", "ap", "8o", "e,",
",1", "7a", "81",
"o", "9", "1", "a", "8", "c", "h", "e", "k", "y", "4", "m", ",",
"2", "7", "s", "K", "C", "p", "g", "n", "H", "j", "A"};
//Latin
String repl[] = {"un",
"ri", "on", "f", "es", "g", "em", "de", "se", "co", "ne", "ur", "si", "ic", "ui", "me",
"ere","eb", "la", "ma", "le", "id", "bu", "nti","no", "cu", "eba","qui","ie", "al", "ul",
"ns",
"c", "d", "l", "er", "is", "ti", "nt", "en", "re", "in", "um", "am", "us",
"te", "it", "v", "tu", "ta", "ra", "di", "an", "ni", "li", "et", "ba", "ae", "mi",
"ent","st", "h", "nd", "ci", "pe", "im", "ua", "io", "tur","il", "ve", "iu", "as",
"vi", "ita","ca",
"e", "i", "a", "t", "u", "s", "r", "n", "m", "o", "p", "b", "q",
"qu", "at", "or", "ia", "ar", "ce", "ib", "ec", "ab", "ru", "ant"};
Such an algorithm is used inside a Chromosome of the Genetic Algorithm. The Chromosome decodes Voynich into Latin by matching character groups in the Voynich word against each of the strings in the "seek" list in turn. If a match occurs, then the Voynich group is translated into the Latin group in the "repl" list at the same position. Thus "4ok1" in Voynich is translated into "un" in Latin.
Once the Voynich word has been translated into Latin, the Latin word is looked up in a Latin dictionary. If the word is found, then the "cost" of the Chromosome is increased ... if the word is not found, then the cost is decreased. After all words in the Voynich text have been converted to Latin, and the aggregate cost of the Chromosome evaluated, it can be judged whether the mapping "seek" to "repl" is a good one or not.
We generate a large number of Chromosomes, each of which has a different "seek" to "repl" mapping. We do this by simply shuffling the order of the "repl" strings in each Chromosome.
Thus, one Chromosome may map "4ok1" to "s" and another may map it to "qui".
This population of Chromosomes is then evaluated: each Chromosome converts the Voynich words to Latin, and each then gets a cost. The higher the cost, the better. The highest possible cost would be a Chromosome that had a seek-repl mapping that produced a valid Latin word for each Voynich word.
The Chromosomes are ordered in decreasing cost, and then the best of them (i.e. at the top of the list) are "mated" together to produce offspring Chromosomes. The mating process essentially involves taking sequences of the "repl" strings from both parents and combining them to form a new "repl" string.
Some of the offspring Chromosomes are then "mutated". This involves replacing one of the "repl" strings with some randomly selected letters from the Latin character set.
The process repeats (ordering the Chromosomes, mating the best ones, mutating the offspring) until a predefined cost value is reached, or the population of Chromosomes refuses to improve itself.
In the end, the best, trained Chromosome will contain the optimal arrangement of "seek" to "repl" mappings for conversion of Voynich to Latin.
The same procedure can be used for a Voynich to English, to German, French or any other language, provided that a dictionary and substantial texts are available to process.
This is a limited attack on the first five "sentences" of f1r, using 200
chromosomes and a Latin dictionary of around 15,000 words. The best chromosome
scores 9.4 after 500 training epochs (cf a score of 20
for a one-to-one translation of Latin into Latin).
Here are the deciphered sentences:
1) Voynich: fa19s 9hae ay Akam
2oe !oy9 �scs 9 hoy 2oe89 soy9 Hay oy9 hacy 1kam 2ay Ais Kay Kay 8aN s9aIy 2ch9
oy 9ham +o8 Koay9 Kcs 8ayam s9 8om okcc9 okcoy yoeok9 ?Aay 8am oham oy ohaN saz9
1cay Kam Jay Fam 98ayai29
Latin: ?ereieas vias is asasita
meas ?ereis ?astuas is quinti mensis asereis vis ereis sttunti viasita viis
as?as alis alis qui? asisere? nti quere ere viis ?ita alamisis altuas ereis asis
quiita quantis querenti ntiviquis ?asis qui amita ere am? asere?is viis alis ?is
?is isereere?viis
2) Voynich: � o8ay ? !oe Go9
o98ay !?s Foam #o8ay9 9+c9 2o89 oh1o9 ok1oe 1oK9 os19 8an 1oy hos 8am 2os Foe
2o89 8an oy kco8(
Latin: ? quinti ? ?vi ?amis
amisere ??as ?amis ?quintiis is?ere meam famis quas qualis amasie quid ere quias
qui meas ?vi meam quid ere a ntita?
3) Voynich: � 98an Gcsam oes Gc9
9kan 2o29 Jo8ae cs oh2o h2o9 okazn okcoe ohaN 2o8an sv19 8am 2o9 Hc9 ho8am G9
Jo8aIes L9 2o oe7an 7 8an om 1 oe o8am 1o8an 189 ohan 7aN K9 ho8 8am 2Hc9 Hoy
1ay 3c9 hoe1oe 1oe hoy 1ae 3o 1oe 2o8aN h+9 h1e 8oy 1o8am 2o hccap 91o k1c9
1chan +cog2oe 89898 K9 8ai�9 (ko 3oe 3c ho82c9 Jcae9 8ay an 8an H98s 81ay +Kam
ohaZ1c9 �19 �koe Koes 8aoEko 2oh 1oy 1c9 8an Hc9 okoe 8aM
Latin: ? isquid ?tuasis vias ?ere
quis meviis ?quias tuas eme asmeis no?d quere am? mequid as?ie qui meis vere
quiqui ?is ?qui?asas ?isme vitad ere quid amita ere quiita alis viam amd ta?
alis quis qui vivere vere quinti ?ere quiasere ere quinti quias ?am ere mequi?
as?is cas quinti alis me quere isqu vere vistd ?ereasmeas amams alis qui??is ?at
?vi ?tu quisquis ?tuasis ere is quid vissas quis ?alis am?qui ?ie ?as alvias
quiam?at meas ere qui quid vere amas qui?
4) Voynich: Go 2am !oh1C9 1oe
k2o8ccs9 2c9 g98C9 19 yo 8ay (7an 1oe 8an Kae 8ay +cay ham 8ay 5c9 Kay 1o?o ham
2oam ohoe 8am ?ay Koe 8am Koe8ay 91C9 ohC9 oh9 8am oh1c9 hoham o?1oe hA719 8ae
81co 2o89 ho?19 K9 oh1c9 hcc9 hcc9 8ae 1koy 2o? 1oe 1H1ok9 1okc9 81am
Latin: ?am viis ?fnsis ere
atmesantasis quis asissnsis ie ntiam ere ?tad ere quid alas ere ?tuis qui ere
?ere alis qu?am qui meis quas qui ?is alvi qui alruis isvinsis ensis eis qui
fere quiqui am?ere asasereie qui quere meam qui?ie alis fere quis quis qui
viatnti me? ere vivquat quantis quis
5) Voynich: h1s9 1o8am oe oek1c9
1ay Fax ap 9kcc9 1ay oy o19 81o eho89 oho8ay 1o89 8o H9 HoH9 59 8h3C9 K9 hok1o89
8ae 8oe 1ohco 8az 8ap so1c9 1o ho89
Latin: casis alis vi vivere
quinti ?ere? ere quantis quinti ere amie quam asquiam quere alis qui vis vamvis
?is sas?nsis alis quiquam qui quias quere qui? quin asamqui qu quiam
Here is a "translation" from Latin to English (chromsome
cost ~5)
Latin: Magnus es, domine, et
laudabilis valde: magna virtus tua, et sapientiae tuae non est numerus. et
laudare te vult homo, aliqua portio creaturae tuae, et homo circumferens
mortalitem suam, circumferens testimonium peccati sui et testimonium, quia
superbis resi stis: et tamen laudare te vult homo, aliqua portio creaturae
tuae.tu excitas, ut laudare te delectet, quia fecisti nos ad te et in
quietum est cor nostrum, donec requiescat in te. da mihi, domine, scire
et intellegere, utrum sit prius invocare te an laudare te,
et scire te prius sit an invocare te. sed quis te invocat nesciens te? aliud
enim pro alio potest invocare nesciens. an potius in
vocaris, ut sciaris? quomodo autem invocabunt, in quem non crediderunt? aut
quomodo credent sine praedicante? et laudabunt dominum
qui requirunt eum. quaerentes enim inveniunt eum et invenientes laudabunt eum.
quaeram te, domine, invocans te, et invocem te cre
dens in te: praedicatus enim es nobis. invocat te, domine, fides mea, quam
dedisti mihi, quam inspirasti mihi per humanitatem fili
i tui, per ministerium praedicatoris tui.
English: ?seouething be? seneenbe?
her ngehaseatkese srabe? riouethse hathethese these? her sesestoudeeth theeth
teeth bend ethingsing? her ngehaseras and sound rnesne? rasesese stssrane
ingyengendeth theeth? her rnesne eltheelsoutide ssstheethands seets?
eltheelsoutide andtheethiis haingyera seeth her andtheethiis? these sehahatheise
yeyethese? her thetheeth ngehaseras and sound rnesne? rasesese stssrane
ingyengendeth theeth?the s?elthese? hand ngehaseras and bevingandnd? these
oungesera tese sese and her herthehering bend hathe tethedes? seinge yethebeyend
her and? sese enrse? seneenbe? seelye her herandsevouti? handdes yend staing
hersneyeye and the ngehaseras and? her seelye and staing yend the hersneyeye
and? these these and hersneyend beseeltese and? raise teeth sttheneraou
stneandthe hersneyeye beseeltese? the stneraing hersneyease? hand seelrase?
senesnesene sehaands hersneyeouv? her seeth teeth ingyesebedev? sehand
senesnesene ingyebev yebe stndsseyevs? her ngehaseatsend seneenething the
yethedev sing? seethyevbe teeth herndmasend sing her herndmavbe ngehaseatsend
sing? seethnds and? seneenbe? hersneyede and? her hersnenges and ingyebede her
and? stndsseyethese teeth be teise? hersneyend and? seneenbe? ouvebe these?
seeth besethese enrse? seeth hersestsendthese enrse hathe ringthengeands
oukesese these? hathe enmathesis stndsseyendssse these?
I'm still digesting these, but some thoughts:
1) The size of the Dictionary used for training is important
2) Opinion: the translation Latin->English looks less plausible than the Voynich->Latin
3) After training, the solution found is just one solution - not necessarily the
optimum solution (there may be many local minima).
4) Running the GA several times with the same input parameters yields different
translations
5) The cost function only uses a dictionary lookup, but should perhaps
penalise chromosomes that have multiple Voynich n-grams that map to the
same Latin n-gram. E.g. if all Voynich n-grams mapped to "qui" then
the chromosome would score very highly, but produce repetitious nonsense.
Here are some thought-provoking results from looking at Landini's challenge text, as suggested by Knox, the VM text, and comparisons with English, Latin, German, French and Spanish. These use a new form of the Genetic Algorithm, described below.
It looks to me like that Landini either generated his text from a transcription of the VM itself, or his algorithm for generating that text is a good emulation of the encoding process used in the VM. In other words the Landini "language" is a good candidate as a plaintext language for the VM, as opposed to the European languages tested.
Here is a table which shows the GA's efficiency at
converting/translating between Voynich, Landini, and
the other languages.
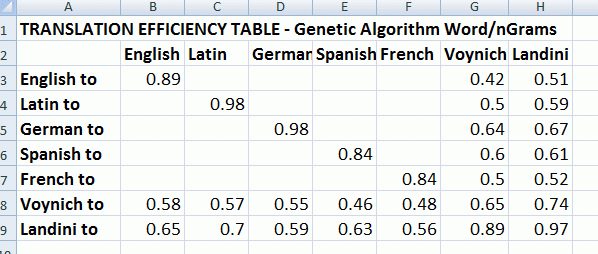
(In the table, the best possible score is 1.0 - see below for an explanation)
Asking the GA to translate English to English, or Latin to Latin, etc. results
in a high efficiency score, as expected. Note that the Landini to Landini
efficiency is 0.97 - almost perfect.
The GA performs moderately at converting between the languages and the Landini
text. But what is most striking (to me) is the good efficiency for
converting Voynich to Landini (0.74) and Landini to Voynich (0.89)
To look at this I revised my GA code so that it was
more flexible, and I jettisoned the use of separate dictionaries. Here is how
the GA now functions. It can convert/translate between any language text
samples.
1) Two text files are read in: the "source" text, and the "target" text.
This could be, for example, a source file containing Landini's text, and
a target file containing Spanish text, if we want to convert from Landini to
Spanish.
2) The text in each file is processed separately, producing two word lists, and
two sets of n-Gram frequency tables.
3) The chromosomes are generated with random mappings between the source n-Grams
and the target n-Grams
4) The GA evolves the chromosomes by trying to maximise their cost. The
difference now is that when a target word is generated
from the source text using the mappings, it is looked up in the target word list
created in 2) above, rather than in a separate
dictionary.
5) After training, the best chromosome can have a maximum cost value of 1.0,
which would correspond to a perfect conversion between the source text and the
target
text (i.e. every word produced from the source text is found in the target
text dictionary)
6) So we can feed the GA with two identical texts, and after training the score
of the best chromosome should be 1.0, and indeed it approaches that (it doesn't
quite
get there because only the top 100 n-Grams are translated, and so some
characters in the source text cannot be translated).
7) The word and n-Gram frequency lists are made
from the entirety of each text, but (for this exploratory study) the training
takes place on only the first 50 "words" in the source text, and uses
only the first 100 n-Grams for mapping. Thus
if the 50 words of Voynich chosen contain several rare characters, then for
those the mapping will fail because those rare characters
do not appear in the n-Gram list, and this will result in a lower score.
8) In all cases the "X->X" score in the table (i.e.
the diagonal) represents the best score possible
for that language, and is a normalisation for the other numbers in the table. I
should really revise the table and divide out the
off-diagonal scores by the diagonal normalisations.
9) An improvement would be to configure the n-Gram
list to be, say, 200 long, and use more source (Voynich) words for the training.
The downside of this is mainly execution speed.
10) These runs were with n-Grams up to 3: it would be
better to go to 4 at least.
11) I think Landini gets good scores because the
character set he uses is very small. Knox comments " A
factor must be that the Landini Challenge has built-in frequency matches to any
transcription of the VMs. Also, there is no meaningful correspondence in the
letter sequence of one word to another in Landini. The difficulty fits what I
said the VMs may be."
Here are the letter frequencies for the whole of the VM, in the Voyn_101 encoding
| Rank | Letter | Counts | Frequency |
| 1 | o | 25055 | 1.58E-01 |
| 2 | 9 | 17441 | 1.10E-01 |
| 3 | a | 14499 | 9.12E-02 |
| 4 | c | 13751 | 8.65E-02 |
| 5 | 1 | 11059 | 6.96E-02 |
| 6 | e | 10658 | 6.70E-02 |
| 7 | 8 | 10349 | 6.51E-02 |
| 8 | h | 9926 | 6.24E-02 |
| 9 | y | 6718 | 4.23E-02 |
| 10 | k | 6120 | 3.85E-02 |
| 11 | 4 | 5411 | 3.40E-02 |
| 12 | m | 4112 | 2.59E-02 |
| 13 | 2 | 3362 | 2.11E-02 |
| 14 | C | 2844 | 1.79E-02 |
| 15 | 7 | 2718 | 1.71E-02 |
| 16 | s | 2705 | 1.70E-02 |
| 17 | n | 1766 | 1.11E-02 |
| 18 | p | 989 | 6.22E-03 |
| 19 | K | 910 | 5.72E-03 |
| 20 | g | 879 | 5.53E-03 |
| 21 | H | 866 | 5.45E-03 |
| 22 | A | 769 | 4.84E-03 |
| 23 | j | 564 | 3.55E-03 |
| 24 | 3 | 519 | 3.26E-03 |
| 25 | z | 511 | 3.21E-03 |
| 26 | 5 | 412 | 2.59E-03 |
| 27 | ( | 402 | 2.53E-03 |
| 28 | d | 336 | 2.11E-03 |
| 29 | i | 264 | 1.66E-03 |
| 30 | f | 233 | 1.47E-03 |
| 31 | u | 177 | 1.11E-03 |
| 32 | M | 174 | 1.09E-03 |
| 33 | * | 164 | 1.03E-03 |
| 34 | Z | 154 | 9.69E-04 |
| 35 | % | 140 | 8.80E-04 |
| 36 | N | 132 | 8.30E-04 |
| 37 | J | 122 | 7.67E-04 |
| 38 | 6 | 118 | 7.42E-04 |
| 39 | I | 98 | 6.16E-04 |
| 40 | x | 98 | 6.16E-04 |
| 41 | ? | 96 | 6.04E-04 |
| 42 | + | 95 | 5.97E-04 |
| 43 | W | 92 | 5.79E-04 |
| 44 | G | 89 | 5.60E-04 |
| 45 | Y | 55 | 3.46E-04 |
| 46 | E | 54 | 3.40E-04 |
| 47 | ! | 50 | 3.14E-04 |
| 48 | l | 40 | 2.52E-04 |
| 49 | t | 40 | 2.52E-04 |
| 50 | P | 38 | 2.39E-04 |
| 51 | S | 38 | 2.39E-04 |
| 52 | & | 36 | 2.26E-04 |
| 53 | F | 35 | 2.20E-04 |
| 54 | # | 34 | 2.14E-04 |
| 55 | L | 32 | 2.01E-04 |
| 56 | U | 32 | 2.01E-04 |
| 57 | b | 30 | 1.89E-04 |
| 58 | � | 30 | 1.89E-04 |
| 59 | Q | 27 | 1.70E-04 |
| 60 | T | 27 | 1.70E-04 |
| 61 | | | 25 | 1.57E-04 |
| 62 | $ | 24 | 1.51E-04 |
| 63 | w | 24 | 1.51E-04 |
| 64 | V | 23 | 1.45E-04 |
| 65 | \ | 17 | 1.07E-04 |
| 66 | X | 14 | 8.80E-05 |
| 67 | r | 12 | 7.55E-05 |
| 68 | R | 11 | 6.92E-05 |
| 69 | q | 11 | 6.92E-05 |
| 70 | � | 11 | 6.92E-05 |
| 71 | D | 10 | 6.29E-05 |
| 72 | v | 10 | 6.29E-05 |
| 73 | � | 10 | 6.29E-05 |
| 74 | � | 10 | 6.29E-05 |
| 75 | � | 10 | 6.29E-05 |
| 76 | � | 10 | 6.29E-05 |
| 77 | � | 9 | 5.66E-05 |
| 78 | ^ | 8 | 5.03E-05 |
| 79 | � | 8 | 5.03E-05 |
| 80 | � | 8 | 5.03E-05 |
| 81 | � | 8 | 5.03E-05 |
| 82 | � | 8 | 5.03E-05 |
| 83 | � | 7 | 4.40E-05 |
| 84 | � | 7 | 4.40E-05 |
| 85 | � | 7 | 4.40E-05 |
| 86 | B | 6 | 3.77E-05 |
| 87 | � | 6 | 3.77E-05 |
| 88 | � | 6 | 3.77E-05 |
| 89 | � | 6 | 3.77E-05 |
| 90 | � | 6 | 3.77E-05 |
| 91 | � | 6 | 3.77E-05 |
| 92 | � | 6 | 3.77E-05 |
| 93 | � | 5 | 3.14E-05 |
| 94 | � | 5 | 3.14E-05 |
| 95 | � | 5 | 3.14E-05 |
| 96 | � | 5 | 3.14E-05 |
| 97 | � | 5 | 3.14E-05 |
| 98 | � | 5 | 3.14E-05 |
| 99 | � | 5 | 3.14E-05 |
| 100 | � | 4 | 2.52E-05 |
| 101 | � | 4 | 2.52E-05 |
| 102 | � | 4 | 2.52E-05 |
| 103 | � | 4 | 2.52E-05 |
| 104 | � | 4 | 2.52E-05 |
| 105 | � | 4 | 2.52E-05 |
| 106 | � | 4 | 2.52E-05 |
| 107 | � | 4 | 2.52E-05 |
| 108 | � | 3 | 1.89E-05 |
| 109 | � | 3 | 1.89E-05 |
| 110 | � | 3 | 1.89E-05 |
| 111 | � | 3 | 1.89E-05 |
| 112 | � | 3 | 1.89E-05 |
| 113 | � | 3 | 1.89E-05 |
| 114 | � | 3 | 1.89E-05 |
| 115 | � | 3 | 1.89E-05 |
| 116 | � | 3 | 1.89E-05 |
| 117 | 0 | 2 | 1.26E-05 |
| 118 | _ | 2 | 1.26E-05 |
| 119 | � | 2 | 1.26E-05 |
| 120 | � | 2 | 1.26E-05 |
| 121 | � | 2 | 1.26E-05 |
| 122 | � | 2 | 1.26E-05 |
| 123 | � | 2 | 1.26E-05 |
| 124 | � | 2 | 1.26E-05 |
| 125 | � | 2 | 1.26E-05 |
| 126 | � | 2 | 1.26E-05 |
| 127 | � | 2 | 1.26E-05 |
| 128 | � | 2 | 1.26E-05 |
| 129 | � | 2 | 1.26E-05 |
| 130 | � | 2 | 1.26E-05 |
| 131 | � | 2 | 1.26E-05 |
| 132 | � | 2 | 1.26E-05 |
| 133 | � | 1 | 6.29E-06 |
| 134 | � | 1 | 6.29E-06 |
| 135 | � | 1 | 6.29E-06 |
| 136 | � | 1 | 6.29E-06 |
| 137 | � | 1 | 6.29E-06 |
| 138 | � | 1 | 6.29E-06 |
| 139 | � | 1 | 6.29E-06 |
| 140 | � | 1 | 6.29E-06 |
| 141 | � | 1 | 6.29E-06 |
| 142 | � | 1 | 6.29E-06 |
| 143 | � | 1 | 6.29E-06 |
| 144 | � | 1 | 6.29E-06 |
| 145 | � | 1 | 6.29E-06 |
| 146 | � | 1 | 6.29E-06 |
| 147 | � | 1 | 6.29E-06 |
| 148 | � | 1 | 6.29E-06 |
| 149 | � | 1 | 6.29E-06 |
| 150 | � | 1 | 6.29E-06 |
| 151 | � | 1 | 6.29E-06 |
| 152 | � | 1 | 6.29E-06 |
| 153 | � | 1 | 6.29E-06 |
| 154 | � | 1 | 6.29E-06 |
| 155 | � | 1 | 6.29E-06 |
| 156 | � | 1 | 6.29E-06 |
| 157 | � | 1 | 6.29E-06 |
| 158 | � | 1 | 6.29E-06 |
| 159 | � | 1 | 6.29E-06 |
| 160 | � | 1 | 6.29E-06 |
| 161 | � | 1 | 6.29E-06 |
| 162 | � | 1 | 6.29E-06 |
| 163 | � | 1 | 6.29E-06 |
| 164 | � | 1 | 6.29E-06 |
| 165 | � | 1 | 6.29E-06 |
| 166 | � | 1 | 6.29E-06 |
| 167 | � | 1 | 6.29E-06 |
| 168 | � | 1 | 6.29E-06 |
| 169 | � | 1 | 6.29E-06 |
| 170 | � | 1 | 6.29E-06 |
| 171 | � | 1 | 6.29E-06 |
| 172 | � | 1 | 6.29E-06 |
Here are the word length frequency counts
| Word Length | Count | Frequency |
| 1 | 1096 | 0.028637124 |
| 2 | 4069 | 0.10631794 |
| 3 | 8412 | 0.21979515 |
| 4 | 9354 | 0.24440844 |
| 5 | 8425 | 0.22013482 |
| 6 | 4489 | 0.11729202 |
| 7 | 1721 | 0.0449676 |
| 8 | 471 | 0.012306647 |
| 9 | 155 | 0.004049958 |
| 10 | 52 | 0.001358696 |
| 11 | 13 | 3.40E-04 |
| 12 | 10 | 2.61E-04 |
| 13 | 3 | 7.84E-05 |
| 14 | 2 | 5.23E-05 |
The most frequent words
| Rank | Word | Count | Frequency |
| 1 | 8am | 704 | 0.018394649 |
| 2 | oe | 569 | 0.014867266 |
| 3 | am | 511 | 0.013351798 |
| 4 | ay | 391 | 0.010216346 |
| 5 | oy | 373 | 0.009746028 |
| 6 | 1oe | 354 | 0.009249582 |
| 7 | 1c9 | 333 | 0.008700878 |
| 8 | 1c89 | 332 | 0.008674749 |
| 9 | s | 295 | 0.007707985 |
| 10 | 4ohan | 277 | 0.007237667 |
| 11 | 8ay | 273 | 0.007133152 |
| 12 | ae | 265 | 0.006924122 |
| 13 | 4oham | 248 | 0.006479933 |
| 14 | 4ohC9 | 236 | 0.006166388 |
| 15 | 1oy | 206 | 0.005382525 |
| 16 | 2c89 | 202 | 0.00527801 |
| 17 | oham | 198 | 0.005173495 |
| 18 | 89 | 192 | 0.005016722 |
| 19 | 8ae | 187 | 0.004886079 |
| 20 | 2c9 | 183 | 0.004781564 |
| 21 | 4ohae | 182 | 0.004755435 |
| 22 | 8an | 174 | 0.004546405 |
| 23 | 4ohc89 | 171 | 0.004468018 |
| 24 | 1c79 | 166 | 0.004337375 |
| 25 | 9 | 160 | 0.004180602 |
| 26 | 1coe | 157 | 0.004102216 |
| 27 | 19 | 150 | 0.003919315 |
| 28 | y | 150 | 0.003919315 |
| 29 | ohae | 149 | 0.003893186 |
| 30 | okam | 149 | 0.003893186 |
| 31 | 4oe | 144 | 0.003762542 |
| 32 | okay | 142 | 0.003710284 |
| 33 | 4ohay | 141 | 0.003684155 |
| 34 | 4ohC89 | 141 | 0.003684155 |
| 35 | 2oe | 135 | 0.003527383 |
| 36 | 1H9 | 132 | 0.003448997 |
| 37 | 4oh9 | 132 | 0.003448997 |
| 38 | okae | 131 | 0.003422868 |
| 39 | ohan | 130 | 0.003396739 |
| 40 | ohay | 124 | 0.003239967 |
| 41 | sam | 120 | 0.003135452 |
| 42 | an | 119 | 0.003109323 |
| 43 | ohC9 | 114 | 0.002978679 |
| 44 | ok9 | 113 | 0.00295255 |
| 45 | e | 112 | 0.002926421 |
| 46 | 7am | 105 | 0.00274352 |
| 47 | 189 | 101 | 0.002639005 |
| 48 | 1C9 | 101 | 0.002639005 |
| 49 | oh9 | 100 | 0.002612876 |
| 50 | 4ohc9 | 99 | 0.002586748 |
Here is the 1/2/3/4 nGram frequency for the whole VM, showing only the top 100
| Rank | nGram | Counts | Frequency |
| 1 | o | 96575 | 0.058597673 |
| 2 | 9 | 64626 | 0.039212354 |
| 3 | c | 58862 | 0.035715003 |
| 4 | a | 48135 | 0.029206306 |
| 5 | h | 40911 | 0.024823084 |
| 6 | 1 | 40709 | 0.024700519 |
| 7 | 8 | 39703 | 0.02409012 |
| 8 | e | 37842 | 0.022960944 |
| 9 | oh | 25419 | 0.015423186 |
| 10 | k | 24626 | 0.014942028 |
| 11 | 4 | 23615 | 0.014328594 |
| 12 | 4o | 23113 | 0.014024003 |
| 13 | y | 21208 | 0.012868128 |
| 14 | 89 | 20822 | 0.012633919 |
| 15 | oe | 19757 | 0.011987722 |
| 16 | 1c | 18455 | 0.011197723 |
| 17 | ok | 16526 | 0.010027286 |
| 18 | 4oh | 13820 | 0.008385398 |
| 19 | co | 13222 | 0.008022557 |
| 20 | c8 | 12984 | 0.007878148 |
| 21 | hc | 12020 | 0.007293234 |
| 22 | ae | 11891 | 0.007214962 |
| 23 | m | 11833 | 0.00717977 |
| 24 | 8a | 11636 | 0.007060238 |
| 25 | 2 | 11192 | 0.006790838 |
| 26 | am | 11136 | 0.006756859 |
| 27 | ha | 11119 | 0.006746545 |
| 28 | ay | 11044 | 0.006701037 |
| 29 | C | 11027 | 0.006690722 |
| 30 | 7 | 10911 | 0.006620339 |
| 31 | c89 | 10128 | 0.006145247 |
| 32 | c9 | 9422 | 0.005716876 |
| 33 | 1o | 9387 | 0.005695639 |
| 34 | o8 | 9021 | 0.005473566 |
| 35 | cc | 8475 | 0.005142276 |
| 36 | s | 8212 | 0.004982698 |
| 37 | oy | 7839 | 0.004756378 |
| 38 | ohc | 7823 | 0.004746669 |
| 39 | 79 | 7477 | 0.004536731 |
| 40 | oha | 7256 | 0.004402638 |
| 41 | kc | 6670 | 0.004047077 |
| 42 | 2c | 5996 | 0.003638122 |
| 43 | n | 5830 | 0.0035374 |
| 44 | hC | 5729 | 0.003476118 |
| 45 | ka | 5717 | 0.003468837 |
| 46 | an | 5695 | 0.003455488 |
| 47 | c7 | 5508 | 0.003342024 |
| 48 | 4ok | 5242 | 0.003180627 |
| 49 | eh | 5043 | 0.003059882 |
| 50 | okc | 4819 | 0.002923968 |
| 51 | 1c8 | 4775 | 0.002897271 |
| 52 | c79 | 4448 | 0.00269886 |
| 53 | h1 | 4431 | 0.002688546 |
| 54 | 1co | 4396 | 0.002667309 |
| 55 | k1 | 4357 | 0.002643646 |
| 56 | o89 | 4247 | 0.002576902 |
| 57 | 4ohc | 4161 | 0.002524721 |
| 58 | oka | 4152 | 0.00251926 |
| 59 | C9 | 4077 | 0.002473753 |
| 60 | 4oha | 4053 | 0.002459191 |
| 61 | g | 4011 | 0.002433707 |
| 62 | hcc | 3712 | 0.002252287 |
| 63 | coe | 3707 | 0.002249253 |
| 64 | ohC | 3697 | 0.002243185 |
| 65 | co8 | 3575 | 0.002169161 |
| 66 | 1c89 | 3573 | 0.002167947 |
| 67 | 8am | 3520 | 0.002135789 |
| 68 | 19 | 3447 | 0.002091496 |
| 69 | p | 3320 | 0.002014437 |
| 70 | e1 | 3300 | 0.002002302 |
| 71 | 9h | 3283 | 0.001991987 |
| 72 | o8a | 3178 | 0.001928278 |
| 73 | 1c9 | 3036 | 0.001842118 |
| 74 | ko | 3030 | 0.001838477 |
| 75 | ho | 2950 | 0.001789937 |
| 76 | oeh | 2895 | 0.001756565 |
| 77 | hco | 2784 | 0.001689215 |
| 78 | 1oe | 2679 | 0.001625505 |
| 79 | C8 | 2670 | 0.001620044 |
| 80 | ham | 2660 | 0.001613977 |
| 81 | hae | 2647 | 0.001606089 |
| 82 | ok1 | 2625 | 0.00159274 |
| 83 | j | 2624 | 0.001592134 |
| 84 | 9k | 2619 | 0.0015891 |
| 85 | A | 2601 | 0.001578178 |
| 86 | ya | 2577 | 0.001563616 |
| 87 | ap | 2567 | 0.001557548 |
| 88 | H | 2552 | 0.001548447 |
| 89 | 4ohC | 2503 | 0.001518716 |
| 90 | oh1 | 2496 | 0.001514469 |
| 91 | 7a | 2490 | 0.001510828 |
| 92 | 8ae | 2487 | 0.001509008 |
| 93 | 8ay | 2471 | 0.0014993 |
| 94 | han | 2399 | 0.001455613 |
| 95 | K | 2394 | 0.001452579 |
| 96 | h9 | 2367 | 0.001436197 |
| 97 | cc8 | 2359 | 0.001431343 |
| 98 | 2o | 2357 | 0.001430129 |
| 99 | 18 | 2329 | 0.00141314 |
| 100 | eo | 2225 | 0.001350037 |
Jan Hurych's VM Letter Frequency Analysis
http://hurontaria.baf.cz/CVM/b2.htm
Voynich Transcription
http://voynichcentral.com/transcriptions/Voynich-101/index.htmlBook of Courtier (1561)
http://www.uoregon.edu/~rbear/courtier/courtier.htmlAugustinus Confessiones
http://ccat.sas.upenn.edu/jod/latinconf/1367 French
http://www.ucc.ie/celt/published/F300001-001/index.htmlLatin garden description
http://www.uni-duisburg.de/Institute/CollCart/hortus/strabo/HB-ceref.htmSabina Welserin Cookbook (German, c 1553)
http://www.uni-giessen.de/gloning/tx/sawe.htmLatin scribal abbreviations
http://www.ualberta.ca/~sreimer/ms-course/course/abbrevtn.htmMediaeval english herb names
http://www.gardenhistoryinfo.com/medieval/medievalherbs.htmlMartin Luther Bible
http://quod.lib.umich.edu/cgi/l/luther/luther-idx?type=DIV2&byte=2160